
RStan を利用して 一般化線形モデル(誤差構造=ガンマ分布,リンク関数=対数関数) を試みます。
1. シナリオ設定
タイトル:Eコマースサイトにおける顧客のサイト滞在時間分析
ストーリー: あるEコマースサイトのデータ分析チームは、顧客エンゲージメントの重要な指標である「サイト滞在時間」を伸ばすための施策を検討しています。滞在時間が長い顧客は、商品への関心が高く、購買に至る可能性が高いと考えられているためです。
分析チームは、滞在時間に影響を与えそうな要因として、以下の2つに着目しました。
- 流入経路: 顧客が広告をクリックしてサイトに訪れたのか、それとも自然検索(オーガニック)で訪れたのか。
- 訪問頻度: その顧客が過去に何回サイトを訪れたか(リピート顧客かどうか)。
仮説として、「広告経由の顧客は特定の商品を探しに来るため滞在時間が短く、一方でサイトへの訪問頻度が高い(ファンである)顧客ほど、サイト内を回遊して滞在時間が長くなるのではないか」と考えています。
この仮説を検証するために、以下の変数を収集し、統計モデルを構築して分析することにしました。
- 応答変数 (Y): ユーザーの1セッションあたりのサイト滞在時間(秒)。
- 説明変数1 (X1): 広告経由流入ダミー(1: 広告経由, 0: オーガニック検索)。
- 説明変数2 (X2): 過去1年間のサイト訪問回数。
2. モデルの選択
以下の理由により、このシナリオでは一般化線形モデル(誤差構造:ガンマ分布、リンク関数:対数)を選択します。
応答変数の性質: サイト滞在時間は「秒」で計測されるため、必ず正の値をとる連続変数です。正規分布を仮定する通常の線形モデルでは、予測値が負になる可能性があり不適切です。ガンマ分布は正の値のみをとる確率分布であり、この条件を満たします。
データの分布形状: サイト滞在時間のようなデータは、多くのユーザーが短時間で離脱し、一部の熱心なユーザーが非常に長く滞在する傾向があります。これにより、データの分布は右に長く裾を引く(右に歪んだ)形状になりがちです。ガンマ分布はこのような歪んだ分布を柔軟に表現することができます。
平均と分散の関係: 一般的に、平均滞在時間が長いグループ(例:リピート顧客)は、滞在時間のばらつき(分散)も大きくなる傾向があります(不等分散性)。ガンマ分布を用いたモデルでは、分散が平均の2乗に比例する(
Var(Y) ∝ E[Y]^2)と仮定するため、このような平均が大きいほど分散も大きくなるという関係を自然にモデル化できます。これは分散が一定であると仮定する線形モデルよりも現実的です。解釈のしやすさ(対数リンク関数): 対数リンク関数 (
log(E[Y]) = β0 + β1*X1 + ...) を用いることで、説明変数の効果を乗法的(かけ算)で解釈できます。例えば、広告経由の効果β1が-0.2だった場合、滞在時間の期待値はexp(-0.2) ≈ 0.82倍になる、つまり「約18%減少する」と解釈できます。この「〜倍になる」、「〜%変化する」という解釈は直感的でビジネス上の意思決定に役立ちます。
3. RとRStanによるシミュレーションと分析
以下に、上記のシナリオに沿ったシミュレーションとRStanによるモデリングのコードを示します。
ステップ1: パッケージの読み込みと事前設定
# RStanの読み込み
library(rstan)
stan_output <- "D:/stan_output"
# Stanの並列計算設定
rstan_options(auto_write = TRUE)
options(mc.cores = parallel::detectCores())
# rstan のバージョン確認
cat("--- パッケージ rstan のバージョン確認 ---\n")
sapply(X = c("rstan"), packageVersion)--- パッケージ rstan のバージョン確認 ---
$rstan
[1] 2 32 7ステップ2: シミュレーションデータの生成
シナリオに基づいて、仮の「真のパラメータ」を設定し、データを生成します。
seed <- 20250702
set.seed(seed)
# データ生成
N <- 200 # ユーザー数
# 真のパラメータを設定
beta_0_true <- log(90) # オーガニック流入で訪問回数1回のユーザーの平均滞在時間(秒)の対数 (exp(4.5) ≈ 90秒)
beta_1_true <- -0.4 # 広告経由の効果 (滞在時間が exp(-0.4) ≈ 0.67倍になる)
beta_2_true <- 0.3 # 訪問回数(対数)の効果 (訪問回数が多いほど滞在時間が延びる)
phi_true <- 5 # ガンマ分布の形状パラメータ(shape)。値が大きいほど分散が小さくなる。
# 説明変数の生成
# X1: 広告経由ダミー (0: オーガニック, 1: 広告)
ad_flg <- rbinom(N, 1, 0.4)
# X2: サイト訪問回数 (ポアソン分布で生成し、1回以上とする)
visits <- rpois(N, lambda = 5) + 1
# 線形予測子 eta = log(mu)
eta <- beta_0_true + beta_1_true * ad_flg + beta_2_true * log(visits)
# 平均 mu
mu <- exp(eta)
# 応答変数Y (滞在時間) をガンマ分布から生成
# rate = shape / mean = phi / mu
stay_time <- rgamma(n = N, shape = phi_true, rate = phi_true / mu)
# データフレームにまとめる
sim_data <- data.frame(
stay_time = stay_time,
ad_flg = ad_flg,
visits = visits,
log_visits = log(visits)
)
# 生成したデータの分布を確認
library(ggplot2)
ggplot(sim_data, aes(x = stay_time)) +
geom_histogram(bins = 30, fill = "skyblue", color = "black") +
labs(
title = "シミュレーションで生成した滞在時間の分布",
x = "滞在時間 (秒)", y = "度数"
) +
theme_minimal()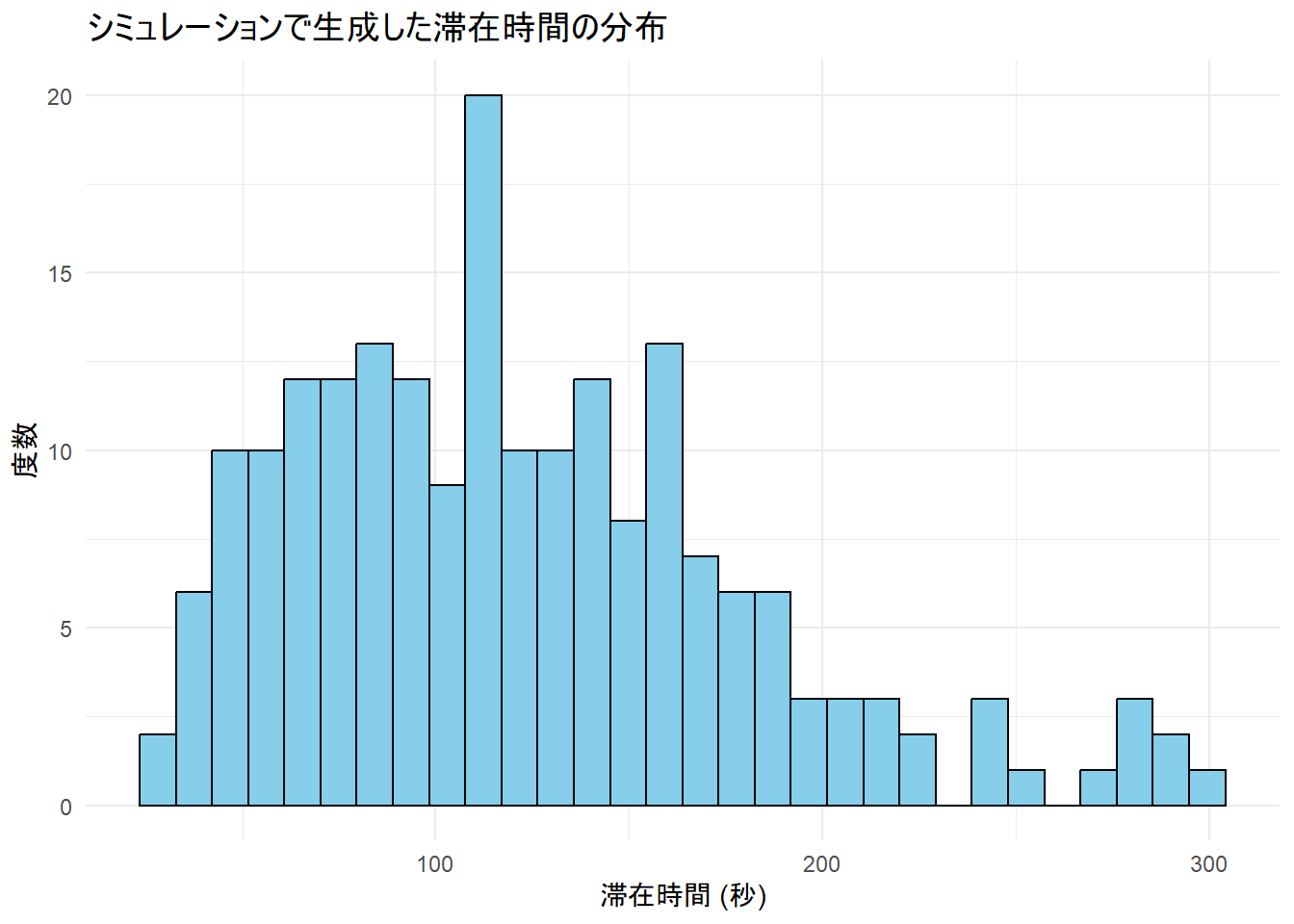
生成された滞在時間の分布は、想定通り右に裾を引く形状になっていることが確認できます。
ステップ3: Stanモデルの記述
ガンマ回帰モデルをStanコードで記述します。
model_code <- "
data {
int<lower=1> N; // データ数
vector<lower=0>[N] y; // 応答変数 (滞在時間)
int<lower=1> K; // 説明変数の数(切片含む)
matrix[N, K] X; // 説明変数行列
}
parameters {
vector[K] beta; // 回帰係数
real<lower=0> phi; // ガンマ分布の形状パラメータ (shape)
}
model {
// 線形予測子
vector[N] mu = exp(X * beta);
// 事前分布
beta ~ normal(0, 10);
phi ~ cauchy(0, 5); // 正の値のみをとる裾の厚い分布
// 尤度: y ~ gamma(shape, rate)
// rate = shape / mean なので、 rate = phi / mu
y ~ gamma(phi, phi ./ mu);
}
generated quantities {
// 事後予測チェック用のデータを生成
vector[N] y_rep;
for (n in 1:N) {
y_rep[n] = gamma_rng(phi, phi / exp(X[n] * beta));
}
}
"ステップ4: Stanの実行と結果の確認
作成したモデルにデータを渡してMCMCを実行します。
# Stanに渡すデータリストを作成
X <- model.matrix(~ ad_flg + log_visits, data = sim_data)
stan_data <- list(
N = nrow(sim_data),
y = sim_data$stay_time,
K = ncol(X),
X = X
)
# Stanモデルのコンパイルと実行
fit <- stan(
model_code = model_code,
data = stan_data,
iter = 2000,
warmup = 1000,
chains = 4,
seed = seed
)
# stanfit オブジェクトの保存
setwd(stan_output)
saveRDS(object = fit, file = "stan_fit.rds")# stanfit オブジェクトの読み込み
setwd(stan_output)
fit <- readRDS("stan_fit.rds")
# 結果の要約
cat("--- 結果の要約 ---\n")
summary(fit,
pars = c("beta", "phi"),
probs = c(0.025, 0.5, 0.975)
)$summary
# 真の値: beta0=4.5, beta1=-0.4, beta2=0.3, phi=5
# トレースプロットで収束を確認
stan_trace(fit, pars = c("beta", "phi"))--- 結果の要約 ---
mean se_mean sd 2.5% 50% 97.5%
beta[1] 4.3252397 0.002950195 0.11530583 4.1021358 4.3228069 4.5535099
beta[2] -0.3170937 0.001169330 0.06057089 -0.4345920 -0.3184224 -0.1978908
beta[3] 0.3624102 0.001693970 0.06503688 0.2346421 0.3636149 0.4875294
phi 5.5526018 0.010686742 0.53505548 4.5623793 5.5241157 6.6534689
n_eff Rhat
beta[1] 1527.570 0.9995931
beta[2] 2683.203 1.0015396
beta[3] 1474.035 1.0001190
phi 2506.727 1.0024376
stanコード実行の結果、警告メッセージ は出されず、Rhatが全て1に近く、n_effも十分に大きいことから、MCMCはうまく収束していると判断できます。
さらに、設定した真の値(beta_0=4.5, beta_1=-0.4, beta_2=0.3, phi=5)はいずれも95%信用区間に含まれていますので、このまま先に進みます。
ステップ5: 結果の可視化と解釈
推定結果を可視化して、ビジネス上の示唆を導き出します。
# 事後予測チェック
bayesplot::ppc_dens_overlay(y = sim_data$stay_time, yrep = as.matrix(fit, pars = "y_rep")[1:50, ]) +
labs(title = "事後予測チェック")
# パラメータの事後分布
stan_plot(fit, pars = c("beta", "phi")) +
labs(title = "パラメータの事後分布")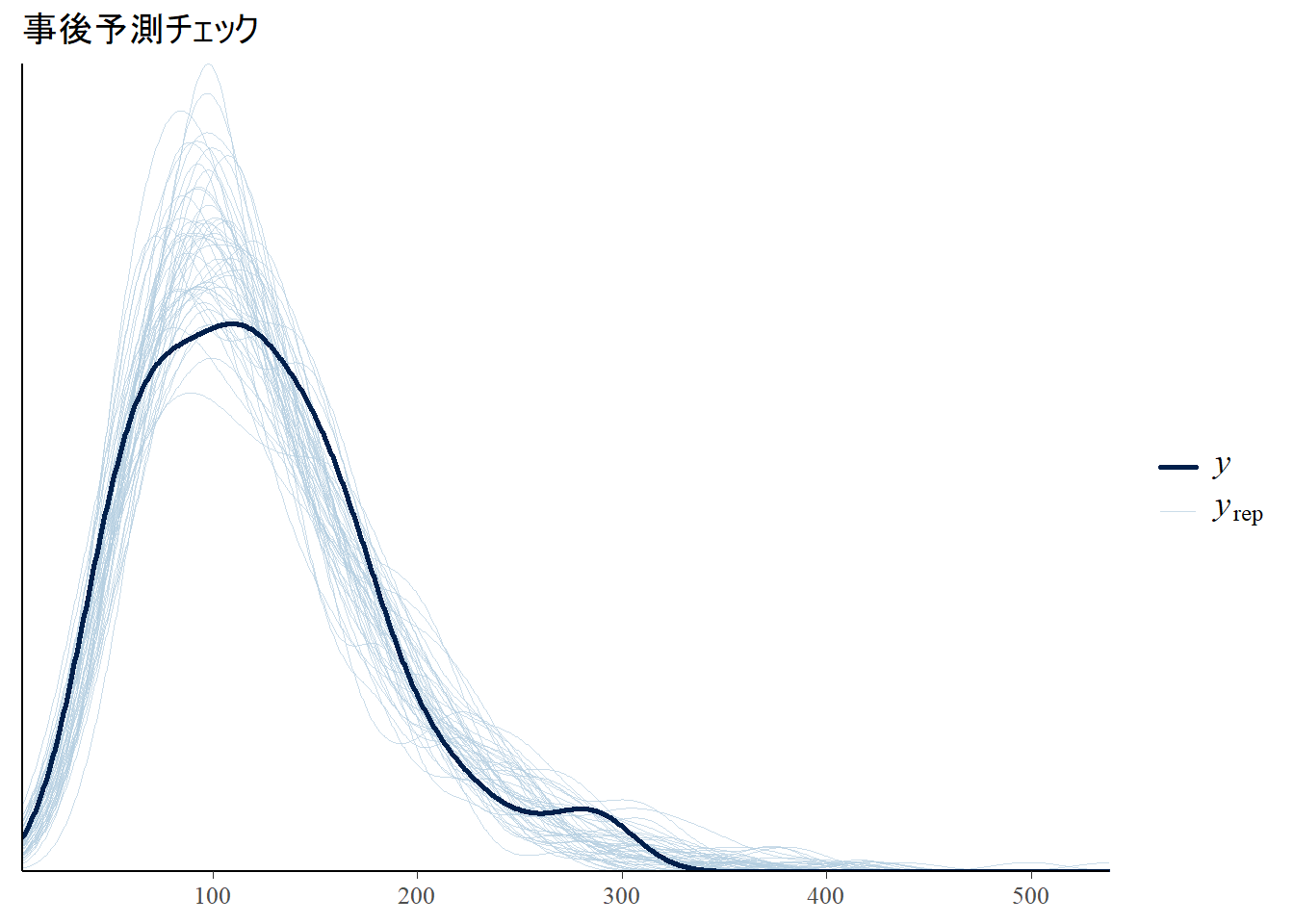
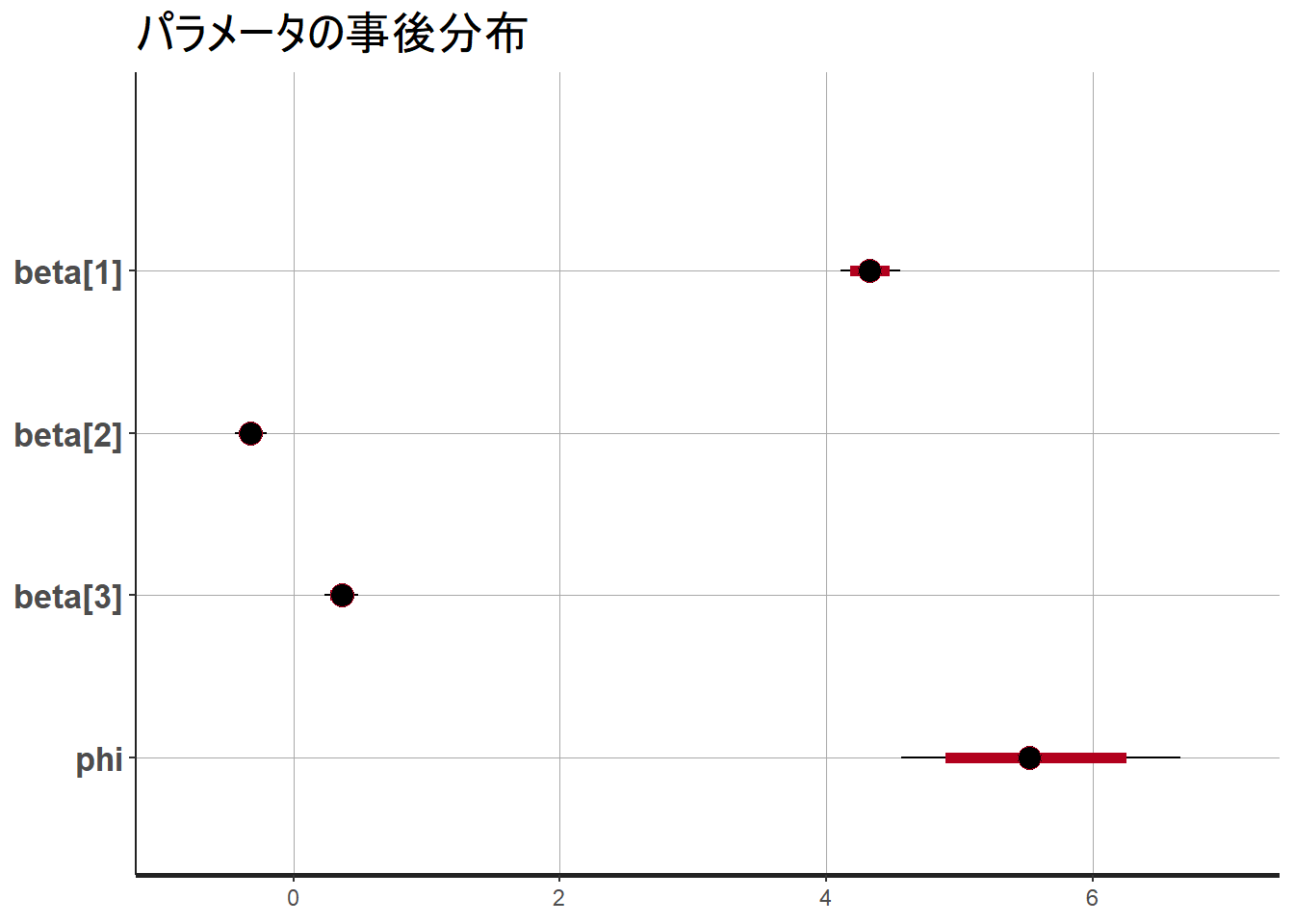
Figure 3 の 事後予測チェックのグラフを見ると、モデルから生成されたデータ(薄い青線)の分布が、実データ(濃い青線)の分布を ほぼ 再現できていることが確認できます。
次に、分析の主目的である「広告」と「訪問回数」の効果を可視化します。
# MCMCサンプルからbetaの事後分布をマトリックスとして抽出
beta_samples <- as.matrix(fit, pars = "beta")
# 予測用のデータグリッドを作成
pred_grid <- expand.grid(
ad_flg = c(0, 1),
log_visits = seq(min(sim_data$log_visits), max(sim_data$log_visits), length.out = 50)
)
pred_grid$visits <- exp(pred_grid$log_visits)
# 予測値を計算するための計画行列を作成
X_pred <- model.matrix(~ ad_flg + log_visits, data = pred_grid)
# X_pred (100x3) と beta_samplesの転置 (3x4000) の行列積を計算
# これにより、各MCMCサンプルにおける各予測点の平均値(mu)が得られる
mu_pred_samples <- exp(X_pred %*% t(beta_samples))
# 予測値の要約統計量(中央値、95%信用区間)を計算
pred_summary <- data.frame(
pred_grid,
median = apply(mu_pred_samples, 1, median),
lower = apply(mu_pred_samples, 1, quantile, probs = 0.025),
upper = apply(mu_pred_samples, 1, quantile, probs = 0.975)
)
# 凡例用のラベルを作成
pred_summary$ad_label <- factor(pred_summary$ad_flg, levels = c(0, 1), labels = c("オーガニック", "広告経由"))
sim_data$ad_label <- factor(sim_data$ad_flg, levels = c(0, 1), labels = c("オーガニック", "広告経由"))
# グラフを作成
ggplot(pred_summary, aes(x = visits, y = median, color = ad_label, fill = ad_label)) +
geom_line(linewidth = 1) +
geom_ribbon(aes(ymin = lower, ymax = upper), alpha = 0.2, linetype = "dotted") +
geom_point(data = sim_data, aes(x = visits, y = stay_time, color = ad_label), alpha = 0.6) +
scale_x_log10() +
labs(
title = "サイト滞在時間の予測",
subtitle = "訪問回数と流入経路による影響 (95%信用区間)",
x = "サイト訪問回数 (対数スケール)",
y = "サイト滞在時間 (秒)",
color = "流入経路",
fill = "流入経路"
) +
theme_minimal(base_size = 14) +
scale_color_brewer(palette = "Set1") +
scale_fill_brewer(palette = "Set1")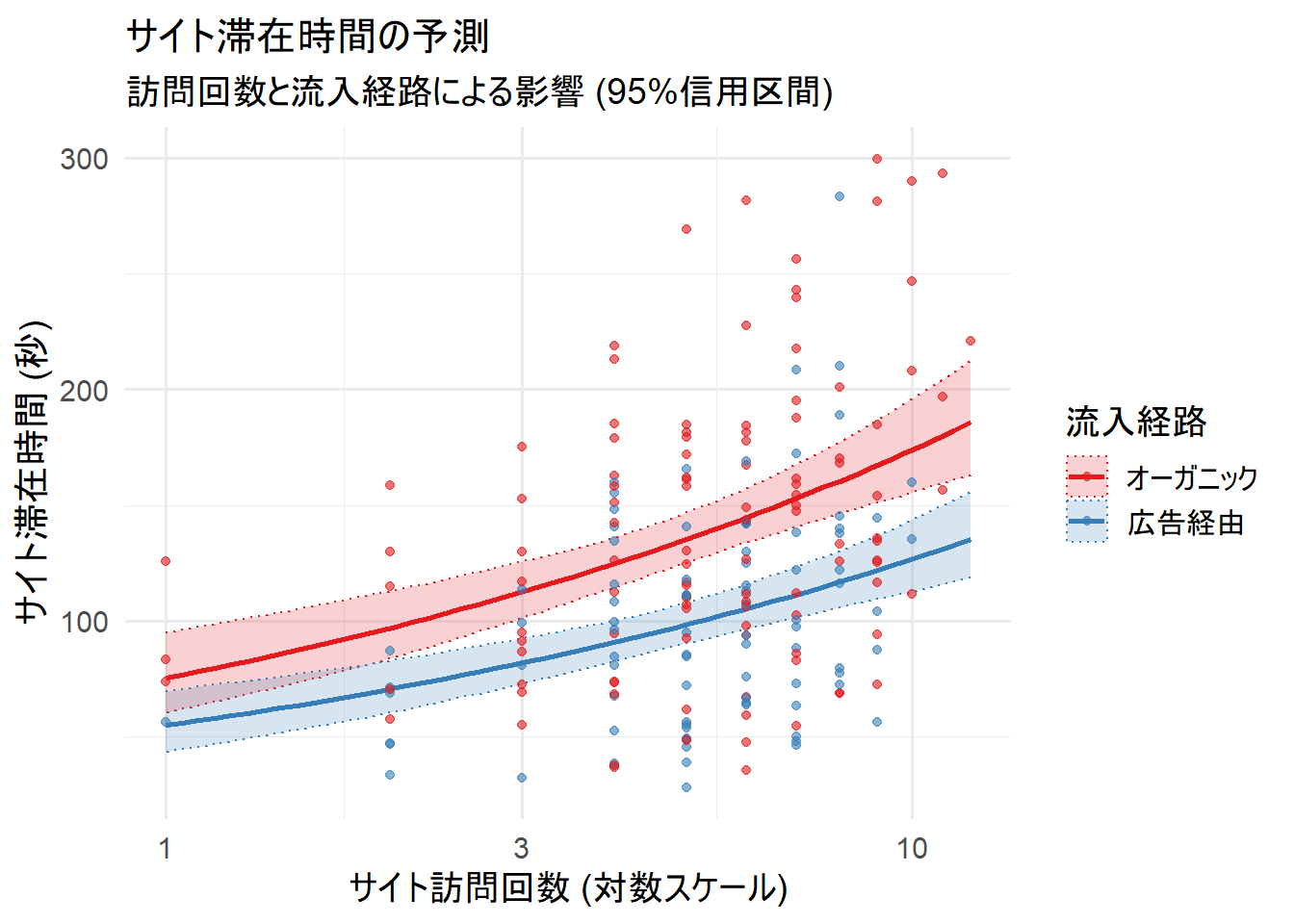
グラフからの示唆と結論:
- 訪問回数の効果: グラフの線が右肩上がりであることから、流入経路にかかわらず、訪問回数が多い顧客ほどサイト滞在時間が長くなる傾向があることがわかります。
- 広告の効果: 同じ訪問回数で比較すると、広告経由(赤線)の顧客はオーガニック検索(青線)の顧客よりも一貫して滞在時間が短いことが確認できます。
- 結論: 当初立てた「広告経由の顧客は滞在時間が短く、リピーターは長い」という仮説は、データによって支持されました。この結果から、分析チームは「リピート顧客を増やすためのロイヤリティプログラム」や、「広告経由で流入した顧客をサイト内に長く留まらせるためのコンテンツ改善」といった、具体的な施策の検討に進むことができるでしょう。
以上です。

