
Rで 時系列データ因果探索:Transfer Entropy を試みます。
Rの関数 transfer_entropy {RTransferEntropy} については、こちらを参照してください。

Transfer Entropyとは
Transfer Entropy(TE)は、情報理論の概念を用いて、2つの時系列データ間の情報の流れの方向と量を測定する手法です。これにより、一方の時系列が他方の時系列に対して持つ「因果的な影響」を推定することができます。
簡単に言うと、Transfer Entropyは「時系列Yの過去の値を知ることで、時系列Xの未来の値を予測する際の不確実性が、どれだけ減少するか」を定量化したものです。
数式で表すと、YからXへのTransfer Entropy TE(Y→X) は以下のように定義されます。
TE(Y→X) = H(X_{t+1} | X_t^{(k)}) - H(X_{t+1} | X_t^{(k)}, Y_t^{(l)})
ここで、
-
H(A|B)は、Bが与えられたときのAの条件付きエントロピー(不確実性)を表します。 -
X_{t+1}は、時系列Xの1ステップ未来の値です。 -
X_t^{(k)}は、時刻tまでのXの過去k個の値の履歴(X_t, X_{t-1}, ..., X_{t-k+1})です。 -
Y_t^{(l)}は、時刻tまでのYの過去l個の値の履歴(Y_t, Y_{t-1}, ..., Y_{t-l+1})です。
この式の意味は次の通りです。
- 第1項:
H(X_{t+1} | X_t^{(k)}): Xの過去だけを使ってXの未来を予測するときの不確実性。 - 第2項:
H(X_{t+1} | X_t^{(k)}, Y_t^{(l)}): Xの過去に加えて、Yの過去も使ってXの未来を予測するときの不確実性。
もしYがXに対して影響を与えている(情報がYからXへ流れている)ならば、Yの過去の値はXの未来を予測するのに役立つはずです。その結果、第2項の不確実性は第1項より小さくなり、TE(Y→X) は正の値を取ります。逆に、YがXに影響を与えていなければ、TE(Y→X) は0に近くなります。
Transfer Entropyの主な特徴は以下の通りです。
- 非線形性の検出: 特定の関数形(線形など)を仮定しないため、線形・非線形を問わず変数間の関係を捉えることができます。
- 方向性の特定:
TE(Y→X)とTE(X→Y)を別々に計算することで、情報がどちらの方向に流れているか(XがYに影響を与えているか、YがXに影響を与えているか)を区別できます。 - グレンジャー因果性の一般化: 経済学などで用いられるグレンジャー因果性は線形モデルを前提としますが、Transfer Entropyはそれを情報理論的に一般化したものと見なせます。
シミュレーションのシナリオ
シナリオ: 「人気インフルエンサーのSNS投稿は、新商品の口コミ数を増やすのか?」
ある企業が新商品を発売し、そのプロモーションのために人気インフルエンサーを起用しました。私たちは、このインフルエンサーのプロモーション活動が、実際にSNS上での商品の口コミ数にどれだけ影響を与えたかを分析したいと考えています。
- 時系列データY: インフルエンサーが、特定の商品について言及した1日あたりのSNS投稿数。
- 時系列データX: その商品の1日あたりのSNS上の口コミ(UGC: User Generated Content)数。
仮定する因果関係:
- YからXへの影響 (
Y → X): インフルエンサーが商品を宣伝する投稿をすると(Yが増加)、翌日に商品の口コミ数が非線形に増加する(Xが増加)。- 非線形性の詳細: 投稿に対して相乗効果で口コミが増える、という関係を想定します。これを
Yの値が3乗でXに影響する、といった形でモデル化します。
- 非線形性の詳細: 投稿に対して相乗効果で口コミが増える、という関係を想定します。これを
- XからYへの影響 (
X → Y): 基本的には無いと仮定します。つまり、世の中の口コミ数が増えたからといって、契約に基づいているインフルエンサーの投稿数がそれに連動して変化することはない、と考えます。
このシナリオでTransfer Entropyを計算すれば、YからXへの情報の流れ、つまりTE(Y→X)のみが統計的に有意な値として検出されるはずです。
Rによるシミュレーションコード
上記のシナリオに沿って、シミュレーションを実行するRコードを以下に示します。
# 必要なパッケージの読み込み
library(RTransferEntropy)
library(ggplot2)
library(dplyr)
library(tidyr)
# 再現性のための乱数シード設定
seed <- 20250830
set.seed(seed)
# 1. シナリオに基づいた時系列データの生成
n_obs <- 200 # 観測期間(日数)
# Y: インフルエンサーの投稿数 (原因側)
# 全く投稿しない日や1投稿の日もあれば、時々複数投稿するスパイク状のデータを想定
# ポアソン分布に従う乱数で生成
y <- rpois(n_obs, lambda = 0.5)
# X: 商品の口コミ数 (結果側)
# X_t = 0.6 * X_{t-1} + 0.9 * (Y_{t-1})^3 + noise
# -> Xは自身の前日のX(口コミの持続性)と、同じく前日のY(インフルエンサーの投稿)の**3乗**に影響される
x <- numeric(n_obs)
x[1:2] <- 5 # 初期値
for (t in 3:n_obs) {
# 1日前のyの値が3乗で効いてくる非線形の関係
x[t] <- 0.6 * x[t - 1] + 0.9 * (y[t - 1])^3 + rnorm(1, mean = 0, sd = 1.5)
# 口コミ数が負にならないように調整
if (x[t] < 0) {
x[t] <- 0
}
}
# 生成したデータをデータフレームにまとめる
sim_data <- data.frame(
day = 1:n_obs,
口コミ数_X = x,
投稿数_Y = y
)
# 2. 生成したデータの可視化
# データを描画しやすいように縦長形式に変換
plot_data <- sim_data %>%
pivot_longer(
cols = c("口コミ数_X", "投稿数_Y"),
names_to = "時系列",
values_to = "値"
)
# ggplotでプロットを作成
g <- ggplot(plot_data, aes(x = day, y = 値, color = 時系列)) +
geom_line(linewidth = 0.8) +
facet_wrap(~時系列, ncol = 1, scales = "free_y") +
labs(
title = "インフルエンサーの投稿数(Y)と商品の口コミ数(X)の推移",
x = "日数",
y = "観測値"
) +
theme_minimal() +
theme(
legend.position = "none",
plot.title = element_text(hjust = 0.5),
plot.subtitle = element_text(hjust = 0.5)
)
print(g)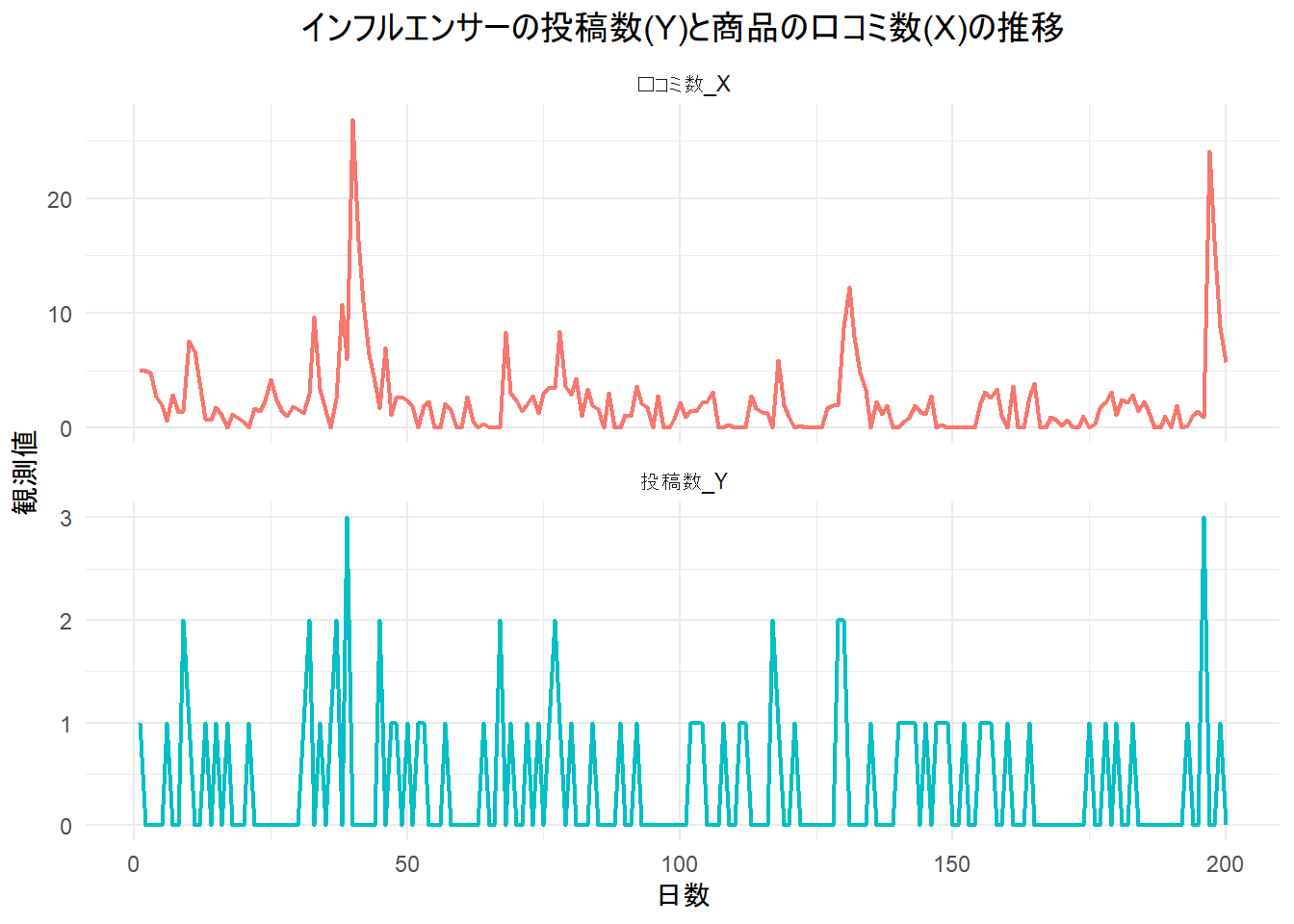
- Figure 1 は、シナリオに沿った2つの時系列データ
x(口コミ数) とy(投稿数) です。yはランダムなスパイク状のデータ、xはyの前日の値の3乗に影響を受ける非線形なデータとして作成されています。
# 3. Transfer Entropyの計算
# 計算を実行する
te_results <- transfer_entropy(
x = sim_data$口コミ数_X,
y = sim_data$投稿数_Y,
lx = 1,
ly = 1,
nboot = 100,
quiet = TRUE,
seed = seed
)
# 計算結果のサマリーを表示
cat("--------------------------------------------------\n")
cat("Transfer Entropy 計算結果サマリー\n")
cat("--------------------------------------------------\n")
summary(te_results)--------------------------------------------------
Transfer Entropy 計算結果サマリー
--------------------------------------------------
Shannon's Transfer Entropy
Coefficients:
te ete se p-value
X->Y 0.019167 0.000000 0.0110 0.48
Y->X 0.148847 0.123193 0.0111 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Bootstrapped TE Quantiles (100 replications):
Direction 0% 25% 50% 75% 100%
X->Y 0.0021 0.0134 0.0190 0.0249 0.0635
Y->X 0.0031 0.0121 0.0196 0.0282 0.0545
Number of Observations: 2001. Coefficientsセクションの解説
この表は、2つの時系列データ間の情報の流れ(因果関係)の方向と強さ、そしてその統計的な信頼性を示しています。
行の解釈:
transfer_entropy(x = 口コミ数_X, y = 投稿数_Y)と実行した場合、summaryの出力は以下のように対応します。
-
Y->X行:投稿数(Y)から口コミ数(X)への情報の流れ -
X->Y行:口コミ数(X)から投稿数(Y)への情報の流れ
各列の意味:
-
te: Transfer Entropyの計算値そのものです。 -
ete: Effective Transfer Entropyの略で、最も重要な指標です。teからノイズ(偶然生じうる情報の見かけ上の流れ)の影響を差し引いた、より実質的な情報の流れの大きさを示します。この値が正で大きいほど、因果的な影響が強いと解釈できます。 -
se: 標準誤差(Standard Error)で、推定値のばらつきを示します。 -
p-value: 「2つの時系列間には情報の流れが存在しない」という帰無仮説が正しいとした場合に、観測されたete以上の値が得られる確率です。このp値が設定した有意水準より小さい場合、「2つの時系列間には情報の流れが存在しない」という帰無仮説が棄却されます。
2. 各方向の因果性の評価
a) 投稿数(Y) → 口コミ数(X) の方向(Y->X行)
te ete se p-value
Y->X 0.148847 0.123193 0.0111 <2e-16 ***-
ete(実質的な情報の流れ):0.123193と正の値が出力されています。これは、インフルエンサーの投稿履歴を知ることが、翌日の口コミ数を予測するのに役立つことを示唆しています。 -
p-value(統計的有意性):<2e-16となっており、これは有意水準(5%) よりも小さい値です。 - 結論: 「インフルエンサーの投稿数(Y)から、商品の口コミ数(X)への情報の流れは存在しない」とする帰無仮説は棄却されます。
b) 口コミ数(X) → 投稿数(Y) の方向(X->Y行)
te ete se p-value
X->Y 0.019167 0.000000 0.0110 0.48 -
ete(実質的な情報の流れ):0.000000となっており、口コミ数の履歴を知っても、インフルエンサーの将来の投稿数を予測する上での実質的な情報量はゼロであったことを示しています。 -
p-value(統計的有意性):0.48と有意水準を超えています。 - 結論: 「商品の口コミ数(X)から、インフルエンサーの投稿数(Y)への情報の流れ存在しない」とする帰無仮説は棄却できません。
3. 総合的な結論
この分析結果は、「インフルエンサーの投稿(Y)が商品の口コミ数(X)に影響を与える」という一方向の因果関係のみを支持し、その逆の「口コミ数(X)がインフルエンサーの投稿(Y)に影響を与える」という関係は認められませんでした。
これは、シミュレーションで意図的に設定した因果構造を、Transfer Entropyが正しく検出できたことを示しています。
以上です。

