
Rで 機械学習:サポートベクターマシン を試みます。
1. サポートベクターマシン(SVM)とは
サポートベクターマシン(Support Vector Machine, SVM)は、主に分類問題を解くために用いられる教師あり学習アルゴリズムの一つです。回帰問題にも応用できます(サポートベクター回帰, SVR)。
SVMの目的は、与えられた異なるクラスのデータ群を分離するための最適な境界線(決定境界)を見つけ出すことです。
SVMの主な特徴
1. マージンの最大化
SVMの最も重要なアイデアは、単にデータを分離する境界線を引くだけでなく、マージンを最大化する境界線を引く点にあります。
- 決定境界: データを分類する線のことです(2次元なら直線、3次元なら平面、それ以上なら超平面)。
- マージン: 決定境界と、境界線に最も近い各クラスのデータ点との距離のことです。
- なぜマージンを最大化するのか?: マージンが大きいほど、境界線は各クラスのデータ群から離れた位置に引かれます。これにより、未知のデータに対する予測性能(汎化性能)が高まると期待できます。余裕を持たせて境界線を引くイメージです。
数学的には、決定境界を \(w^T x + b = 0\) としたとき、マージンの大きさは \(\dfrac{2}{||w||}\) で表されます。SVMは、全てのデータ点が正しく分類されるという制約 \(y_i \left( w^T x_i + b \right) \ge 1\) のもとで、マージンを最大化、つまり \(||w||\) を最小化する \(w\) と \(b\) を見つけます。
2. サポートベクター
マージンを定義する、決定境界に最も近いデータ点のことをサポートベクターと呼びます。 SVMでは、このサポートベクターだけが決定境界の位置を決定します。つまり、サポートベクター以外のデータ点が多少動いても、決定境界は変化しません。これにより、外れ値に対して比較的頑健(ロバスト)なモデルが作られます。
3. カーネルトリック
現実のデータは、単純な直線や平面ではきれいに分離できないことがよくあります(線形分離不可能なデータ)。 このような場合に、SVMはカーネルトリックというテクニックを使います。
- アイデア: 元の次元のデータ(例:2次元)を、より高次元の空間(例:3次元)に写像することで、データを線形分離可能に変換します。
- カーネル関数: この高次元への写像と内積計算を、元の次元のまま行うための関数です。実際に高次元空間でデータを計算する必要がないため、計算コストを削減できます。
代表的なカーネル関数には以下のようなものがあります。
- 線形カーネル: 線形分離可能なデータに使用します。
- 多項式カーネル: 多項式で表現されるような非線形の境界線を引きます。
- RBF(動径基底関数)カーネル: 複雑な非線形の境界線を引くことができます。
2. シミュレーションのシナリオ
舞台: とある果樹園
この果樹園では、2種類の果物、「フジリンゴ」と「オウシュウナシ」を栽培しています。あなたは果樹園の新人スタッフとして、収穫した果物を自動で仕分けるシステムを開発するよう任されました。
手元にあるデータは、それぞれの果物の「糖度」と「硬度」を測定したものです。この2つの特徴を使って、新しい果物がどちらの種類なのかを予測するモデルをSVMで構築します。
シナリオのステップ:
- 基本的な分類(線形分離可能なケース)
- フジリンゴとオウシュウナシは、糖度と硬度の分布が比較的はっきりと分かれています。
- このデータを使ってSVMを学習させ、「マージンが最大化」される様子と、「サポートベクター」がどの果物になるのかを観察します。
- 複雑な分類(線形分離不可能なケース)
- 最近、市場のニーズに応えるため、特殊な栽培法を試したところ、糖度と硬度の分布が複雑な新しい果物ができました。具体的には、「フジリンゴ」のデータ群の周りを「オウシュウナシ」のデータ群が取り囲むような、ドーナツ状の分布になってしまいました。
- このようなデータは、単純な直線では分類できません。
- ここで「カーネルトリック」を利用します。RBFカーネルを使ってSVMを学習させ、複雑な境界線を描いて分類できることを確認します。
3. R言語によるシミュレーションコード
それでは、上記のシナリオに沿ってシミュレーションを実行します。
準備:必要なライブラリのインストールと読み込み
まず、シミュレーションに必要なRパッケージを読み込みます。
# ライブラリの読み込み
library(e1071)
library(ggplot2)
library(dplyr)ステップ1:基本的な分類(線形分離可能なケース)
フジリンゴとオウシュウナシのデータが、比較的はっきりと分かれている状況をシミュレートします。
# 再現性のための乱数シード設定
seed <- 20250810
set.seed(seed)
# データ生成
n <- 50 # 各クラスのデータ数
# フジリンゴのデータ (糖度が高く、硬度もやや高い)
fuji_apple <- data.frame(
sugar = rnorm(n, mean = 15, sd = 1.5),
hardness = rnorm(n, mean = 8, sd = 1),
class = "フジリンゴ"
)
# オウシュウナシのデータ (糖度がやや低く、硬度も低い)
oushu_pear <- data.frame(
sugar = rnorm(n, mean = 12, sd = 1.5),
hardness = rnorm(n, mean = 5, sd = 1),
class = "オウシュウナシ"
)
# データを結合
fruit_data <- rbind(fuji_apple, oushu_pear)
fruit_data$class <- as.factor(fruit_data$class)
# SVMモデルの学習 (線形カーネル)
svm_linear <- svm(class ~ ., data = fruit_data, kernel = "linear", scale = TRUE)
# サポートベクターを特定
support_vectors <- fruit_data[svm_linear$index, ]
cat(paste("学習の結果、", nrow(support_vectors), "個のサポートベクターが特定されました。\n\n"))
# 決定境界とマージンをプロットするためのグリッドを作成
grid_range <- apply(fruit_data[, 1:2], 2, range)
x_grid <- seq(from = grid_range[1, 1], to = grid_range[2, 1], length.out = 100)
y_grid <- seq(from = grid_range[1, 2], to = grid_range[2, 2], length.out = 100)
grid_df <- expand.grid(sugar = x_grid, hardness = y_grid)
# グリッドの各点での予測値(決定境界からの距離)を計算
pred_values <- predict(svm_linear, grid_df, decision.values = TRUE)
decision_values <- as.vector(attr(pred_values, "decision.values"))
grid_df$decision_values <- decision_values
# プロットの作成
p1 <- ggplot(data = fruit_data, aes(x = sugar, y = hardness)) +
# 決定境界とマージンを等高線で描画
geom_contour(data = grid_df, aes(z = decision_values), breaks = 0, color = "black", linewidth = 1, linetype = "solid") +
geom_contour(data = grid_df, aes(z = decision_values), breaks = c(-1, 1), color = "black", linewidth = 0.5, linetype = "dashed") +
# 元のデータをプロット
geom_point(aes(color = class, shape = class), size = 3) +
# サポートベクターを強調表示
geom_point(data = support_vectors, aes(x = sugar, y = hardness), shape = 21, size = 5, fill = NA, stroke = 1.5, color = "blue") +
scale_color_manual(values = c("フジリンゴ" = "red", "オウシュウナシ" = "darkgreen")) +
scale_shape_manual(values = c("フジリンゴ" = 16, "オウシュウナシ" = 17)) +
labs(
title = "SVMによる果物の分類(線形分離可能なケース)",
subtitle = "実線: 決定境界, 破線: マージン, 青い丸: サポートベクター",
x = "糖度",
y = "硬度",
color = "果物の種類",
shape = "果物の種類"
) +
theme_bw() +
theme(legend.position = "bottom")
print(p1)学習の結果、 11 個のサポートベクターが特定されました。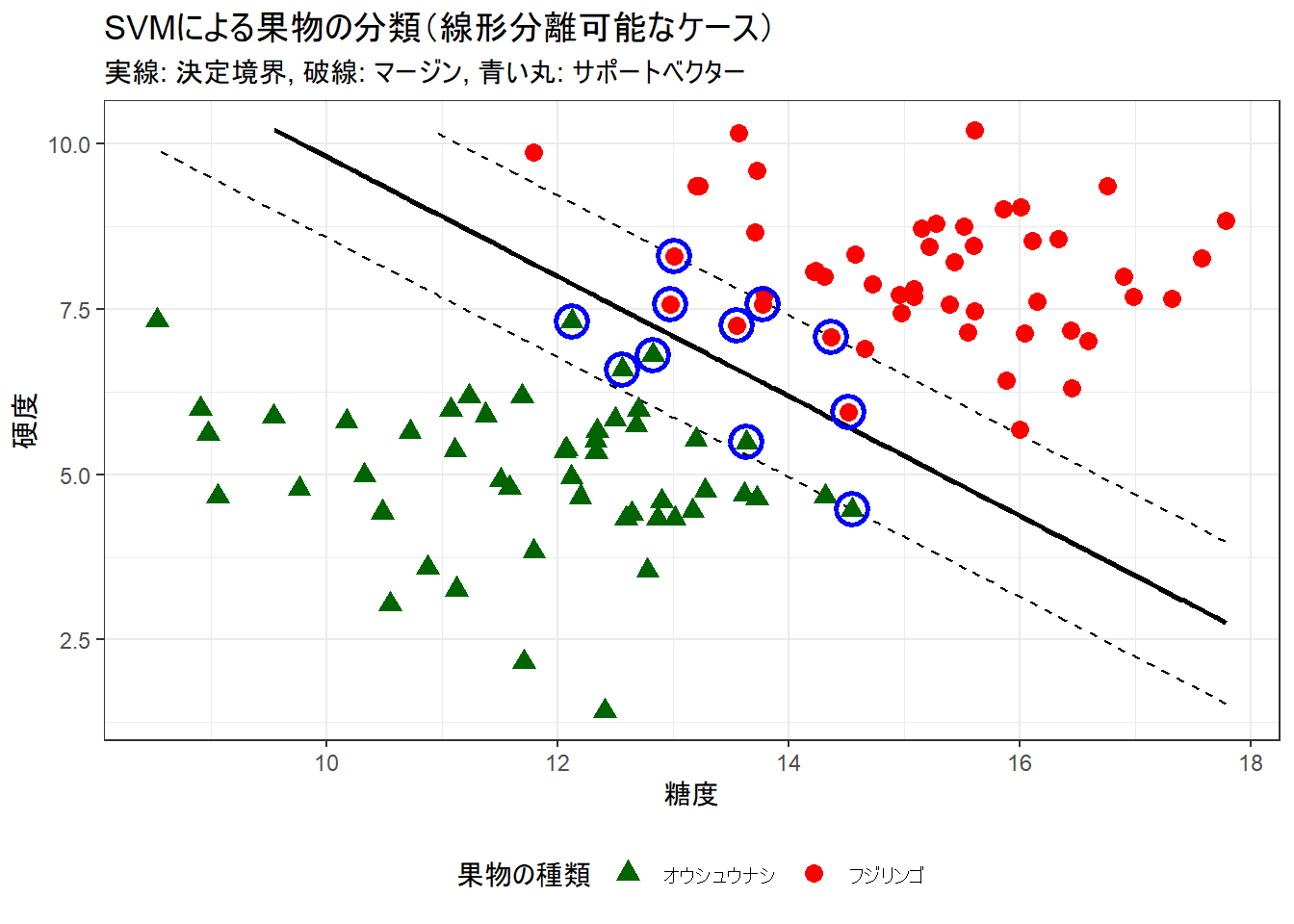
Figure 1 の説明:
- 赤色の点(フジリンゴ)と緑色の点(オウシュウナシ)が、それぞれのデータ分布です。
- 中央の黒い実線が、SVMによって見つけ出された「決定境界」です。
- 黒い破線が「マージン」の境界です。SVMはこのマージンの幅を最大化するように決定境界を引きます。
- 青い丸で囲まれたデータ点が「サポートベクター」です。これらの点だけが、決定境界とマージンの位置を決定しています。
ステップ2:複雑な分類(線形分離不可能なケース)
次に、栽培法を変えた結果、データが直線では分離できなくなった状況をシミュレートします。
# 再現性のための乱数シード設定
set.seed(seed)
# ドーナツ状のデータ生成
n <- 100 # 各クラスのデータ数
# フジリンゴのデータ (中心部)
center_apple <- data.frame(
r = rnorm(n, mean = 1, sd = 0.5),
t = runif(n, 0, 2 * pi)
) %>% mutate(
sugar = r * cos(t) + 13,
hardness = r * sin(t) + 6,
class = "フジリンゴ"
)
# オウシュウナシのデータ (外側)
outer_pear <- data.frame(
r = rnorm(n, mean = 4, sd = 0.7),
t = runif(n, 0, 2 * pi)
) %>% mutate(
sugar = r * cos(t) + 13,
hardness = r * sin(t) + 6,
class = "オウシュウナシ"
)
# データを結合
fruit_data_nonlinear <- rbind(
center_apple[, c("sugar", "hardness", "class")],
outer_pear[, c("sugar", "hardness", "class")]
)
fruit_data_nonlinear$class <- as.factor(fruit_data_nonlinear$class)
# SVMモデルの学習 (RBFカーネル)
# gammaとcostは最適な値を探す必要がありますが、ここでは良い結果が得られる値を指定します
svm_rbf <- svm(class ~ ., data = fruit_data_nonlinear, kernel = "radial", gamma = 0.5, cost = 1, scale = TRUE)
# サポートベクターを特定
support_vectors_rbf <- fruit_data_nonlinear[svm_rbf$index, ]
cat(paste("学習の結果、", nrow(support_vectors_rbf), "個のサポートベクターが特定されました。\n\n"))
# 決定境界プロット用のグリッドを作成
grid_range_nl <- apply(fruit_data_nonlinear[, 1:2], 2, range)
x_grid_nl <- seq(from = grid_range_nl[1, 1], to = grid_range_nl[2, 1], length.out = 100)
y_grid_nl <- seq(from = grid_range_nl[1, 2], to = grid_range_nl[2, 2], length.out = 100)
grid_df_nl <- expand.grid(sugar = x_grid_nl, hardness = y_grid_nl)
# グリッドの各点で予測
# RBFカーネルの場合、マージンは決定境界からの距離1とは限らないため、背景色で領域を表現します
grid_df_nl$predicted_class <- predict(svm_rbf, grid_df_nl)
# プロットの作成
p2 <- ggplot(data = fruit_data_nonlinear, aes(x = sugar, y = hardness)) +
# 予測領域を背景色で描画
geom_raster(data = grid_df_nl, aes(fill = predicted_class), alpha = 0.3, interpolate = TRUE) +
# 元のデータをプロット
geom_point(aes(color = class, shape = class), size = 3) +
# サポートベクターを強調表示
geom_point(data = support_vectors_rbf, aes(x = sugar, y = hardness), shape = 21, size = 5, fill = NA, stroke = 1.5, color = "blue") +
scale_color_manual(values = c("フジリンゴ" = "red", "オウシュウナシ" = "darkgreen")) +
scale_fill_manual(values = c("フジリンゴ" = "red", "オウシュウナシ" = "darkgreen")) +
scale_shape_manual(values = c("フジリンゴ" = 16, "オウシュウナシ" = 17)) +
guides(fill = "none") + # 背景色の凡例は非表示
labs(
title = "SVMによる果物の分類(線形分離不可能なケース)",
subtitle = "RBFカーネルにより非線形の決定境界を形成。青い丸はサポートベクター。",
x = "糖度",
y = "硬度",
color = "果物の種類",
shape = "果物の種類"
) +
theme_bw() +
theme(legend.position = "bottom")
print(p2)学習の結果、 33 個のサポートベクターが特定されました。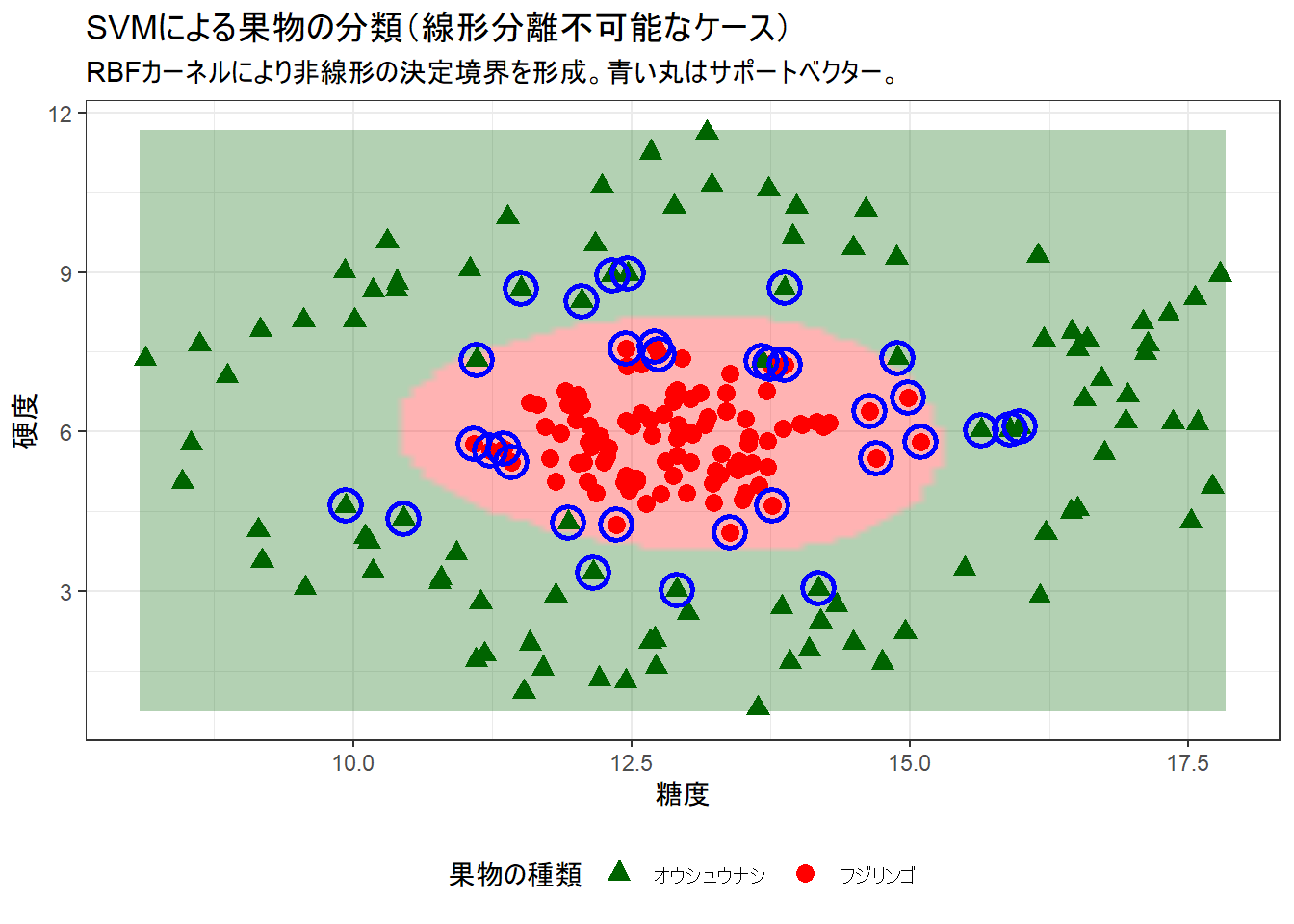
Figure 2 の説明:
- データは中心にフジリンゴ、その周りにオウシュウナシが分布しており、直線では分離できません。
- RBFカーネルを用いたSVMは、背景色で示されるように、円形の非線形な決定境界を学習しました。
- 「カーネルトリック」により、元のデータを高次元空間に写像し、そこで線形分離を行っていると解釈できます。
- このケースでも、境界線の近くにある「サポートベクター」(青い丸)が、複雑な境界線の形状を決定しています。
シミュレーションのまとめ
このシミュレーションを通して、サポートベクターマシンがどのようにしてデータを分類するかを2つの側面から確認しました。
- マージン最大化: 線形分離可能なデータに対し、最も汎化性能が高いと考えられる、マージンが最大となる境界線を見つけ出します。その際、境界線の決定にはサポートベクターのみが関与します。
- カーネルトリック: 線形分離不可能な複雑なデータに対し、カーネル関数(今回はRBFカーネル) を用いることで、非線形な決定境界を学習し、分類することができます。
以上です。

