
Rの関数から kpss.test {tseries} を確認します。
本ポストはこちらの続きです。

kpss.test関数について
kpss.testは、クウィアトコウスキー–フィリップス–シュミット–シン(Kwiatkowski-Phillips-Schmidt-Shin, KPSS)検定 を実行するための関数です。ADF検定やPP検定と同じく、時系列データの定常性を評価するための検定ですが、検定の仮説設定が全く逆であるという特徴を持ちます。
ADF/PP検定とKPSS検定の違い
- ADF検定 / PP検定:
- 帰無仮説 (H₀): 単位根が存在する(非定常である)。
- 対立仮説 (H₁): 定常(またはトレンド定常)である。
- → p値が設定した有意水準を下回る場合、「定常である」と結論付けます。
- KPSS検定:
- 帰無仮説 (H₀): 定常(またはトレンド定常)である。
- 対立仮説 (H₁): 単位根が存在する(非定常である)。
- → p値が設定した有意水準を下回る場合、「非定常である」と結論付けます。
つまり、KPSS検定は「データが定常である」という仮説が正しいかどうかを検証するテストです。
kpss.test関数の引数について
library(tseries)
args(kpss.test)function (x, null = c("Level", "Trend"), lshort = TRUE)
NULLx
検定の対象となる数値ベクトル、または時系列オブジェクトを指定します。
null
帰無仮説の種類を指定する引数です。「データはどのような種類の定常性を持つか」を仮定します。
-
"Level"(デフォルト): Stationarity round a constant level(本ポストでは以降「水準定常性」と呼称します)を帰無仮説とします。データが時間を通じて一定の平均値の周りを変動している状態を「定常」と仮定します。 -
"Trend": Stationarity around a deterministic trend)(本ポストでは以降「トレンド定常性」と呼称します)を帰無仮説とします。データが確定的な時間トレンド(直線的な上昇または下降傾向)の周りを変動している状態を「定常」と仮定します。
データの形状に応じて適切な帰無仮説を選択する必要があります。
lshort
検定統計量の計算に使用するラグの切り捨てパラメータの計算方法を制御する論理値です。
-
TRUE(デフォルト): “short”バージョンとして、trunc(4*(length(x)/100)^0.25)という計算式でラグを決定します。 -
FALSE: “long”バージョンとして、trunc(12*(length(x)/100)^0.25)という計算式でラグを決定します。
こちらののパラメータは、誤差項の長期的な分散を推定する際に使用されます。
シミュレーション
KPSS検定の逆の仮説設定を確認するために、4つの異なる時系列データを生成し、それぞれにkpss.testを適用して結果を比較します。
なお、有意水準は5%とします。
# 再現性を確保するために乱数のシードを設定します
seed <- 20251015
set.seed(seed)
# シミュレーションのためのサンプルデータ作成
n <- 250
# --- null="Level" の検定に対応するデータ ---
# 1. 水準定常なデータ (帰無仮説が真)
# null='Level'用データ:水準定常過程
data_level_stationary <- arima.sim(model = list(ar = 0.5), n = n)
# 2. 単位根を持つデータ (対立仮説が真)
# null='Level'用データ:単位根過程
data_unit_root <- cumsum(rnorm(n))
# --- null="Trend" の検定に対応するデータ ---
# 3. トレンド定常なデータ (帰無仮説が真)
# null='Trend'用データ:トレンド定常過程
data_trend_stationary <- 10 + 0.3 * (1:n) + arima.sim(model = list(ar = 0.5), n = n)
# 4. ドリフト付き単位根データ (対立仮説が真)
# null='Trend'用データ:ドリフト付き単位根過程
data_unit_root_drift <- cumsum(rnorm(n, sd = 2) + 0.3)
# 作成したデータの可視化
par(mfrow = c(2, 2), mar = c(4, 4, 3, 2))
plot(data_level_stationary, type = "l", main = "データ1: 水準定常", col = "darkgreen")
plot(data_unit_root, type = "l", main = "データ2: 単位根", col = "darkblue")
plot(data_trend_stationary, type = "l", main = "データ3: トレンド定常", col = "darkred")
plot(data_unit_root_drift, type = "l", main = "データ4: ドリフト付き単位根", col = "purple")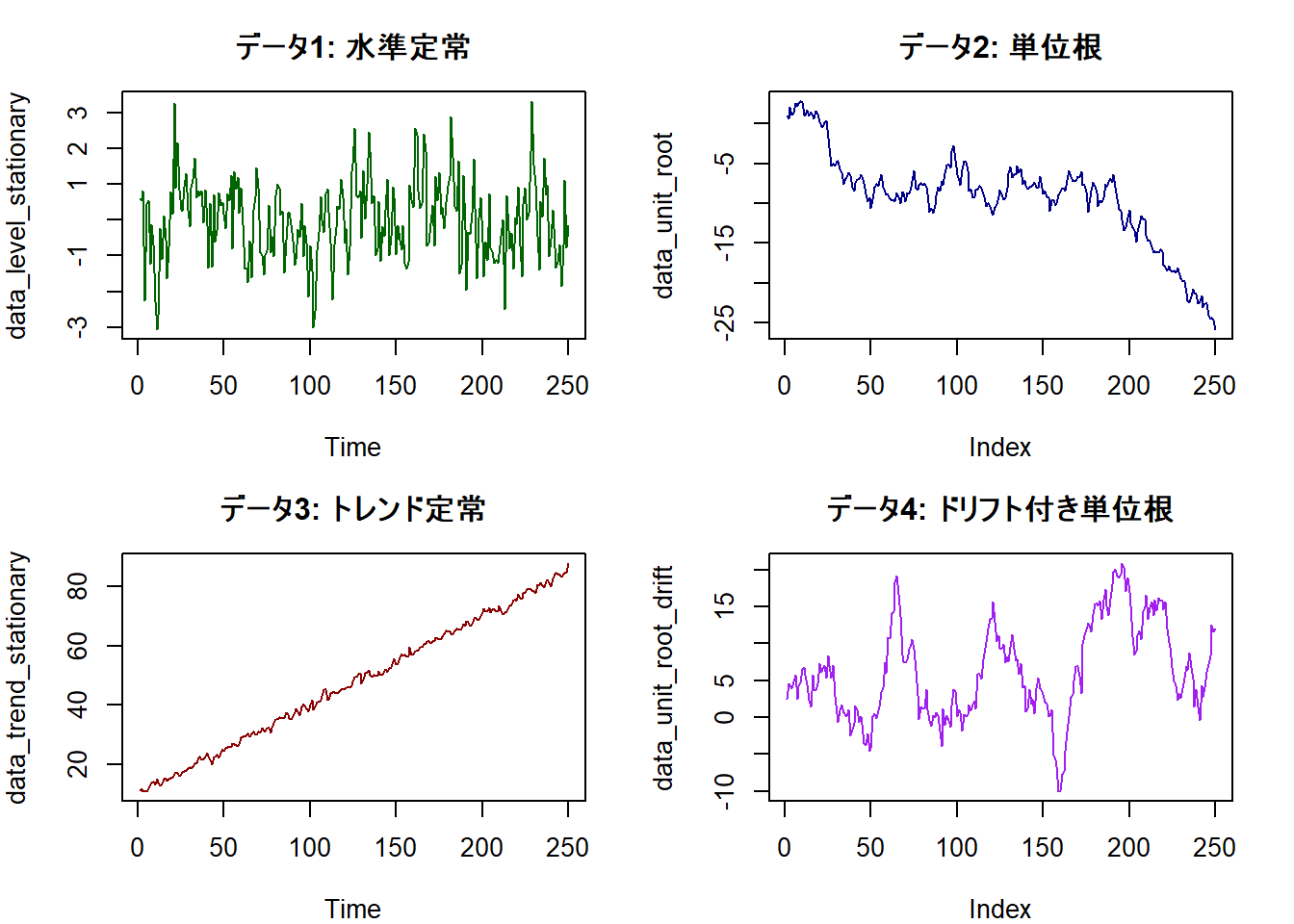
# --- ケース1: 水準定常データ ---
cat("--- ケース1:水準定常データに null='Level' で検定 ---\n")
# データは定常ですので、帰無仮説「水準定常である」は棄却されないと予測されます。
kpss_result1 <- kpss.test(data_level_stationary, null = "Level")
print(kpss_result1)--- ケース1:水準定常データに null='Level' で検定 ---
KPSS Test for Level Stationarity
data: data_level_stationary
KPSS Level = 0.093734, Truncation lag parameter = 5, p-value = 0.1 kpss.test検定結果の確認
この出力は、水準定常な過程として意図的に生成された data_level_stationary に対して、null = "Level"(水準定常性)を帰無仮説としてKPSS検定を実行した結果です。
KPSS Test for Level Stationarity
data: data_level_stationary
KPSS Level = 0.093734, Truncation lag parameter = 5, p-value = 0.1各項目の確認
KPSS Test for Level Stationarity実行された検定がKPSS検定であること、そして帰無仮説が水準定常性(Level Stationarity)であることを示しています。これは
null = "Level"を指定したことに対応します。data: data_level_stationary検定に使用されたデータが
data_level_stationaryという名前のオブジェクトであることを示しています。KPSS Level = 0.093734こちらがKPSS検定の検定統計量です。この統計量は、データが(水準)定常であるという帰無仮説からどれだけ逸脱しているかを示す指標です。この値が小さいほど、データは帰無仮説(定常性)と整合的であることを意味します。
Truncation lag parameter = 5検定統計量を計算する過程で使用されるラグの切り捨てパラメータが
5に設定されたことを示しています。このパラメータは、誤差項の長期的な分散を推定するために内部的に使用される値で、データの長さ(250)から自動的に計算されています。p-value = 0.1p値は、検定結果から結論を導くための指標です。
0.1という値が出力されています。KPSS検定におけるp値は、「もし帰無仮説(データは定常である)が真実である場合に、観測された検定統計量と同等か、それ以上に大きな値が得られる確率」を意味します。
結論の導出
KPSS検定は、ADF検定やPP検定とは帰無仮説が逆であるため、結論の解釈には注意が必要です。
- 帰無仮説 (H₀): データは水準定常である。
- 対立仮説 (H₁): データは単位根を持つ(非定常である)。
- 判断ルール:
p値 < 有意水準であれば、帰無仮説を棄却する(非定常であると判断する)。
今回の結果を見てみましょう。
- p値:
0.1 - 設定した有意水準:
0.05
0.1 > 0.05ですので、p値は有意水準よりも大きいです。
ですので、帰無仮説「データは水準定常である」を棄却することはできません。
この検定結果は、データが定常であるという仮説と矛盾しないことを示しています。今回のデータは実際に定常な時系列として生成したものですので、KPSS検定がデータの性質を正しく捉えていることが確認できます。
なお、p値の最大値は0.1として出力される仕様です。
今回の検定過程において、
警告メッセージ:
kpss.test(data_level_stationary, null = "Level") で:
p-value greater than printed p-valueと出力されていますので、p-value = 0.1は「p値は0.1以上である」と解釈します。
# --- ケース2: 単位根データ ---
cat("--- ケース2:単位根データに null='Level' で検定 ---\n")
# データは非定常ですので、帰無仮説「水準定常である」は棄却されると予測されます。
kpss_result2 <- kpss.test(data_unit_root, null = "Level")
print(kpss_result2)--- ケース2:単位根データに null='Level' で検定 ---
KPSS Test for Level Stationarity
data: data_unit_root
KPSS Level = 0.92541, Truncation lag parameter = 5, p-value = 0.01 kpss.test検定結果の確認
この出力は、非定常な単位根過程(ランダムウォーク)として生成された data_unit_root に対して、null = "Level"(水準定常性)を帰無仮説としてKPSS検定を実行した結果です。
KPSS Test for Level Stationarity
data: data_unit_root
KPSS Level = 0.92541, Truncation lag parameter = 5, p-value = 0.01各項目の確認
KPSS Test for Level Stationarity実行された検定がKPSS検定であり、帰無仮説が水準定常性(Level Stationarity)であることを示しています。
data: data_unit_root検定に使用されたデータが
data_unit_rootという名前のオブジェクトであることを示しています。KPSS Level = 0.92541KPSS検定の検定統計量です。この値が大きいほど、データが帰無仮説である「定常性」から逸脱していることを意味します。先の定常データでの結果(0.093734)と比較して、この
0.92541という値は大きくなっており、データが非定常であることを示唆しています。Truncation lag parameter = 5検定統計量の計算に使用されるラグの切り捨てパラメータが
5に設定されたことを示しています。p-value = 0.01検定結果から結論を導くためのp値です。こちらの結果が、
0.01であるということは、「もしデータが定常であったとしたら、観測された検定統計量0.92541が得られる確率は、1%である」ということを意味します。
結論の導出
KPSS検定の逆の仮説設定になります。
- 帰無仮説 (H₀): データは水準定常である。
- 対立仮説 (H₁): データは単位根を持つ(非定常である)。
- 判断ルール:
p値 < 有意水準であれば、帰無仮説を棄却する(非定常であると判断する)。
今回の結果を見てみましょう。
- p値:
0.01 - 設定した有意水準:
0.05
0.01 < 0.05ですので、p値は有意水準よりも小さいです。
ですので、帰無仮説「データは水準定常である」を棄却します。
この検定結果は、対立仮説である「データは単位根を持つ(非定常である)」ことを支持します。今回のデータは実際に非定常な単位根過程として生成したものですので、整合が取れていることになります。
なお、p値の最小値は0.01として出力される仕様です。
今回の検定過程において、
警告メッセージ:
kpss.test(data_unit_root, null = "Level") で:
p-value smaller than printed p-valueと出力されていますので、p-value = 0.01は「p値は0.01以下である」と解釈します。
# --- ケース3: トレンド定常データ ---
cat("--- ケース3:トレンド定常データに null='Trend' で検定 ---\n")
# データはトレンド定常ですので、帰無仮説「トレンド定常である」は棄却されないと予測されます。
kpss_result3 <- kpss.test(data_trend_stationary, null = "Trend")
print(kpss_result3)--- ケース3:トレンド定常データに null='Trend' で検定 ---
KPSS Test for Trend Stationarity
data: data_trend_stationary
KPSS Trend = 0.048406, Truncation lag parameter = 5, p-value = 0.1 kpss.test検定結果の確認
この出力は、トレンド定常な過程として意図的に生成された data_trend_stationary に対して、null = "Trend"(トレンド定常性)を帰無仮説としてKPSS検定を実行した結果です。
KPSS Test for Trend Stationarity
data: data_trend_stationary
KPSS Trend = 0.048406, Truncation lag parameter = 5, p-value = 0.1各項目の確認
KPSS Test for Trend Stationarity実行された検定がKPSS検定であること、そして帰無仮説がトレンド定常性(Trend Stationarity)であることを示しています。これは
null = "Trend"を指定したことに対応します。data: data_trend_stationary検定に使用されたデータが
data_trend_stationaryという名前のオブジェクトであることを示しています。KPSS Trend = 0.048406こちらがKPSS検定の検定統計量です。
KPSS Trendという名称は、null="Trend"が指定されたことを反映しています。この統計量は、データが「トレンド定常である」という帰無仮説からどれだけ逸脱しているかを示す指標です。この値が小さいほど、データは帰無仮説(トレンド定常性)と整合的であることを意味します。Truncation lag parameter = 5検定統計量の計算に使用されるラグの切り捨てパラメータが
5に設定されたことを示しています。p-value = 0.1検定結果から結論を導くためのp値です。
0.1という値が出力されています。これは、KPSS検定が出力するp値の上限値です。
結論の導出
KPSS検定の仮説設定はADF/PP検定とは逆です。
- 帰無仮説 (H₀): データはトレンド定常である。
- 対立仮説 (H₁): データは単位根を持つ(非定常である)。
- 判断ルール:
p値 < 有意水準であれば、帰無仮説を棄却する(非定常であると判断する)。
今回の結果を見てみましょう。
- p値:
0.1 - 設定した有意水準:
0.05
0.1 > 0.05ですので、p値は有意水準よりも大きいです。
ですので、帰無仮説「データはトレンド定常である」を棄却することはできません。
この検定結果は、データがトレンド定常であるという仮説と矛盾しないことを示しています。今回のデータは実際にトレンド定常な時系列として生成したものですので、KPSS検定がデータの性質を正しく捉え、「定常である」という帰無仮説は棄却されないことを確認できます。
# --- ケース4: ドリフト付き単位根データ ---
cat("--- ケース4:ドリフト付き単位根データに null='Trend' で検定 ---\n")
# データは非定常ですので、帰無仮説「トレンド定常である」は棄却されると予測されます。
kpss_result4 <- kpss.test(data_unit_root_drift, null = "Trend")
print(kpss_result4)--- ケース4:ドリフト付き単位根データに null='Trend' で検定 ---
KPSS Test for Trend Stationarity
data: data_unit_root_drift
KPSS Trend = 0.59469, Truncation lag parameter = 5, p-value = 0.01 kpss.test検定結果の確認
この出力は、data_unit_root_drift(ドリフト付き単位根過程)に対して、null = "Trend"(トレンド定常性)を帰無仮説としてKPSS検定を実行した結果です。
KPSS Test for Trend Stationarity
data: data_unit_root_drift
KPSS Trend = 0.59469, Truncation lag parameter = 5, p-value = 0.01各項目の確認
KPSS Test for Trend Stationarity実行された検定がKPSS検定であり、帰無仮説がトレンド定常性(Trend Stationarity)であることを示しています。
data: data_unit_root_drift検定に使用されたデータが
data_unit_root_driftであることを示しています。KPSS Trend = 0.59469KPSS検定の検定統計量です。
Truncation lag parameter = 5検定統計量の計算に使用されるラグの切り捨てパラメータが
5に設定されたことを示しています。p-value = 0.01検定結果から結論を導くためのp値です。
0.01という結果は、「もしデータがトレンド定常であったとしたら、観測された検定統計量0.59469が得られる確率は、1%である」ということを意味します。
結論の導出
KPSS検定の逆の仮説設定を再度確認します。
- 帰無仮説 (H₀): データはトレンド定常である。
- 対立仮説 (H₁): データは単位根を持つ(非定常である)。
- 判断ルール:
p値 < 有意水準であれば、帰無仮説を棄却する(非定常であると判断する)。
今回の結果を見てみましょう。
- p値:
0.01 - 設定した有意水準:
0.05
0.01 < 0.05ですので、p値は有意水準よりも明確に小さいです。
ですので、帰無仮説「データはトレンド定常である」を棄却します。実際に非定常なデータを生成していますので、検定結果は整合が取れていることになります。
以上です。

