
Rの関数から difference_in_means {estimatr} を確認します。
本ポストはこちらの続きです。

関数 difference_in_means とは
difference_in_means は、2つのグループ間(処置群と対照群など)の平均値の差(Average Treatment Effect: ATE)を推定するための関数です。
Rの標準的な t.test 関数と似ていますが、difference_in_means はデザインベースの推論(Design-Based Inference)、特にネイマン(Neyman)の枠組みに基づいている点が異なります。
実験デザインにおける「クラスター化(Clustering)」、「ブロック化(Blocking / Stratification)」、「重み付け(Weighting)」、「ペアマッチング」を明示的に考慮し、不均一分散(Heteroskedasticity)に対して頑健な標準誤差を計算します。
関数 difference_in_means の引数
library(estimatr)
args(difference_in_means)function (formula, data, blocks, clusters, weights, subset, se_type = c("default",
"none"), condition1 = NULL, condition2 = NULL, ci = TRUE,
alpha = 0.05)
NULL-
formula- 解析モデルを指定する式です。形式は
outcome ~ treatment(被説明変数 ~ 処置変数)となります。 - 右辺(説明変数)は1つの変数のみである必要があります。重回帰分析を行う関数ではないためです。
- 比較したい結果と、グループ分けの変数を定義します。
- 解析モデルを指定する式です。形式は
-
data-
formulaで指定された変数を含むデータフレームです。 - 解析対象のデータセットを渡します。
-
-
blocks- ブロック(層化)変数を指定します。
- 実験がブロック化無作為化(層化無作為化)で行われた場合、当該変数を指定することで、ブロックごとの変動を除去し、推定精度を向上させます。ブロック内で推定値を計算し、それをサンプルサイズで加重平均して全体の効果を算出します。
-
clusters- クラスター変数を指定します。
- 実験がクラスター無作為化(例:個人ではなく学校や村単位での割り付け)で行われた場合、観測値間の相関を考慮して標準誤差(クラスターロバスト標準誤差)を計算します。
-
weights- 重み付け変数を指定します。
- 調査のサンプリングウェイトや、逆確率重み付け(IPW)などを用いる場合に指定します。
-
subset- 分析に使用するデータのサブセット条件を指定します。
- データをフィルタリングして分析する場合に使用します(例:女性のみ、特定の地域のみなど)。
-
se_type- 標準誤差の計算方法を指定する文字列です。
- デフォルト:
"default"(通常、不均一分散を考慮したHC2や、クラスターがある場合はCR2が自動選択されます)。 - 選択肢:
"none","HC0","HC1","HC2","HC3","stata","CR0","CR2"など。 - 分析の前提に応じた分散推定法を選択します。
-
condition1,condition2- 比較する2つの条件(水準)を明示的に指定します。
- デフォルト:
NULL(自動的にデータから2つの値を検出します)。 - 処置変数が3つ以上の水準を持つ場合や、基準となる群(コントロール群)を明確に指定したい場合に使用します。通常、
condition1がコントロール(参照群)、condition2がトリートメント(処置群)となります。
-
ci- 信頼区間を計算するかどうかの論理値です。
- デフォルト:
TRUE
-
alpha- 有意水準を指定する数値です。
- デフォルト:
0.05(95%信頼区間)。
シミュレーションコード
以下に、difference_in_means の機能を確認するためのサンプルデータを用いたシミュレーションコードを示します。
このシミュレーションでは、「新しい教育プログラムの効果測定」というシナリオを設定します。
実験デザインとして、単なるランダム化ではなく、「ブロック化(地域)」と「クラスター化(クラス単位)」の双方が行われたケースを作成します。
このデータに対し、通常のt検定を行った場合と、difference_in_means でデザインを考慮した場合の違いを比較します。
なお、有意水準は5%とします。
シミュレーションデータの生成
# パッケージの読み込み
library(ggplot2)
library(dplyr)
# 乱数シードの固定
seed <- 20251212
set.seed(seed)
# 設定: 教育プログラムの実験
# 地域(ブロック): 都市部 (Urban) と 地方部 (Rural)
# クラスター: 学校のクラス単位でプログラムを導入するか決定
# 個人: 生徒
# パラメータ設定
n_blocks <- 2 # 都市部、地方部
n_clusters_per_block <- 20 # 各地域に20クラスずつ
n_students_per_cluster <- 15 # 1クラス15人
Total_N <- n_blocks * n_clusters_per_block * n_students_per_cluster
# データの骨組み作成
data_sim <- data.frame(
block_id = rep(c("都市部", "地方部"), each = n_clusters_per_block * n_students_per_cluster),
cluster_id = rep(1:(n_blocks * n_clusters_per_block), each = n_students_per_cluster)
)
# 処置の割り当て
cluster_treatment <- data_sim %>%
group_by(block_id, cluster_id) %>%
summarise(temp = 1, .groups = "drop") %>%
group_by(block_id) %>%
mutate(treatment = sample(rep(c(0, 1), length.out = n()))) %>%
ungroup() %>%
select(cluster_id, treatment)
# データを結合
data_sim <- left_join(data_sim, cluster_treatment, by = "cluster_id")
# 変数の生成
base_score_block <- ifelse(data_sim$block_id == "都市部", 60, 50)
cluster_noise_vals <- rnorm(n_blocks * n_clusters_per_block, mean = 0, sd = 5)
data_sim$cluster_noise <- cluster_noise_vals[data_sim$cluster_id]
individual_noise <- rnorm(Total_N, mean = 0, sd = 8)
true_effect <- 5
data_sim$score <- base_score_block +
(true_effect * data_sim$treatment) +
data_sim$cluster_noise +
individual_noise
data_sim$treatment_label <- ifelse(data_sim$treatment == 1, "実施あり", "実施なし")
cat("--- データの一部を確認 ---\n")
print(str(data_sim))
cat("\n--- データ概要 ---\n")
cat(sprintf("総観測数: %d 人\n", nrow(data_sim)))
cat(sprintf("ブロック数: %d (都市部, 地方部)\n", length(unique(data_sim$block_id))))
cat(sprintf("クラスター数: %d (クラス単位)\n", length(unique(data_sim$cluster_id))))
cat(sprintf("真の処置効果: %+.1f 点", true_effect))
# データの可視化
p1 <- ggplot(data_sim, aes(x = treatment_label, y = score, fill = treatment_label)) +
geom_boxplot(alpha = 0.6) +
facet_wrap(~block_id) +
labs(
title = "地域(ブロック)ごとのテストスコア分布",
subtitle = "都市部の方が全体的に点数が高い(ブロック差)。処置群の方が点数が高い傾向。",
x = "プログラム実施状況",
y = "テストスコア"
) +
theme_minimal() +
theme(legend.position = "none")
print(p1)--- データの一部を確認 ---
'data.frame': 600 obs. of 6 variables:
$ block_id : chr "都市部" "都市部" "都市部" "都市部" ...
$ cluster_id : int 1 1 1 1 1 1 1 1 1 1 ...
$ treatment : num 1 1 1 1 1 1 1 1 1 1 ...
$ cluster_noise : num 1.92 1.92 1.92 1.92 1.92 ...
$ score : num 77.6 71.9 74.1 63.1 76 ...
$ treatment_label: chr "実施あり" "実施あり" "実施あり" "実施あり" ...
NULL
--- データ概要 ---
総観測数: 600 人
ブロック数: 2 (都市部, 地方部)
クラスター数: 40 (クラス単位)
真の処置効果: +5.0 点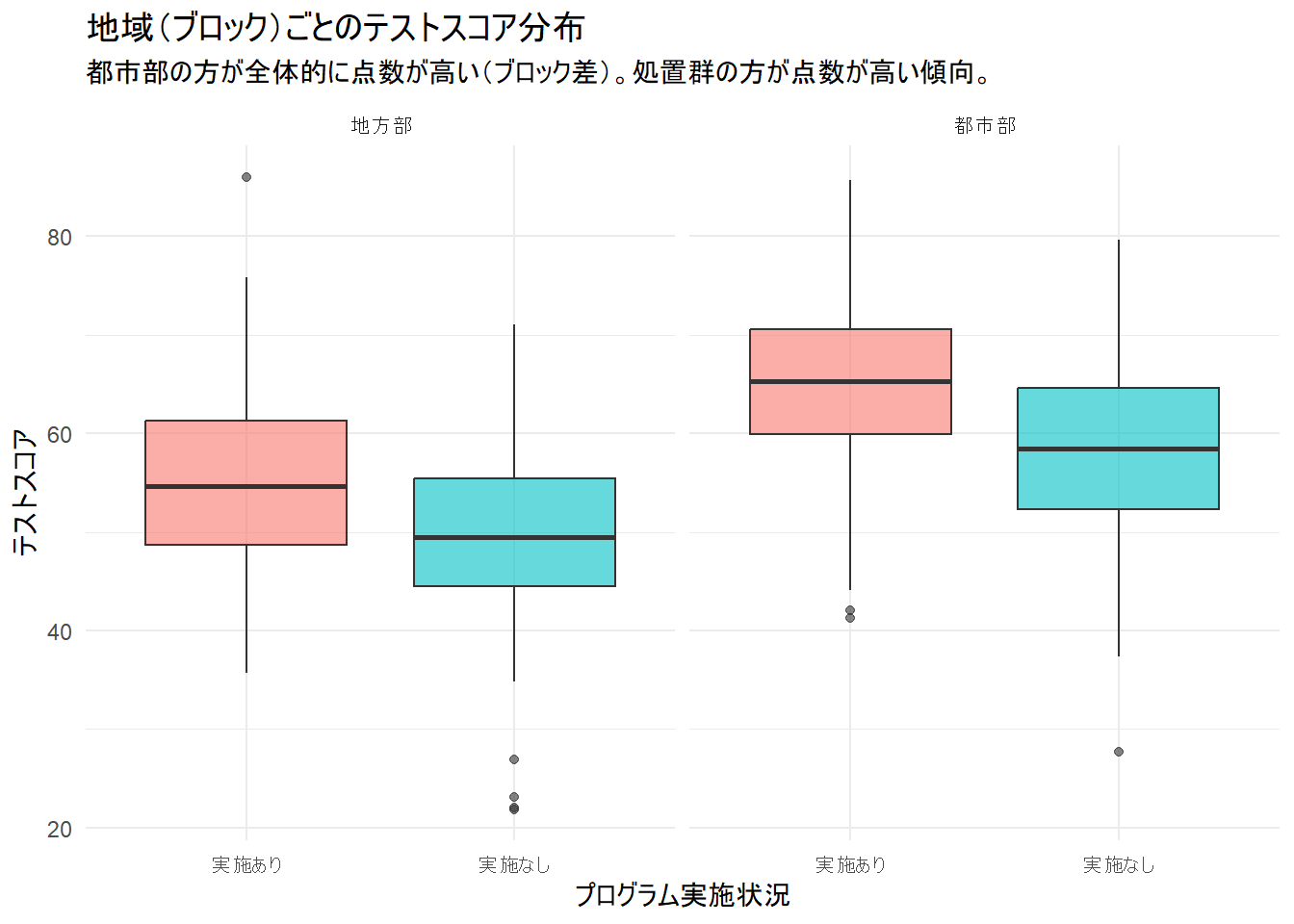
分析1: 通常のt検定(デザイン無視)
t_test_res <- t.test(score ~ treatment, data = data_sim, var.equal = FALSE)
# 結果の表示
print(t_test_res)
cat("------------------------------------------------------------\n")
cat("推定された差 (平均): ", diff(t_test_res$estimate), "\n")
cat("p値: ", format.pval(t_test_res$p.value), "\n")
cat("95%信頼区間: [", t_test_res$conf.int[2] * -1, ", ", t_test_res$conf.int[1] * -1, "]\n")
Welch Two Sample t-test
data: score by treatment
t = -7.3634, df = 597.95, p-value = 5.97e-13
alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
95 percent confidence interval:
-7.620678 -4.411482
sample estimates:
mean in group 0 mean in group 1
54.12970 60.14578
------------------------------------------------------------
推定された差 (平均): 6.01608
p値: 5.9697e-13
95%信頼区間: [ 4.411482 , 7.620678 ]分析2: difference_in_means(デザイン考慮)
dim_res <- difference_in_means(
formula = score ~ treatment,
data = data_sim,
blocks = block_id, # 地域による層化
clusters = cluster_id # クラス単位の相関
)
# 結果の表示
print(dim_res)
cat("------------------------------------------------------------\n")
# 結果の抽出
coef_val <- dim_res$coefficients
se_val <- dim_res$std.error
ci_lower <- dim_res$conf.low
ci_upper <- dim_res$conf.high
design_info <- dim_res$design
cat(sprintf("デザイン: %s\n", design_info))
cat(sprintf("推定値 (Estimate): %f\n", coef_val))
cat(sprintf("標準誤差 (Std. Error): %f\n", se_val))
cat(sprintf("95%%信頼区間: [%f, %f]\n", ci_lower, ci_upper))Design: Block-clustered
Estimate Std. Error t value Pr(>|t|) CI Lower CI Upper DF
treatment 6.01608 1.515765 3.969007 0.0003299954 2.941967 9.090193 36
------------------------------------------------------------
デザイン: Block-clustered
推定値 (Estimate): 6.016080
標準誤差 (Std. Error): 1.515765
95%信頼区間: [2.941967, 9.090193]結果の比較
推定値(Estimate)の一致
両者の処置効果の推定値(Estimate)は以下の通り、一致しています。
- 通常のt検定: 平均の差は約 6.01608
- difference_in_means: 推定値は 6.01608
これは、両手法ともに「処置群の平均 - 対照群の平均」という基本的な計算を行っているためです。
標準誤差(Std. Error)と自由度(DF)の乖離
- 通常のt検定:
- 標準誤差: 明示されていませんが、\(t = \text{Est} / \text{SE}\) の関係から逆算すると、\(\approx 0.817\) となります。
- 自由度 (df): 597.95
- 解釈: 「600人の生徒全員が独立した情報源である」と仮定しているため、標準誤差を、
difference_in_meansと比較して、小さく見積もり、自由度をサンプルサイズ数(約600)として計算しています。
- difference_in_means:
- 標準誤差: 1.5158 (t検定の約1.85倍)
- 自由度 (DF): 36
- 解釈: 「情報は生徒数(600)ではなく、クラスター数(40クラス)に依存する」と認識しています。同じクラスの生徒は似た傾向を持つ(相関がある)ため、有効な情報量は生徒数よりもずっと少なくなります。それゆえ、標準誤差は補正され、自由度はクラスター数に基づいた 36 まで減少しました。
信頼区間(CI)とp値の更新
標準誤差と自由度の修正は、信頼区間とp値に影響を与えます。
- 信頼区間:
- 通常のt検定:
[4.411, 7.621](幅: 約3.2) - difference_in_means:
[2.942, 9.090](幅: 約6.1)
- 通常のt検定:
- p値:
- 通常のt検定:
5.97e-13 - difference_in_means:
0.00033 - 今回のシミュレーションでは、どちらも設定した有意水準を下回っていますが、もし真の効果がもっと小さく、例えば
通常のt検定のp値が0.049と有意水準未満、difference_in_meansのp値が0.085と有意水準を超えるような場合、difference_in_meansでは「帰無仮説は棄却できない」と、正しい結論に収まりますが、t検定では「有意」と誤認されてしまいます。
- 通常のt検定:
t検定における標準誤差の産出
方法1: t.testの結果オブジェクトから抽出
# t.testの戻り値には "stderr" という要素が含まれています
se_extracted <- t_test_res$stderr
cat("方法1:t.testオブジェクトから抽出:\n")
cat(sprintf("標準誤差: %.10f\n\n", se_extracted))方法1:t.testオブジェクトから抽出:
標準誤差: 0.8170302847方法2: 生データからWelchの公式で手計算
# 各群のデータを抽出
group_0 <- subset(data_sim, treatment == 0)$score
group_1 <- subset(data_sim, treatment == 1)$score
# 各群の統計量を計算
n0 <- length(group_0) # サンプルサイズ
v0 <- var(group_0) # 不偏分散
n1 <- length(group_1)
v1 <- var(group_1)
# Welchのt検定における標準誤差の公式
# SE = sqrt( (s1^2 / n1) + (s2^2 / n2) )
se_calculated <- sqrt((v0 / n0) + (v1 / n1))
cat("方法2:公式に基づく手計算:\n")
cat(sprintf("群0 (n=%d, var=%.3f)\n", n0, v0))
cat(sprintf("群1 (n=%d, var=%.3f)\n", n1, v1))
cat(sprintf("計算された標準誤差: %.10f\n\n", se_calculated))方法2:公式に基づく手計算:
群0 (n=300, var=101.054)
群1 (n=300, var=99.208)
計算された標準誤差: 0.8170302847以上です。

