
Rの関数から barNest {plotrix} を確認します。
関数 barNest とは
barNest は、階層構造(入れ子構造)を持つカテゴリデータの統計量を、視覚的に整理された棒グラフとして表現する関数です。
本関数は、複数のカテゴリ変数によって細分化されるデータの平均値や分散といった要約統計量を、親グループの中に子グループが収まるようなレイアウトで描画します。
内部的には brkdnNest 関数を用いてデータを階層ごとに集計し、その結果を基に drawNestedBars 関数がグラフィカルな出力を生成します。
下位の階層ほど棒の幅を細く設定する「収縮(shrink)」機能により、データの包含関係を直感的に提示することが可能です。
関数 barNest の活用シーン
- 組織構造別の実績比較:
- 本部、部、課といった階層構造を持つ組織において、各ユニットのパフォーマンス指標を上位組織の数値と比較しながら一画面で確認したい場合。
- 多因子実験の分析結果表示:
- 複数の実験因子が組み合わさった複雑なデータセットにおいて、主要な要因とそれらに付随する副次的要因の影響を階層的に図示したい場合。
- 不均衡データの視覚的評価:
-
Nwidths引数を用いて各棒の幅をサンプルサイズに比例させることで、各グループのデータの重みを視覚的に把握したい場合。
-
関数 barNest の引数
library(plotrix)
args(barNest)function (formula = NULL, data = NULL, FUN = c("mean", "sd",
"sd", "valid.n"), ylim = NULL, main = "", xlab = "", ylab = "",
shrink = 0.1, errbars = FALSE, col = NA, labelcex = 1, lineht = NULL,
showall = TRUE, Nwidths = FALSE, barlabels = NULL, showlabels = TRUE,
mar = NULL, arrow.cap = NULL, trueval = TRUE)
NULL- formula
-
応答変数 ~ カテゴリ変数1 + カテゴリ変数2 + ...の形式で、集計の対象と階層の順序を指定します。
-
- data
- 解析に使用するデータフレームを指定します。
- FUN
- 各階層で算出する統計関数のベクトルを指定します。通常は平均、標準誤差、サンプルサイズなどが用いられます。
- errbars
- 誤差範囲(エラーバー)を表示するかどうかを論理値で制御します。
- col
- 棒の色を指定します。リスト形式を用いる場合は各階層の要素数と整合させる必要があります。
- shrink
- 下位階層の棒の幅を縮小させる割合を指定し、階層の深さを表現します。
- Nwidths
- サンプルサイズに基づいて棒の幅を変動させるかどうかを論理値で指定します。
- labelcex
- 階層ラベルの文字サイズを調整します。
- trueval
- 欠損値を含む水準の扱いを制御します。
サンプルコード
# 1. 不均等なサンプルサイズを持つデータの生成
# 各グループのN数を極端に変えて設定します
# (東部:5, 25, 10人 / 西部:40, 5, 15人)
n_sizes <- c(5, 25, 10, 40, 5, 15)
area_labels <- rep(c("東部地区", "西部地区"), each = 40) # 合計80件だが内部で調整
sample_data_unbalanced <- data.frame(
Area = c(rep("東部地区", 40), rep("西部地区", 60)),
Store = c(
rep("店舗A", 5), rep("店舗B", 25), rep("店舗C", 10),
rep("店舗A", 40), rep("店舗B", 5), rep("店舗C", 15)
),
Sales = rnorm(100, mean = 500, sd = 100)
)
cat("--- サンプルデータの一部を確認 ---\n")
print(str(sample_data_unbalanced))--- サンプルデータの一部を確認 ---
'data.frame': 100 obs. of 3 variables:
$ Area : chr "東部地区" "東部地区" "東部地区" "東部地区" ...
$ Store: chr "店舗A" "店舗A" "店舗A" "店舗A" ...
$ Sales: num 448 502 525 514 337 ...
NULL# 2. 階層ごとの色リストを定義
nest_col_list <- list(
"snow2", # 全体(第1階層)
c("honeydew1", "lavenderblush1"), # 地区(第2階層:2要素)
c("aquamarine", "coral", "plum1") # 店舗(第3階層:3要素)
)
# 3. グラフの描画
barNest(
formula = Sales ~ Area + Store,
data = sample_data_unbalanced,
FUN = c("mean", "sd", "sd", "valid.n"),
errbars = TRUE,
Nwidths = TRUE, # サンプルサイズに応じて棒の幅を変動させます
col = nest_col_list,
main = "全地区、地区ごと、店舗ごとの売上統計",
ylab = "平均売上高(±標準偏差)",
shrink = 0.15,
labelcex = 0.8
)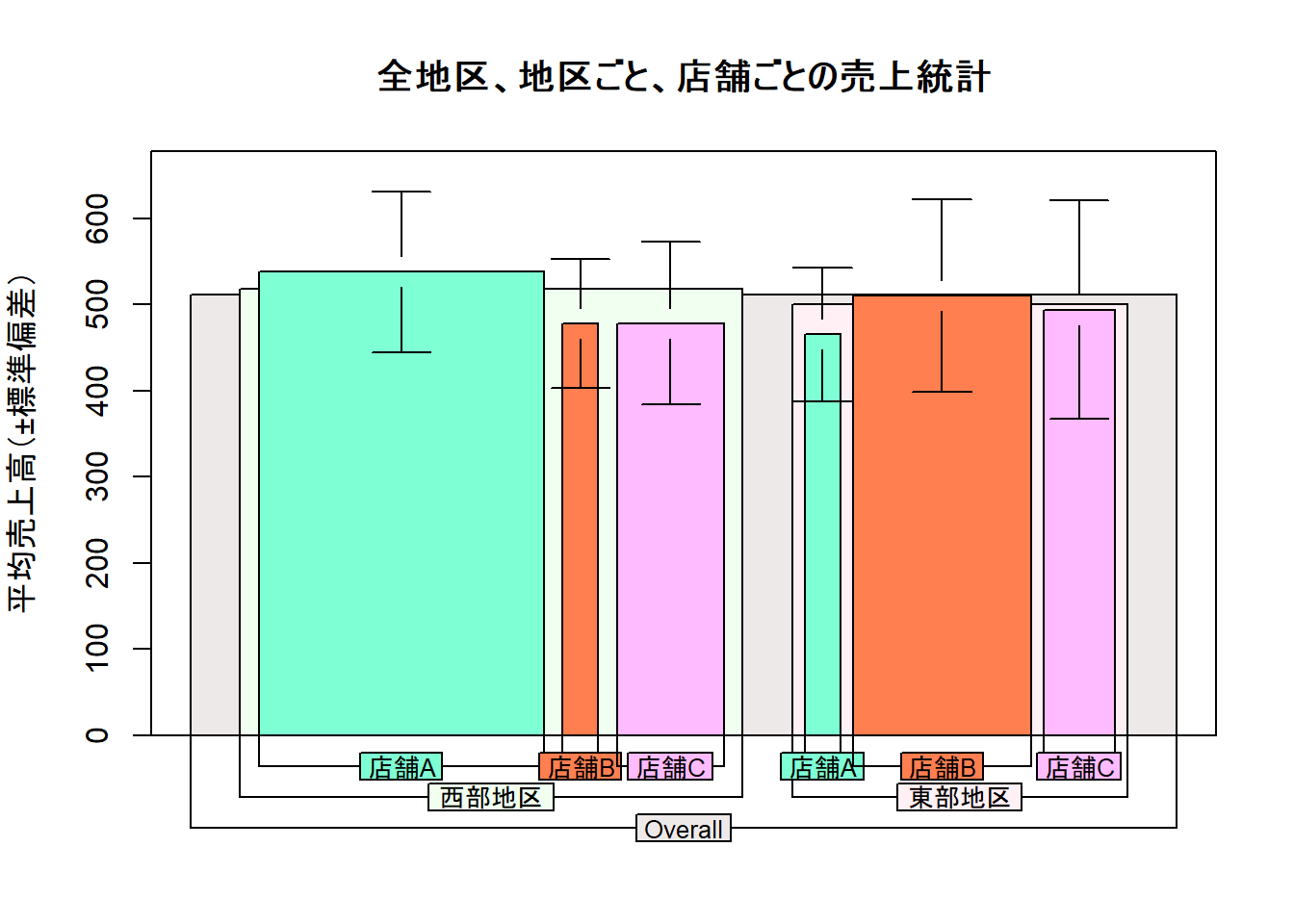
Figure 1 の読み方
引数 Nwidths = TRUE の指定により、各グループの有効データ数(\(N\))に比例して棒の幅が決定されています。
例えば、西部地区の店舗A や 東部地区の店舗B は、横幅が広く描画されています。
本表現は、他の店舗と比較して多くの標本(データ数)に基づいた統計量であることを示しており、算出された平均値の信頼性が相対的に高いことを視覚的に伝達しています。
一方で、西部地区の店舗B や 東部地区の店舗A は、棒の幅が狭く制限されています。
こちらも同様に、少数の標本から導き出された平均値であることを警告する役割を果たしています。
サンプルサイズが小さいグループは、個別の異常値によって平均値が大きく左右されやすいため、当該の視覚的特徴は「この数値の解釈には慎重な判断が必要である」という統計的な示唆を見るものに与えます。
また、下部に配置されたラベル(Overall > 地区 > 店舗)の階層構造に合わせ、彩色リストが適用されています。
上位階層の「Overall」から最下位階層の各店舗に至るまで、入れ子状に枠が重なるデザインにより、組織全体の売上構成の中に各個別の実績がどのように位置づけられているかが示されています。
サンプルコードのまとめ
Figure 1 は、以下の3つの情報を一画面に統合しています。
- 棒の高さ: 売上の平均値(パフォーマンスの良否)
- エラーバー: データのばらつき(標準偏差による安定性の評価)
- 棒の幅: データの重み(サンプルサイズによる信頼性の評価)
それゆえ、単一の指標のみでは見落としがちな「データ規模の偏り」を考慮した上で、各店舗の実績を多角的に比較することが可能となります。
以上です。

