
Rで サンプルサイズ設計:t検定(2群、対応なし、同じサンプルサイズ) を確認します。
1. シミュレーションのシナリオ
シナリオ:新開発サプリメントの血圧降下作用の検証
ある製薬会社が、軽度の高血圧症患者向けに、天然成分からなる新しいサプリメントを開発しました。このサプリメントが、プラセボ(偽薬)と比較して、収縮期血圧(上の血圧)を有意に低下させる効果があるかを検証するための臨床試験を計画しています。
- 研究の目的: 新サプリメント(介入群)は、プラセボ(対照群)と比較して、1か月後の収縮期血圧を臨床的に意味のあるレベルで低下させるか。
- 被験者: 軽度の高血圧症と診断された成人。
- 試験デザイン:
- 被験者をランダムに2つのグループに同数ずつ割り付けます。
- 介入群: 新しいサプリメントを1か月間毎日服用する。
- 対照群: 見た目や味が同じで有効成分の入っていないプラセボを1か月間毎日服用する。
- これは二重盲検試験であり、被験者も試験実施者もどちらが割り当てられたかを知りません。
サンプルサイズ設計のためのパラメータ設定:
- 有意水準 (α):
0.05(両側検定)に設定します。 - 検出力 (1 – β): サプリメントに本当に効果がある場合、その効果を80%の確率で見逃さないようにしたいので、
0.80に設定します。 - 効果量 (d):
- 過去の同様の研究から、この対象者群の収縮期血圧の標準偏差は σ = 12 mmHg であることが知られています。
- 臨床的に意味のある差として、プラセボ群より平均 6 mmHg 血圧が下がれば、このサプリメントは有効であると判断します。
- したがって、検出したい効果量は
d = |μ₁ - μ₂| / σ = 6 / 12 = 0.5(中程度の効果量)となります。
このシナリオに基づき、「各群に何人の被験者が必要か?」を計算し、その妥当性をシミュレーションによって検証します。
各パラメータの意味
- 有意水準 (α, alpha)
- 帰無仮説(H₀: 2群の母平均に差はない, μ₁ = μ₂)は棄却されるべきではないにもかかわらず、それを棄却してしまう確率(第1種の過誤)。
- 一般的に
α = 0.05に設定されますが、目的により異なります。
- 検出力 (Power, 1 – β)
- 対立仮説(H₁: 2群の母平均に差がある, μ₁ ≠ μ₂)が真であるときに、それを正しく検出できる確率。
βは第2種の過誤(差があることを見逃す確率)です。 - 一般的に
1 - β = 0.80や0.90に設定されますが、目的により異なります。
- 対立仮説(H₁: 2群の母平均に差がある, μ₁ ≠ μ₂)が真であるときに、それを正しく検出できる確率。
- 効果量 (Effect Size, d)
- 検出したい2群間の標準化された差の大きさで、Cohen’s dが用いられます。
-
d = |μ₁ - μ₂| / σ-
|μ₁ - μ₂|: 検出したい母平均の差の絶対値。 -
σ: 母標準偏差(2群で共通と仮定)。
-
- 効果量の大きさは、研究分野の知見や臨床的重要性に基づいて決定されます。
- 各群のサンプルサイズ (n)
- 今回は
n₁ = n₂ = nであり、このnを求めます。
- 今回は
これらのパラメータは、t検定統計量の確率分布(非心t分布)を介して関連付けられています。
等サンプルサイズの場合のt検定統計量は、以下の式で表されます。
t = (X̄₁ - X̄₂) / (s_p * sqrt(2/n))
ここで、
-
X̄₁,X̄₂は各群の標本平均 -
nは各群のサンプルサイズ -
s_pは2群の標準偏差を統合した「プールされた標準偏差」で、s_p = sqrt(((n-1)s₁² + (n-1)s₂²) / (n+n-2)) - 検定の自由度(df)は
2n - 2となります。
サンプルサイズ設計では、設定したα、1-β、dを満たすために必要な n を求めます。
2. R言語によるシミュレーションコード
まず、必要なライブラリを読み込みます。
library(pwr)
library(ggplot2)
library(dplyr)
seed <- 20250708ステップ1: シナリオに基づいたサンプルサイズの計算
Rのpwrパッケージにあるpwr.t.test関数を使用します。これは等サンプルサイズのt検定向け関数です。
cat("--- ステップ1: サンプルサイズの計算 ---\n")
# パラメータ設定
effect_size <- 0.5 # Cohen's d
sig_level <- 0.05 # 有意水準 alpha
power_level <- 0.80 # 検出力 1-beta
# サンプルサイズの計算
# nをNULLにすることで、必要なサンプルサイズ(各群)を計算させる
sample_size_calc <- pwr.t.test(
d = effect_size,
sig.level = sig_level,
power = power_level,
type = "two.sample", # 2群のt検定
alternative = "two.sided" # 両側検定
)
# 結果の表示
print(sample_size_calc)
# 必要なサンプルサイズ(各群)を取得(切り上げ)
n_required <- ceiling(sample_size_calc$n)
cat("\n")
cat(paste0("結論: 介入群、対照群それぞれに最低 ", n_required, " 人の参加者が必要です。\n"))--- ステップ1: サンプルサイズの計算 ---
Two-sample t test power calculation
n = 63.76561
d = 0.5
sig.level = 0.05
power = 0.8
alternative = two.sided
NOTE: n is number in *each* group
結論: 介入群、対照群それぞれに最低 64 人の参加者が必要です。計算結果から、各群に64人の参加者が必要であることがわかります。
ステップ2: 検出力のシミュレーション (対立仮説が真の場合)
計算で得られたサンプルサイズ(各群64人)を用いて、本当に検出力が80%程度になるかシミュレーションで確認します。
cat("--- ステップ2: 検出力のシミュレーション ---\n")
# シミュレーションのパラメータ設定
set.seed(seed) # 結果を再現可能にする
n_sim <- 10000 # シミュレーション回数
# シナリオの母集団パラメータ
mean_placebo <- 140 # 対照群(プラセボ)の平均血圧 (mmHg)
sd_bp <- 12 # 両群共通の標準偏差 (mmHg)
# 介入群の平均血圧(6mmHg低下)
mean_supplement <- mean_placebo - (effect_size * sd_bp)
# 結果を格納するベクトル
p_values_h1 <- numeric(n_sim)
# シミュレーションループ
for (i in 1:n_sim) {
# 1. 対立仮説が真である状況のデータを生成
# 介入群データ (新サプリ)
supplement_data <- rnorm(n = n_required, mean = mean_supplement, sd = sd_bp)
# 対照群データ (プラセボ)
placebo_data <- rnorm(n = n_required, mean = mean_placebo, sd = sd_bp)
# 2. Welchのt検定を実行(不等分散を仮定する)
t_test_result <- t.test(supplement_data, placebo_data, var.equal = FALSE)
# 3. p値を保存
p_values_h1[i] <- t_test_result$p.value
}
# シミュレーションによる検出力の計算
simulated_power <- mean(p_values_h1 < sig_level)
cat(paste0("\nシミュレーションによる検出力: ", round(simulated_power, 3), "\n"))--- ステップ2: 検出力のシミュレーション ---
シミュレーションによる検出力: 0.807シミュレーション結果は、目標とした検出力0.80に近い値(約0.807)となり、サンプルサイズ設計の妥当性が裏付けられました。
ステップ3: 検出力シミュレーション結果の可視化
cat("--- ステップ3: 検出力シミュレーション結果の可視化 ---\n")
# p値をデータフレームに変換
p_values_df_h1 <- data.frame(p_value = p_values_h1)
# ggplotでヒストグラムを作成
plot_power <- ggplot(p_values_df_h1, aes(x = p_value)) +
geom_histogram(binwidth = 0.05, fill = "skyblue", color = "black", boundary = 0) +
geom_vline(xintercept = sig_level, color = "red", linetype = "dashed", linewidth = 1) +
annotate("text",
x = 0.5, y = 4500,
label = paste("シミュレーションによる検出力 (p < 0.05) =", round(simulated_power, 3)),
color = "red", size = 5
) +
labs(
title = "p値の分布(対立仮説が真の場合)",
subtitle = paste0("各群のサンプルサイズ n=", n_required, ", 効果量d=", effect_size),
x = "p値",
y = "度数"
) +
theme_minimal() +
theme(plot.title = element_text(size = 16, face = "bold"))
print(plot_power)--- ステップ3: 検出力シミュレーション結果の可視化 ---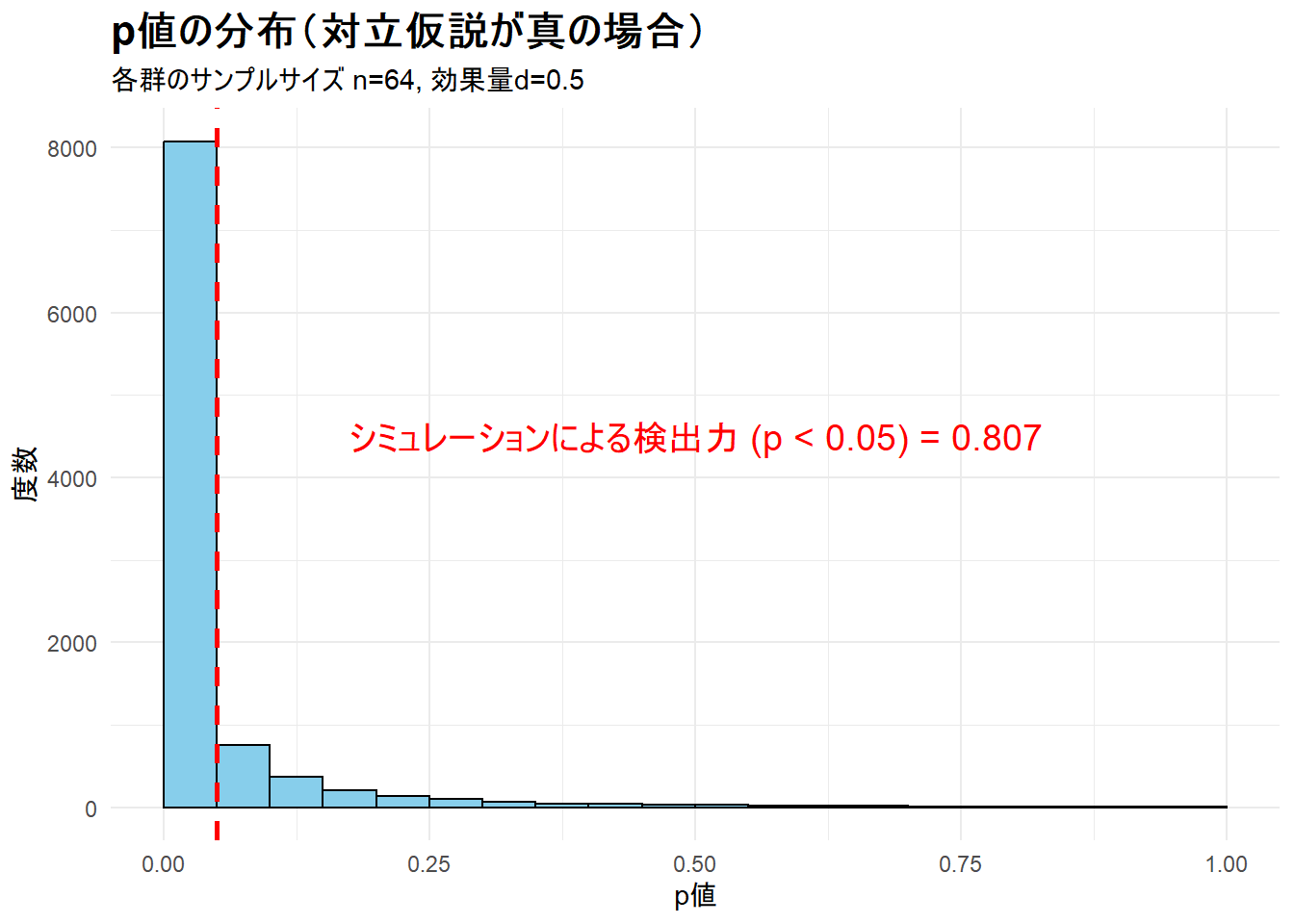
Figure 1 からp値が0に近い方に偏っており、有意水準0.05を下回る割合が約80%であることを視覚的に確認できます。
ステップ4: 第1種の過誤のシミュレーション (帰無仮説が棄却されない場合)
次に、サプリメントに全く効果がなかった場合(帰無仮説が棄却されない場合)に、誤って「効果あり」と結論づけてしまう確率(第1種の過誤率)が、設定した有意水準α (0.05) と一致するかを確認します。
cat("--- ステップ4: 第1種の過誤のシミュレーション ---\n")
set.seed(seed)
# 結果を格納するベクトル
p_values_h0 <- numeric(n_sim)
# シミュレーションループ (帰無仮説が棄却されない)
for (i in 1:n_sim) {
# 1. 帰無仮説が棄却されない状況のデータを生成 (平均血圧に差がない)
group1_data_h0 <- rnorm(n = n_required, mean = mean_placebo, sd = sd_bp)
group2_data_h0 <- rnorm(n = n_required, mean = mean_placebo, sd = sd_bp)
# 2. Welchのt検定を実行
t_test_result_h0 <- t.test(group1_data_h0, group2_data_h0, var.equal = FALSE)
# 3. p値を保存
p_values_h0[i] <- t_test_result_h0$p.value
}
# シミュレーションによる第1種の過誤率の計算
type1_error_rate <- mean(p_values_h0 < sig_level)
cat(paste("\nシミュレーションによる第1種の過誤率:", round(type1_error_rate, 3), "\n"))--- ステップ4: 第1種の過誤のシミュレーション ---
シミュレーションによる第1種の過誤率: 0.05 シミュレーションによる第1種の過誤率は、設定した有意水準0.05と一致し、検定が正しく機能していることがわかります。
ステップ5: 第1種の過誤シミュレーション結果の可視化
cat("--- ステップ5: 第1種の過誤シミュレーション結果の可視化 ---\n")
# p値をデータフレームに変換
p_values_df_h0 <- data.frame(p_value = p_values_h0)
# 期待される度数(一様分布の場合)
expected_freq <- n_sim * 0.05 # binwidth = 0.05の場合
# ggplotでヒストグラムを作成
plot_alpha <- ggplot(p_values_df_h0, aes(x = p_value)) +
geom_histogram(binwidth = 0.05, fill = "lightcoral", color = "black", boundary = 0) +
geom_vline(xintercept = sig_level, color = "blue", linetype = "dashed", linewidth = 1) +
geom_hline(yintercept = expected_freq, color = "darkgreen", linetype = "dotted", linewidth = 1) +
annotate("text",
x = 0.5, y = 600,
label = paste("第1種の過誤の確率 (p < 0.05) =", round(type1_error_rate, 3)),
color = "blue", size = 5
) +
labs(
title = "p値の分布(帰無仮説が棄却されない場合)",
subtitle = "p値は[0, 1]の範囲で一様に分布する",
x = "p値",
y = "度数"
) +
theme_minimal() +
theme(plot.title = element_text(size = 16, face = "bold"))
print(plot_alpha)--- ステップ5: 第1種の過誤シミュレーション結果の可視化 ---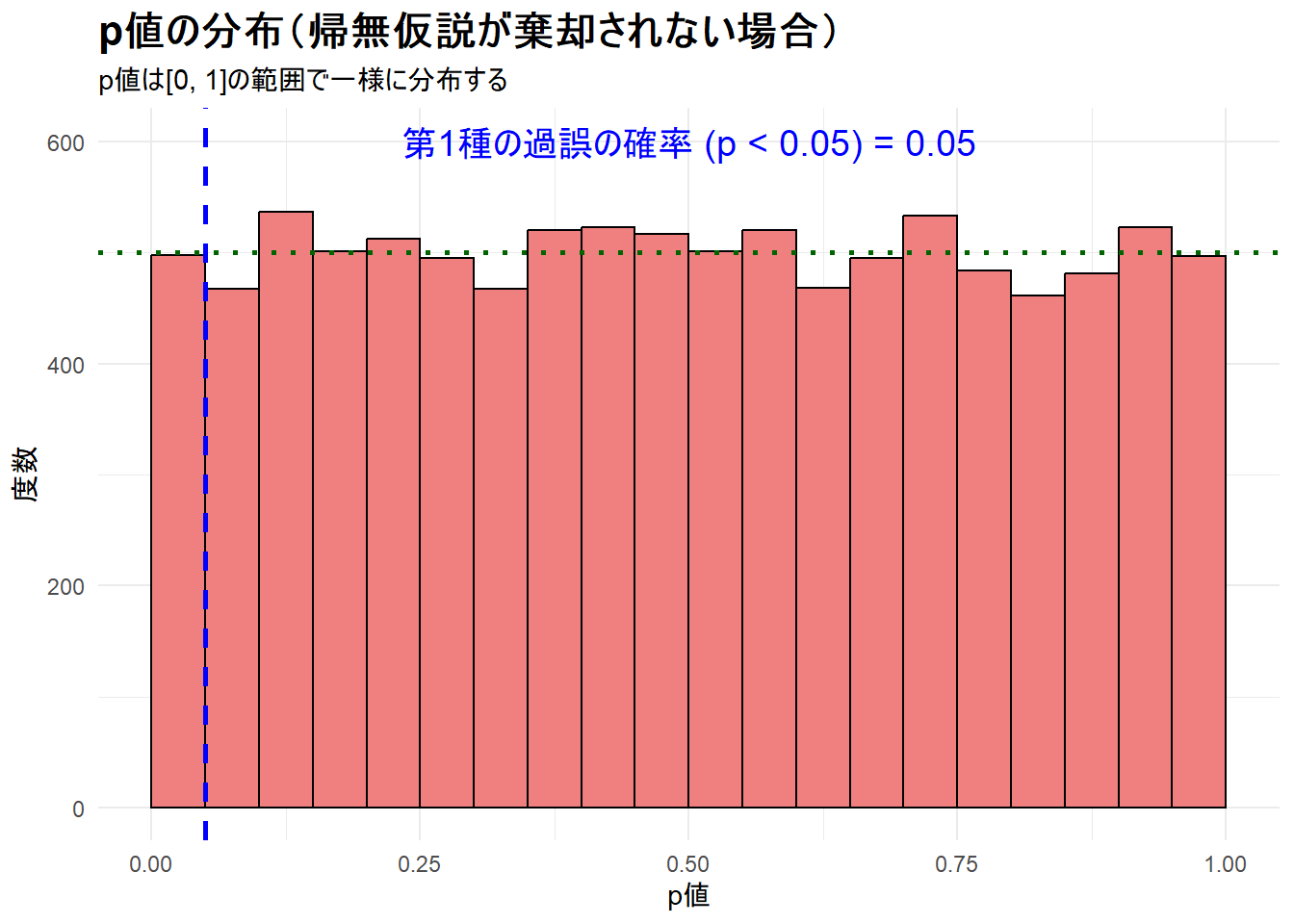
Figure 2 からは、p値がほぼフラットな分布を示しており、緑の点線(期待度数)に近い高さで推移していることがわかります。これにより、偶然だけで有意な差が出る確率が、意図通り5%にコントロールされていることが視覚的に確認できます。
以上です。

