
Rで 機械学習:K近傍法 を試みます。
本ポストはこちらの続きです。

1. K近傍法(K-Nearest Neighbors, k-NN)とは
K近傍法(k-NN)は、分類と回帰の両方に使える、シンプルで直感的な教師あり学習アルゴリズムです。その基本的なアイデアは、「似たものは、同じグループに属するだろう」という考え方に基づいています。
k-NNは、予測を行うための複雑なモデルを事前に学習しません。そのため、怠惰学習(Lazy Learning) や インスタンスベース学習(Instance-Based Learning) とも呼ばれます。学習フェーズでは、単に訓練データを全てメモリに記憶しておくだけです。
k-NNのアルゴリズム
新しいデータ点のクラスを予測する際、k-NNは以下のステップで動作します。
距離の計算: 予測したい新しいデータ点と、訓練データ中の全ての点との間の距離を計算します。距離の計算には、一般的にユークリッド距離が用いられます。 2つの点 \(p=(p_1, p_2, ..., p_n)\) と \(q=(q_1, q_2, ..., q_n)\) の間のユークリッド距離 \(d(p,q)\) は以下の式で表されます。 \[d(p, q) = \sqrt{\displaystyle\sum_{i=1}^{n} \left( p_i - q_i \right)^2}\]
近傍点の特定: 計算した距離が最も近い順に、訓練データ点をソートします。そして、上位から k個 のデータ点(近傍点)を選び出します。この「k」が、アルゴリズムの名前の由来であり、自分で設定する重要なパラメータ(ハイパーパラメータ)です。
多数決による予測: 選ばれたk個の近傍点が、どのクラスに属しているかを確認します。そして、その中で最も多数を占めるクラスを、新しいデータ点の予測クラスとします。
2. シミュレーションのシナリオ
舞台: 人気オンラインゲーム「データクエスト」の運営チーム
あなたは、このゲームの運営チームに所属するデータアナリストです。運営チームは、プレイヤーがよりゲームを楽しめるように、個々のプレイスタイルに合わせたサポートを提供したいと考えています。
そこで、新規プレイヤーがゲーム開始後、最初の数時間でどのようなプレイスタイルを示すかを分析し、将来「攻撃を重視するアタッカー」になるか、「防御を固めるガーディアン」になるかを予測するモデルを、k-NNで構築することになりました。
予測に使用する特徴量:
-
attack_freq(攻撃頻度): チュートリアル期間中の、1分あたりの平均攻撃回数。 -
defense_ratio(防御比率): チュートリアル期間中の、総プレイ時間に対する防御アクション(ガード、回避など)時間の割合(%)。
3. R言語によるシミュレーションコード
準備:必要なライブラリの読み込み
# ライブラリの読み込み
library(class)
library(ggplot2)
library(dplyr)
library(caret)ステップ1:k-NNの計算過程を実装する
k-NNのアルゴリズムの各ステップをコードで実装・実行します。
# 再現性のための乱数シード設定
seed <- 20250813
set.seed(seed)
# 1. データ準備
# 意図的に2つのクラスの境界が曖昧なデータセットを生成します。
# (注意) k_value は下記のステップ3の結果を確認した後に決定しています。
n <- 60 # 各クラスのデータ数
attackers <- data.frame(attack_freq = rnorm(n, mean = 18, sd = 5), defense_ratio = rnorm(n, mean = 22, sd = 8))
guardians <- data.frame(attack_freq = rnorm(n, mean = 12, sd = 6), defense_ratio = rnorm(n, mean = 38, sd = 10))
train_data <- rbind(attackers, guardians)
train_labels <- as.factor(c(rep("アタッカー", n), rep("ガーディアン", n)))
new_player <- data.frame(attack_freq = 16, defense_ratio = 30)
k_value <- 9
cat(paste("\n新人プレイヤー(攻撃頻度:", new_player$attack_freq, ", 防御比率:", new_player$defense_ratio, ")のスタイルを予測します。\n"))
# 2. 【距離計算】新人プレイヤーと全プレイヤーの距離を計算
distances <- apply(train_data, 1, function(point) {
sqrt(sum((point - new_player)^2))
})
# 3. 【近傍点特定】距離が近い順に並べ替え、上位k個のインデックスを取得
sorted_indices <- order(distances)
nearest_indices <- head(sorted_indices, k_value)
# 4. 【多数決】特定した近傍点のラベルを取得して集計
nearest_labels <- train_labels[nearest_indices]
cat(paste0("\n■ 投票結果の集計 (k=", k_value, "の場合):\n"))
print(table(nearest_labels))
# 5. 【予測】多数決で最も多かったクラスを予測結果とする
prediction <- names(which.max(table(nearest_labels)))
cat("\n■ 多数決による最終予測結果:\n")
cat("新人プレイヤーのスタイルは「", prediction, "」と予測されました。\n")
# 6. 【可視化】計算過程をプロットで確認
nearest_neighbors_data <- train_data[nearest_indices, ]
p_knn_manual <- ggplot(as.data.frame(train_data), aes(x = attack_freq, y = defense_ratio)) +
geom_point(aes(color = train_labels, shape = train_labels), size = 3, alpha = 0.7) +
geom_point(data = new_player, aes(x = attack_freq, y = defense_ratio), color = "blue", size = 6, shape = 4, stroke = 1.5) +
geom_point(data = nearest_neighbors_data, shape = 21, size = 5, stroke = 1.5, color = "black") +
scale_color_manual(values = c("アタッカー" = "red", "ガーディアン" = "darkgreen")) +
scale_shape_manual(values = c("アタッカー" = 16, "ガーディアン" = 17)) +
labs(title = paste0("k-NNの計算過程の可視化 (k=", k_value, ")"), subtitle = paste0("青い×印の周りの", k_value, "人(黒丸)を特定"), x = "攻撃頻度 (回/分)", y = "防御比率 (%)", color = "スタイル", shape = "スタイル") +
theme_bw() +
theme(legend.position = "bottom")
print(p_knn_manual)
新人プレイヤー(攻撃頻度: 16 , 防御比率: 30 )のスタイルを予測します。
■ 投票結果の集計 (k=9の場合):
nearest_labels
アタッカー ガーディアン
6 3
■ 多数決による最終予測結果:
新人プレイヤーのスタイルは「 アタッカー 」と予測されました。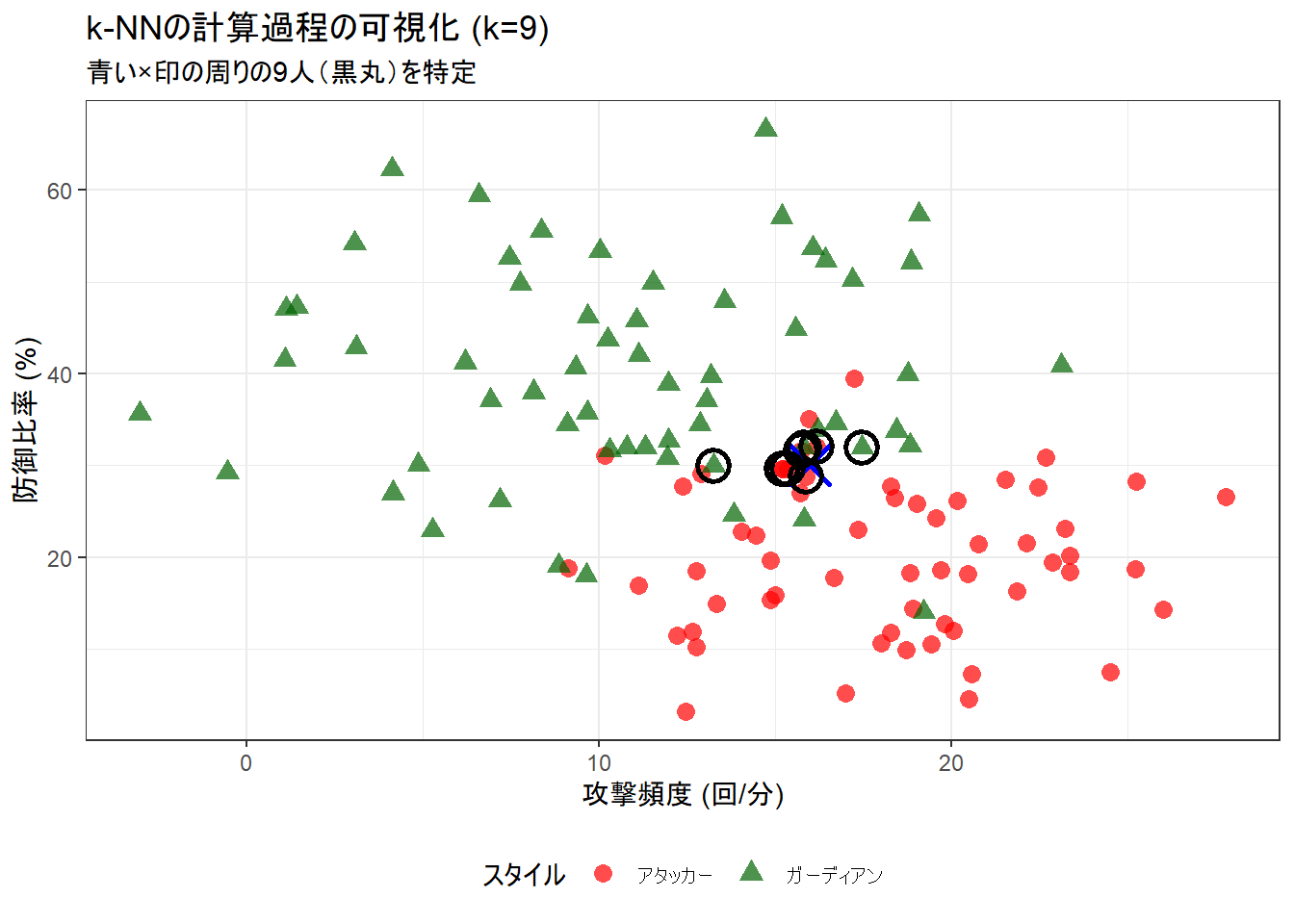
ステップ2:kの値と決定境界の関係
kの値を変えると、モデルの決定境界がどのように変化するかを視覚的に比較します。
# kの値を変えた場合に、決定境界がどのように変化するかを比較します。
# グリッドデータ等の準備
grid_range <- apply(train_data, 2, range)
x_grid <- seq(from = grid_range[1, 1], to = grid_range[2, 1], length.out = 150)
y_grid <- seq(from = grid_range[1, 2], to = grid_range[2, 2], length.out = 150)
grid_df_base <- expand.grid(attack_freq = x_grid, defense_ratio = y_grid)
k_list <- c(1, 9, 30)
prediction_list <- list()
for (k in k_list) {
grid_df_temp <- grid_df_base
# ここでは簡便さのため、class::knnを使用
predicted_classes <- knn(train = train_data, test = grid_df_temp[, 1:2], cl = train_labels, k = k)
grid_df_temp$predicted_class <- predicted_classes
grid_df_temp$k <- paste("k =", k)
prediction_list[[paste0("k=", k)]] <- grid_df_temp
}
all_predictions <- bind_rows(prediction_list)
train_df <- as.data.frame(train_data)
train_df$label <- train_labels
train_data_for_plot <- lapply(k_list, function(k_val) {
mutate(train_df, k = paste("k =", k_val))
}) %>% bind_rows()
# ファセットの順序を制御するために因子型に変換
level_order <- paste("k =", k_list)
all_predictions$k <- factor(all_predictions$k, levels = level_order)
train_data_for_plot$k <- factor(train_data_for_plot$k, levels = level_order)
# プロットの作成
p_boundary <- ggplot() +
geom_raster(data = all_predictions, aes(x = attack_freq, y = defense_ratio, fill = predicted_class), alpha = 0.3, interpolate = TRUE) +
geom_point(data = train_data_for_plot, aes(x = attack_freq, y = defense_ratio, color = label), size = 2) +
facet_wrap(~k) +
scale_color_manual(name = "実績データ", values = c("アタッカー" = "red", "ガーディアン" = "darkgreen")) +
scale_fill_manual(name = "予測領域", values = c("アタッカー" = "red", "ガーディアン" = "darkgreen")) +
labs(title = "kの値と決定境界の関係", subtitle = "kの値によってモデルの複雑さが変わる", x = "攻撃頻度 (回/分)", y = "防御比率 (%)") +
theme_bw()
print(p_boundary)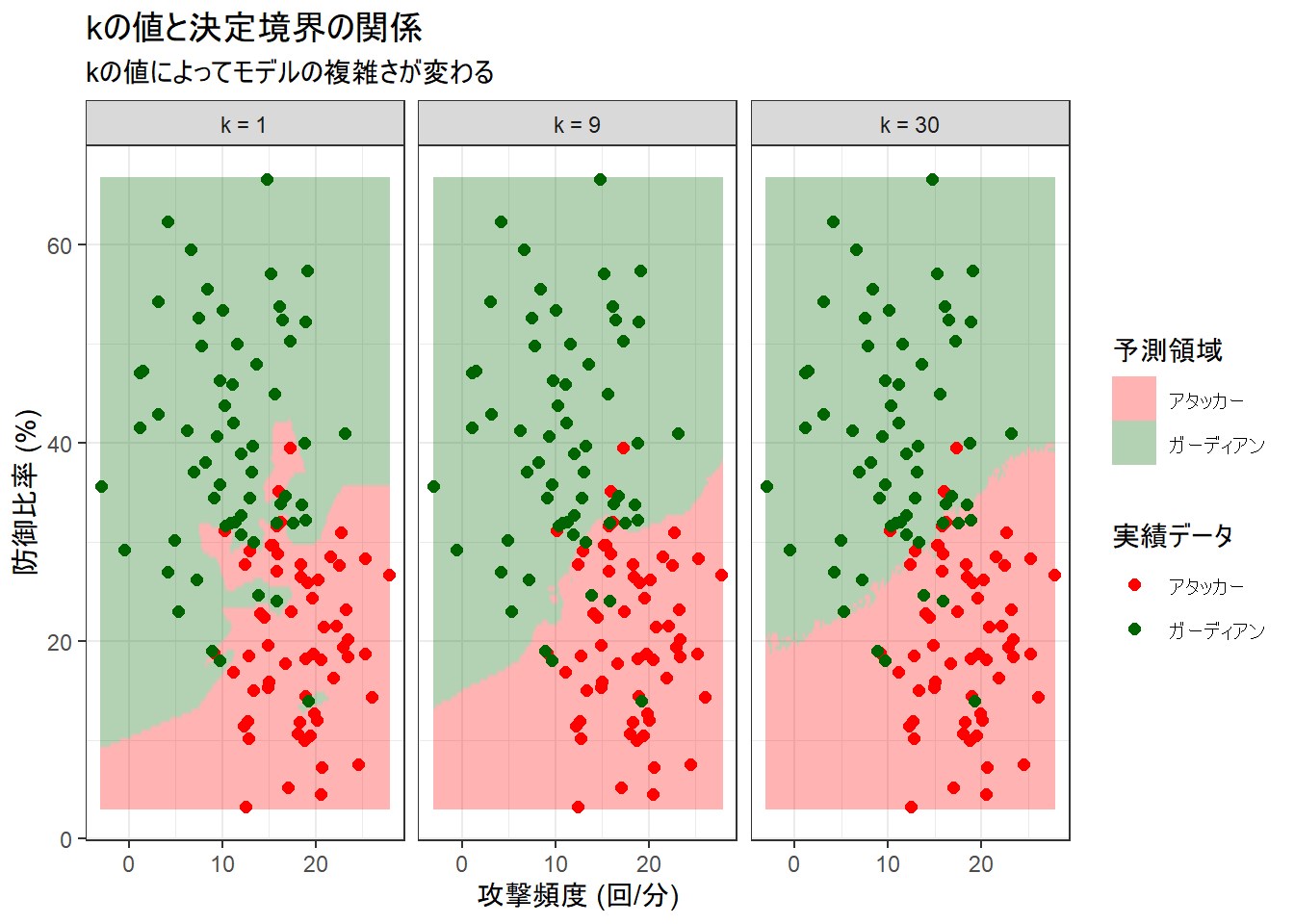
左のプロット: k = 1 (過学習モデル)
- 見た目の特徴: 境界線は複雑です。赤い領域(アタッカー予測)の中に緑の点が孤立していたり、逆に緑の領域に赤い点が孤立している部分では、その点を取り囲むように境界線が不自然に歪んでいます。
- モデルの挙動: これは過学習(Overfitting)の典型例です。モデルは「最も近くにいるたった1つの点」だけを信じるため、訓練データに含まれる一つ一つの点、たとえそれがノイズや例外的なデータであっても過剰に反応してしまっています。
- 結論: このモデルは、学習に使った「訓練データ」に対しては高い正解率を出しますが、そのルールは複雑すぎます。未知のデータが来たときには、この細かすぎるルールが原因で、かえって予測を間違えやすい「応用力のないモデル」と言えます。
右のプロット: k = 30 (過小適合モデル)
- 見た目の特徴: 境界線は非常に滑らかで、単純です。2つのクラスを大まかには分けていますが、境界線付近の点を誤って分類してしまっています。
- モデルの挙動: これは過小適合(Underfitting)の傾向を示しています。モデルは「周りの30人」という広い範囲の意見を聞くため、データの細かな特徴や構造を捉えきれず、あまりにも単純で「大雑把すぎる」ルールになってしまっています。
- 結論: このモデルは、ルールが単純すぎて、アタッカーとガーディアンを分けるための重要な情報を見逃している状態です。
中央のプロット: k = 9 (バランスの取れたモデル)
- 見た目の特徴: 境界線は、
k=1ほど複雑ではなく、k=30ほど単純すぎもしない、適度に滑らかな曲線を描いています。 - モデルの挙動: このモデルは、「周りの9人」の意見を参考にします。これにより、1つや2つの例外的な点(ノイズ)に惑わされることなく、データ全体の大局的な傾向(「このあたりはアタッカーが多く、このあたりはガーディアンが多い」というパターン)をうまく捉えています。いくつかの点は誤分類していますが、これはノイズを適切に無視して、より汎化性能の高いルールを学習しようとしている結果です。
- 結論: これが最もバランスの取れた良いモデルと言えます。訓練データに過剰に適合することなく、未知のデータに対しても安定して高い性能を発揮することが期待できます。
(注意)
- 上記の解説は下記の「ステップ3」の結果を確認した後に記述しています。
ステップ3:クロスバリデーションによる最適なkの探索
クロスバリデーションを用いて、各モデルの性能を客観的な数値で評価します。
# 1. データを準備
train_df_for_cv <- as.data.frame(train_data)
train_df_for_cv$label <- train_labels
# 2. クロスバリデーションの設定 (10-fold)
set.seed(seed)
cv_control <- trainControl(method = "cv", number = 10)
# 3. 試したいkの値のリストを作成 (候補を増やす)
k_grid <- expand.grid(k = c(1, 3, 5, 7, 9, 11, 15, 21, 31))
# 4. train関数でモデルの学習とクロスバリデーションを同時に実行
knn_cv_results <- train(
label ~ .,
data = train_df_for_cv,
method = "knn",
trControl = cv_control,
tuneGrid = k_grid,
preProcess = c("center", "scale")
)
# 5. 結果の表示
cat("■ 数量的な評価結果:\n")
print(knn_cv_results)
cat("\n■ 結果をグラフで可視化:\n")
plot(knn_cv_results)■ 数量的な評価結果:
k-Nearest Neighbors
120 samples
2 predictor
2 classes: 'アタッカー', 'ガーディアン'
Pre-processing: centered (2), scaled (2)
Resampling: Cross-Validated (10 fold)
Summary of sample sizes: 108, 108, 108, 108, 108, 108, ...
Resampling results across tuning parameters:
k Accuracy Kappa
1 0.8416667 0.6833333
3 0.8750000 0.7500000
5 0.8666667 0.7333333
7 0.8750000 0.7500000
9 0.8833333 0.7666667
11 0.8666667 0.7333333
15 0.8583333 0.7166667
21 0.8500000 0.7000000
31 0.8583333 0.7166667
Accuracy was used to select the optimal model using the largest value.
The final value used for the model was k = 9.
■ 結果をグラフで可視化: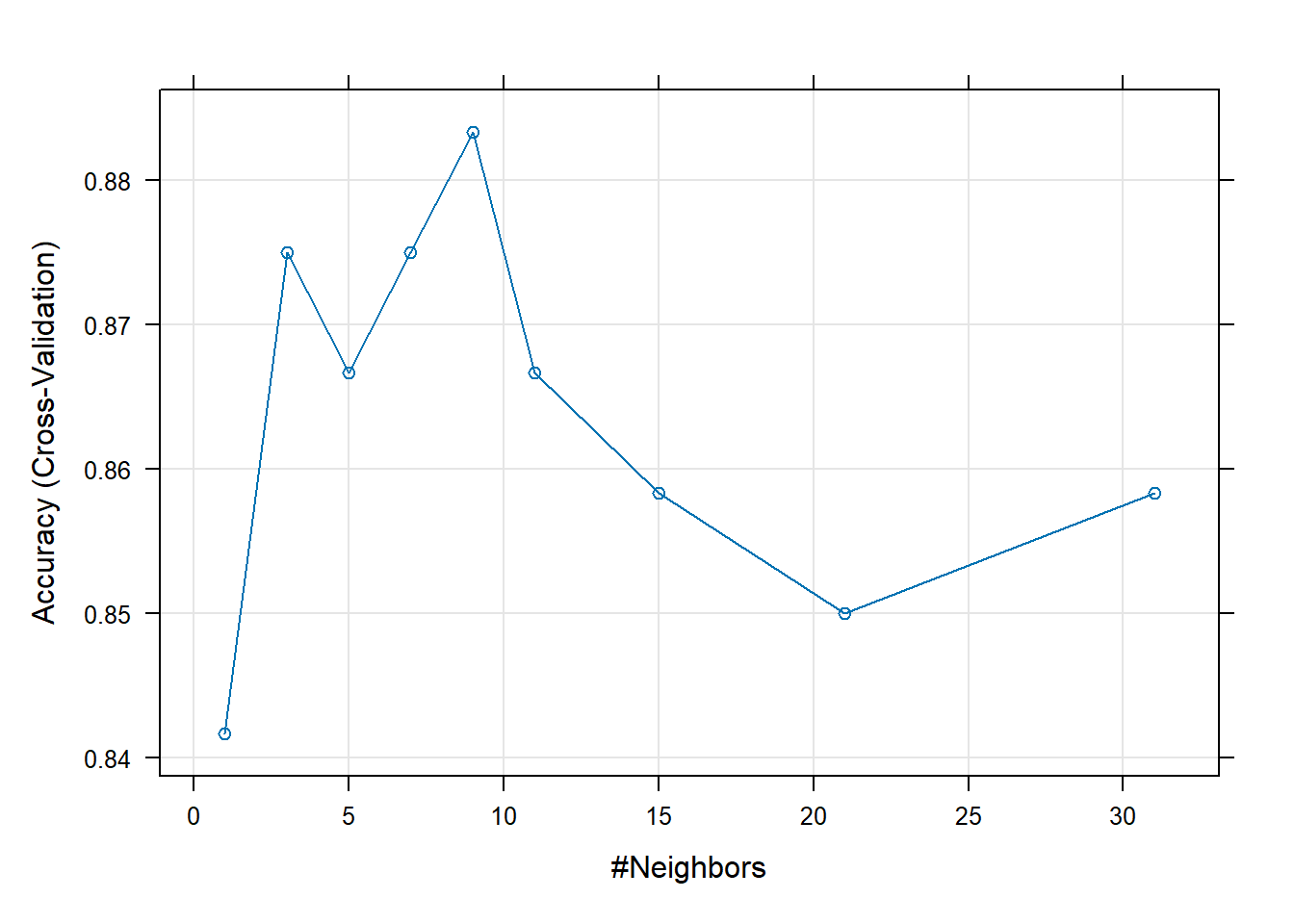
k-Nearest Neighbors
120 samples
2 predictor
2 classes: 'アタッカー', 'ガーディアン'
Pre-processing: centered (2), scaled (2)
Resampling: Cross-Validated (10 fold) - モデルとデータ: k-NNモデルを、120個のサンプル(データ点)、2つの予測変数(
attack_freq,defense_ratio)、2つのクラス(アタッカー,ガーディアン)で学習させたことを示します。 - 前処理 (
Pre-processing): 距離ベースのk-NNでは、各変数のスケール(単位)が異なると距離計算に不公平が生じます。そのため、学習前にデータを中心化(centered)し、標準化(scaled)するという前処理を自動で行ったことを示しています。これにより、全ての変数が同じ土俵で比較されるようになります。 - 再サンプリング (
Resampling): モデルの性能評価方法として、10分割交差検証 (Cross-Validated (10 fold)) を使用したことを示しています。
Resampling results across tuning parameters:
k Accuracy Kappa
1 0.8416667 0.6833333
3 0.8750000 0.7500000
5 0.8666667 0.7333333
7 0.8750000 0.7500000
9 0.8833333 0.7666667
11 0.8666667 0.7333333
15 0.8583333 0.7166667
21 0.8500000 0.7000000
31 0.8583333 0.7166667表は、各kの値に対するモデルの汎化性能(未知のデータへの対応力)を示しています。
-
Accuracy(正解率): 10回のテストで得られた正解率の平均値です。この値が高いほど、モデルの性能が良いと判断できます。
過学習の確認 (
k=1): 決定境界のグラフでは訓練データに最もフィットしているように見えたk=1ですが、そのAccuracyは0.842(84.2%) と、他のkの値と比べて高くありません。これは、k=1のモデルが訓練データに過学習し、未知のデータに対する予測性能が落ちてしまったことを定量的に証明しています。最適なkの探索: 表を眺めると、
kが大きくなるにつれてAccuracyが上昇し、k=9の時に0.883(88.3%) という最高値を記録しています。これは、近傍点を9個参照するモデルが、このデータセットにおいて最もバランスが取れており、高い汎化性能を持つことを示唆しています。過小適合の確認:
kが9を超えてさらに大きくなると、今度はAccuracyが徐々に低下していく傾向が見られます(例:k=21で0.850)。これは、参照する範囲が広くなりすぎて、モデルがデータの細かな特徴を捉えきれなくなる「過小適合」が起き始めていることを示しています。
Accuracy was used to select the optimal model using the largest value.
The final value used for the model was k = 9.-
caretパッケージは、評価指標としてAccuracyを使用し、その値が最も高かったモデルを最適モデルとして自動で選択したことを示しています。 - その結果、このデータセットとシナリオにおける最終的な推奨値として
k = 9が選ばれました。
以上です。

