
Rの関数から commarobust {estimatr} を確認します。
関数 commarobust とは
commarobust は、既存の線形回帰モデル(lm オブジェクト)に対して、頑健標準誤差(Robust Standard Errors)を計算し、推論結果を更新するための関数です。
Rの lm 関数を利用する際は、誤差項が等分散(homoskedasticity)であると仮定して標準誤差やp値を計算します。
しかし、現実のデータでは不均一分散(heteroskedasticity)が存在したり、クラスター相関があったりすることが一般的です。
これらの場合、lm の標準誤差は偏りを持ち、統計的推論(検定や信頼区間)が不正確になります。
commarobust を使用すると、すでに作成された lm オブジェクトを入力として受け取り、係数の推定値はそのままに、標準誤差、信頼区間、p値だけを「頑健な(ロバストな)」ものに置き換えた lm_robust クラスのオブジェクトを返します。
関数 commarobust の引数
library(estimatr)
args(commarobust)function (model, se_type = NULL, clusters = NULL, ci = TRUE,
alpha = 0.05)
NULL-
model- 計算の対象となる、すでに適合済みの線形回帰モデルのオブジェクトです。
- クラスが
"lm"である必要があります。
-
se_type- 計算したい標準誤差の種類を指定する文字列です。
- デフォルト:
NULL(この場合、関数内部で自動的にデフォルト値が選択されます。通常、クラスター指定がない場合は"HC2"、ある場合は"CR2"がデフォルトとなります)。 - 選択肢(クラスター指定なし):
-
"HC0": ホワイトの不均一分散一致標準誤差(古典的なロバストSE)。 -
"HC1":"HC0"に自由度調整 \(N/(N-k)\) を加えたもの(Stata のデフォルトに相当)。 -
"HC2": (デフォルト) レバレッジ(ハット行列の対角要素)に基づいて調整したもの。 -
"HC3":"HC2"よりもさらに強くレバレッジを補正したもの。 -
"classical": 通常のOLS標準誤差(lmと同じ)。
-
- 選択肢(クラスター指定あり):
-
"CR0": クラスターロバスト標準誤差の基本形。 -
"CR2": (デフォルト) 小数クラスター数でのバイアスを補正したもの。 -
"stata": Stata のクラスターロバスト標準誤差と同じ計算方法("CR1"に相当)。
-
-
clusters- クラスター(集団)を指定するベクトルです。
- モデルのデータと同じ長さである必要があります。各観測がどのクラスター(例:学校、地域、企業など)に属しているかを示します。
- 誤差項がクラスター内で相関している可能性がある場合(クラスター相関)、これを指定することでクラスターロバスト標準誤差を計算します。指定しない場合は、観測間の独立性が仮定されます。
-
ci- 信頼区間(Confidence Interval)を計算するかどうかを指定する論理値(
TRUE/FALSE)。 - デフォルト:
TRUE -
TRUEの場合、ロバスト標準誤差に基づいた信頼区間が出力に含まれます。
- 信頼区間(Confidence Interval)を計算するかどうかを指定する論理値(
-
alpha- 有意水準(significance level)を指定する数値です。
- デフォルト:
0.05 - 信頼区間の幅を決定します。例えば
0.05ならば 95% 信頼区間、0.01ならば 99% 信頼区間が計算されます。
Rによるシミュレーション
以下に、commarobust の機能を確認するためのサンプルデータを用いたシミュレーションコードを示します。
このシミュレーションでは、以下の2つのシナリオを作成します。
- シナリオ1: 不均一分散のケース:
- 説明変数 \(X\) が大きくなるにつれて誤差の分散が大きくなるデータを作成し、通常の
lmの標準誤差が過小評価される(有意になりすぎる)様子と、commarobustがそれを補正する様子を確認します。
- 説明変数 \(X\) が大きくなるにつれて誤差の分散が大きくなるデータを作成し、通常の
- シナリオ2: クラスター相関のケース:
- データがグループ(クラスター)構造を持ち、同じグループ内の誤差が相関しているデータを作成し、クラスターロバスト標準誤差を確認します。
なお、両シナリオとも有意水準は5%とします。
シナリオ1: 不均一分散(Heteroskedasticity)のシミュレーション
# パッケージの読み込み
library(ggplot2)
library(dplyr)
# 乱数シードの固定(再現性のため)
seed <- 20251210
set.seed(seed)
# サンプルサイズの定義
N <- 200
# データの生成
# 説明変数 X: 一様分布から生成
X <- runif(N, min = 1, max = 10)
# 誤差項 e: 分散が X に依存するように作成(不均一分散)
# Xが大きいほどばらつき(標準偏差)が大きくなる
e <- rnorm(N, mean = 0, sd = X * 1.5)
# 被説明変数 y: 真のモデル y = 2 + 3*X + e
y <- 2 + 3 * X + e
# データフレーム化
df_hetero <- data.frame(y = y, X = X)
# データの可視化
# じょうご型に広がっている様子を確認
p1 <- ggplot(df_hetero, aes(x = X, y = y)) +
geom_point(alpha = 0.6) +
geom_smooth(method = "lm", se = FALSE, color = "blue") +
labs(
title = "図1: 不均一分散を持つデータの散布図",
x = "説明変数 X",
y = "被説明変数 Y"
) +
theme_minimal()
print(p1)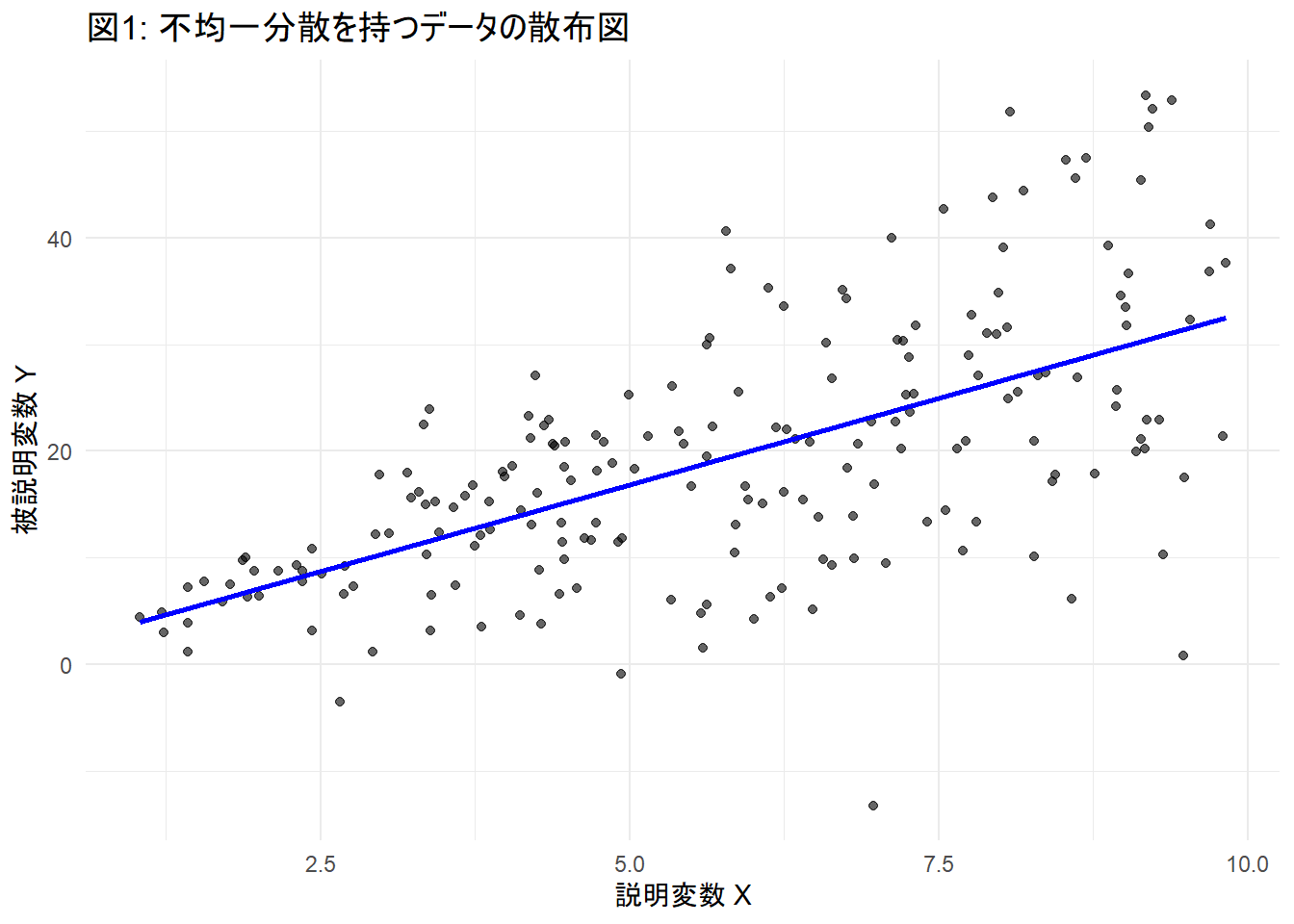
Figure 1 から、Xが大きくなるにつれて、Yのばらつきが大きくなっていることを確認できます。
# 1. 通常の lm 関数で推定(等分散を仮定)
model_ols <- lm(y ~ X, data = df_hetero)
# 2. commarobust でロバスト標準誤差を計算
# se_type = "HC2" は不均一分散に対して頑健
model_robust <- commarobust(model_ols, se_type = "HC2")
# 結果の比較表示
cat("--- 通常の lm (等分散仮定) ---\n")
print(summary(model_ols)$coefficients)
cat("\n\n--- commarobust (HC2 不均一分散頑健) ---\n")
# lm_robustオブジェクトの係数部分を表示
print(summary(model_robust)$coefficients)--- 通常の lm (等分散仮定) ---
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.5848238 1.8208330 0.3211848 7.484092e-01
X 3.2499054 0.2931605 11.0857539 1.578000e-22
--- commarobust (HC2 不均一分散頑健) ---
Estimate Std. Error t value Pr(>|t|) CI Lower CI Upper DF
(Intercept) 0.5848238 1.379574 0.4239161 6.720871e-01 -2.135721 3.305368 198
X 3.2499054 0.294934 11.0190954 2.497844e-22 2.668290 3.831520 198推定値(Estimate)の不変性
始めに、(Intercept)(切片)および X(傾き)の点推定値 Estimate を確認します。
通常の lm の結果も、commarobust の結果も、共に切片は約 0.5848、X の係数は約 3.2499 と完全に一致しています。
これは、commarobust が回帰係数そのものを再計算するのではなく、推定された係数の「確からしさ(標準誤差)」のみを再評価する関数であるという性質を裏付けています。
説明変数 \(X\) における標準誤差の拡大
説明変数 X の Std. Error(標準誤差)を比較すると、以下の変化が見られます。
- 通常の lm: 説明変数 \(X\) の標準誤差は 0.2931605
- commarobust: 説明変数 \(X\) の標準誤差は 0.294934
commarobust による標準誤差の方がわずかに大きな値を示しています。
シミュレーションデータは「\(X\) が大きくなるにつれて誤差の分散が大きくなる」ように生成されました。
通常の lm はデータ全体の誤差を平均化して一定とみなすため、分散が大きい領域(\(X\) が大きい領域)の影響を過小評価してしまう傾向があります。
一方、commarobust は不均一分散を考慮し、「\(X\) が大きい部分のデータはバラつきが大きいため、傾きの推定精度は通常の方法で考えるよりも低い(誤差が大きい)」と修正を行っています。
切片における標準誤差の縮小
一方で、(Intercept) の標準誤差には逆の現象となる縮小が見られます。
- 通常の lm: 切片の標準誤差は 1.8208330
- commarobust: 切片の標準誤差は 1.379574
切片は \(X\) がゼロに近い領域を示しますが、今回のデータ生成プロセスでは「\(X\) が小さいときは誤差の分散も小さい」という設定です。
通常の lm は、全体の平均的な分散(\(X\) が大きい部分の大きなノイズを含む)を前提とするため、本来は精度が高いはずの切片付近の推定に対して、過大な誤差を見積もっていました。
commarobust は局所的な分散の小ささを認識し、「この領域のデータは精度が高いため、標準誤差はもっと小さい」と判断して数値を縮小させています。
シナリオ2: クラスター相関(Clustered Errors)のシミュレーション
set.seed(seed)
# クラスター設定
n_clusters <- 20 # クラスター数(例: 20の学校)
n_per_cluster <- 10 # 1クラスターあたりの観測数(例: 1校あたり10人の生徒)
N_cluster <- n_clusters * n_per_cluster
# クラスターIDの生成
cluster_id <- rep(1:n_clusters, each = n_per_cluster)
# クラスターごとの説明変数(例: 学校の質)
# 同じクラスター内の個体は同じ値を持つ部分があるとする
X_cluster_level <- rep(rnorm(n_clusters), each = n_per_cluster)
# 個体レベルのノイズ
X_individual <- rnorm(N_cluster)
# 最終的な説明変数 X
X_cl <- X_cluster_level + X_individual
# クラスター固有の誤差(ランダム効果のようなもの)
# 同じクラスター内の個体は、この誤差を共有する(相関が生じる)
cluster_error <- rep(rnorm(n_clusters, sd = 2), each = n_per_cluster)
# 個体固有の誤差
individual_error <- rnorm(N_cluster, sd = 1)
# 被説明変数 y: 真の係数は 1
# y = 1 * X + (クラスター誤差 + 個体誤差)
y_cl <- 1 * X_cl + cluster_error + individual_error
# データフレーム化
df_cluster <- data.frame(y = y_cl, X = X_cl, cluster_id = factor(cluster_id))
# モデル(通常のOLS)から残差を取得し、データフレームに追加
# 通常の lm 関数で推定(独立を仮定)
model_cl_ols <- lm(y ~ X, data = df_cluster)
df_cluster$residuals <- resid(model_cl_ols)
# クラスターID順ではなく、残差の中央値順に並べ替えて見やすくする
# (平均的にプラスの誤差を持つクラスターと、マイナスの誤差を持つクラスターを整理)
df_cluster$cluster_ordered <- reorder(df_cluster$cluster_id, df_cluster$residuals, FUN = median)
# クラスターごとの残差の箱ひげ図
p2 <- ggplot(df_cluster, aes(x = cluster_ordered, y = residuals, fill = cluster_ordered)) +
geom_hline(yintercept = 0, linetype = "dashed", color = "gray50", linewidth = 1) + # ゼロの基準線
geom_boxplot(alpha = 0.7, show.legend = FALSE) + # 箱ひげ図
labs(
title = "図2: クラスターごとの残差(誤差)の分布",
x = "クラスターID(残差の中央値順に整列)",
y = "残差 (実測値 - 予測値)"
) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 0, vjust = 0.5))
print(p2)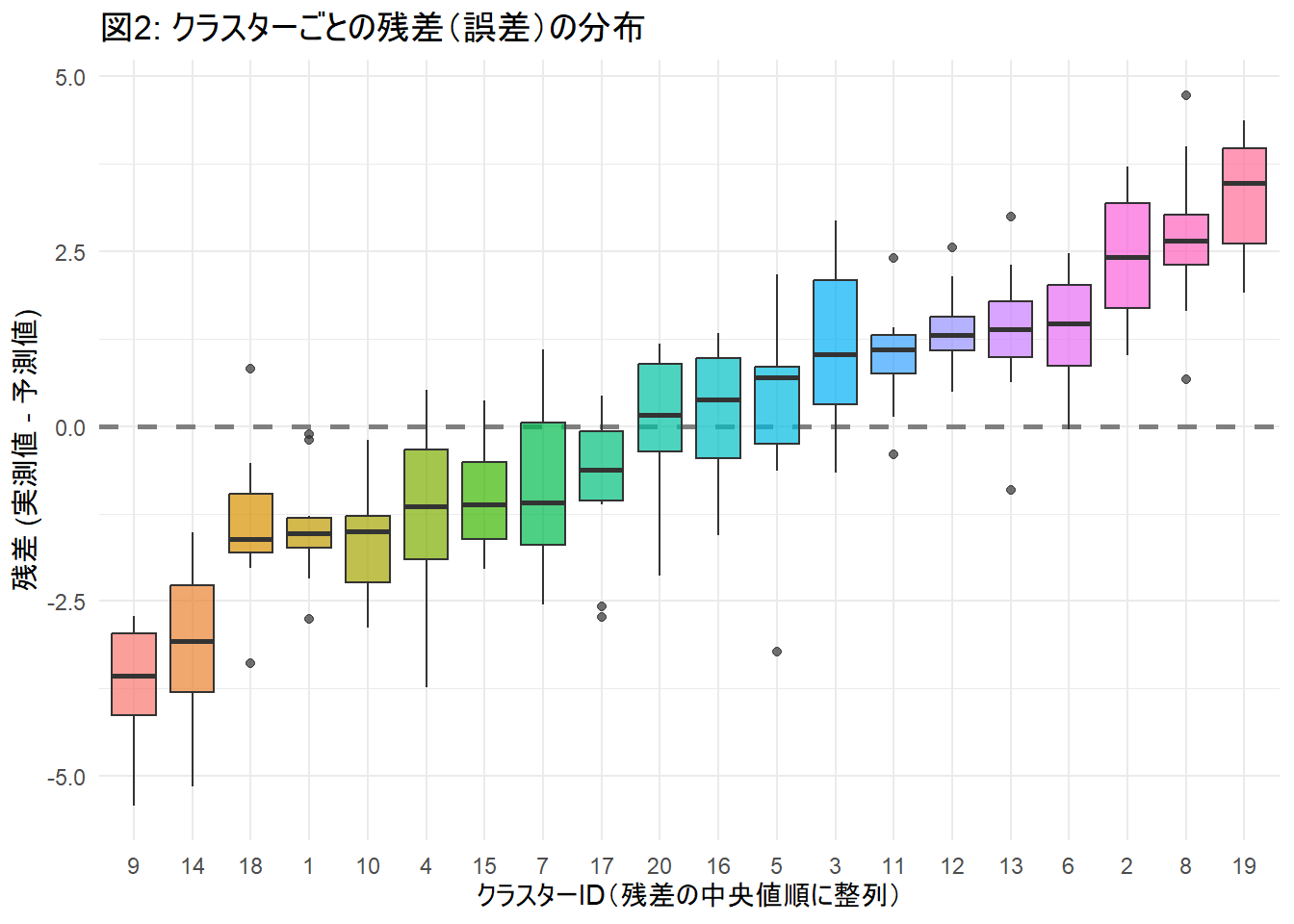
Figure 2 から、点線(ゼロ)をまたがず、箱全体が完全にプラス側、あるいはマイナス側に浮いている クラスター(箱)が複数あることを確認できます。
これは、例えば「ある学校の生徒は、説明変数\(X\)(勉強時間など)に関わらず、全員成績が予測より高くなりやすい(あるいは低くなりやすい)」というような、「クラスター内相関(誤差が似通っている)」の存在を示唆しています。
通常の lm は、この箱たちが「すべてゼロ付近にランダムに散らばっている」と仮定して計算します。
しかし Figure 2 を見れば、明らかにクラスターごとの「個性(バイアス)」が存在することがわかります。
commarobust はこの「箱ごとの偏り」を考慮して標準誤差を更新します。
# commarobust でクラスターロバスト標準誤差を計算
# clusters 引数にクラスターIDを指定する
model_cl_robust <- commarobust(model_cl_ols, clusters = df_cluster$cluster_id, se_type = "CR2")
# 結果の比較表示
cat("--- 通常の lm (独立仮定) ---\n")
print(summary(model_cl_ols)$coefficients)
cat("\n\n--- commarobust (CR2 クラスター頑健) ---\n")
print(summary(model_cl_robust)$coefficients)--- 通常の lm (独立仮定) ---
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.1293884 0.1503780 -0.8604214 3.905975e-01
X 0.9675682 0.1110511 8.7128203 1.181353e-15
--- commarobust (CR2 クラスター頑健) ---
Estimate Std. Error t value Pr(>|t|) CI Lower CI Upper DF
(Intercept) -0.1293884 0.4622018 -0.2799392 0.782977218 -1.1062239 0.8474471 16.62574
X 0.9675682 0.2795352 3.4613468 0.003541527 0.3711539 1.5639826 14.82894標準誤差の拡大
- 通常の lm: 説明変数 \(X\) の標準誤差は 0.1110511
- commarobust: 説明変数 \(X\) の標準誤差は 0.2795352
通常の lm 関数は、200個のデータがすべて互いに独立である(全く無関係な個体から得られた)と仮定して計算を行います。
しかし、実際にはデータは20個のクラスター(集団)から構成されており、同じクラスター内のデータは似通った動きをします。
lm はこの相関を無視し、サンプルサイズの見かけ上の大きさ(\(N=200\))をそのまま情報の豊富さと解釈してしまいます。
それゆえ、標準誤差を実際よりも小さく、つまり「精度が高い」と誤認して見積もっていました。
一方、commarobust は「有効な情報の単位は観測数(200)ではなく、クラスター数(20)に近い」という事実を反映して計算を行います。
その結果、標準誤差は約2.5倍に拡大し、推論の確実性が過大評価されていたことを修正しました。
p値の更新と第一種の過誤の回避
標準誤差の拡大に伴い、統計的有意性を示す数値も変化しています。
- t値 (t value):
8.71から3.46へと半分以下に低下しました。 - p値 (Pr(>|t|)):
1.18e-15(ほぼゼロ)から0.0035へと変化しました。
通常の lm では p値が ほぼゼロ との結果を返しましたが、これはクラスター相関を無視したことによる「見せかけの強さ」が含まれていました。
もし、係数がボーダーライン上の値であった場合、例えば、lm のp値が 0.049、commarobustのp値は 0.085 であったような場合、lm では「有意である」と誤って判定(第一種の過誤)してしまう恐れがあります。
commarobust は p値をより保守的な値へと引き戻しており、現実のデータの不確実性を反映した結果といえます。
自由度(DF)の減少
- 通常の lm: 自由度は \(N - k = 200 - 2 = 198\) (出力には表示されていませんが、t分布の計算にはこの値が使われます)。
- commarobust: 自由度は約 14.8 と表示されています。
こちらもまた、commarobust が情報の単位を「個体」ではなく「クラスター」ベースで評価している証左です。
自由度が 198 から 15 程度まで減少するということは、t分布の裾が広くなり、有意であると判定するためのハードルが高くなることを意味します。
Satterthwaite 近似を用いたこの自由度の調整により、クラスター数が少ない場合でも、より正確な信頼区間の算出が可能となります。
以上です。

