
Rの関数から acf {stats} を確認します。
関数 acf とは
acf は、時系列データの 自己相関関数(AutoCorrelation Function: ACF)、自己共分散関数(AutoCovariance Function: ACVF)、または 偏自己相関関数(Partial AutoCorrelation Function: PACF) を計算し、プロットするための関数です。
時系列分析において、現在の値が過去の値とどの程度相関しているかを把握することは、モデルの識別(ARIMAモデルの次数決定など)において基本的な手順です。
acf 関数は、C言語で実装された計算ロジックを用いてそれら相関を求めます。
参照コード
関数 acf の引数
args(acf)function (x, lag.max = NULL, type = c("correlation", "covariance",
"partial"), plot = TRUE, na.action = na.fail, demean = TRUE,
...)
NULL-
x- 分析対象となる数値ベクトル、行列、または時系列オブジェクト(
ts)。 - 数値データである必要があります。多変量(複数列)の場合、すべてのペア間の交差相関(Cross-Correlation)も計算されます。
- 分析対象となる数値ベクトル、行列、または時系列オブジェクト(
-
lag.max- 計算するラグ(遅れ)の最大値(整数)。
- デフォルト:
NULL。この場合、サンプルサイズ \(N\) とシリーズ数 \(m\) に基づき \(10 \log_{10}(N/m)\) 程度に自動設定されます(1変量の場合は\(m=1\))。
-
type- 計算する統計量の種類を指定する文字列。
- 選択肢:
-
"correlation"(デフォルト):- 自己相関関数(ACF)。値は \([-1, 1]\) の範囲に正規化されます。ラグ0は常に1です。
-
"covariance":- 自己共分散関数(ACVF)。正規化されていない生の値(単位はデータの二乗)です。ラグ0は分散(バイアスあり)に相当します。
-
"partial":- 偏自己相関関数(PACF)。中間のラグの影響を取り除いた直接的な相関です。内部的に
pacf関数を呼び出します。
- 偏自己相関関数(PACF)。中間のラグの影響を取り除いた直接的な相関です。内部的に
-
-
plot- 結果をグラフ描画するかどうかの論理値。
- デフォルト:
TRUE。
-
na.action- 欠損値(NA)の取り扱い方法を指定する関数。
- デフォルト:
na.fail(欠損値がある場合はエラーで停止)。 -
na.passを指定すると計算を試みますが、Cコード(acf0)内ではISNANチェックが行われ、欠損を含む項は計算から除外されるため、結果にNAが含まれる可能性があります。
-
demean- 計算前に全体平均を引く(中心化する)かどうかの論理値。
- デフォルト:
TRUE。 -
TRUE:- 各時点の値から平均値を引いて計算します。これは一般的な共分散・相関の定義(平均からの偏差の積)に一致します。
-
FALSE:- 平均を引かずに積和を計算します。データがゼロ平均でない場合、結果は「相関」という意味をなさなくなります(平均値の二乗の影響が支配的になるため)。
-
...-
plotがTRUEの場合に、内部で呼び出されるplot.acf関数へ渡される追加引数(タイトルやラベルの変更など)。
-
シミュレーションコード
以下に、acf の機能を確認するためのサンプルデータを用いたシミュレーションコードを示します。
本シミュレーションでは、以下の3つのパートに分けて検証を行います。
- 基本動作:
- MA(1)プロセスを用いて、理論通りのACFが計算されるか確認します。
-
typeの違い:- AR(1)プロセスを用いて、相関・共分散・偏自己相関の違いを可視化します。
-
demeanの違い:- 平均値が0ではないデータを用いて、中心化の有無が結果に与える影響を確認します。
基本動作の確認: MA(1)プロセス
# パッケージの読み込み
library(ggplot2)
library(gridExtra)
# 乱数シードの固定
seed <- 20260227
set.seed(seed)
# データ生成: 移動平均モデル MA(1)
# X_t = e_t + 0.8 * e_{t-1}
# 理論的特徴: ラグ1のみに強い相関があり、ラグ2以降は0になる
n_sample <- 200
ma_data <- arima.sim(n = n_sample, model = list(ma = 0.8))
# acf関数の実行 (type="correlation")
acf_res <- acf(ma_data, plot = FALSE)
# データフレーム化(可視化用)
df_acf_ma <- data.frame(
Lag = as.numeric(acf_res$lag),
ACF = as.numeric(acf_res$acf)
)
# 可視化
p1 <- ggplot(df_acf_ma, aes(x = Lag, y = ACF)) +
geom_bar(stat = "identity", width = 0.5, fill = "steelblue") +
geom_hline(yintercept = 0, color = "black") +
# 95%信頼区間 (近似値: +/- 1.96/sqrt(N))
geom_hline(
yintercept = c(-1.96 / sqrt(n_sample), 1.96 / sqrt(n_sample)),
linetype = "dashed", color = "blue"
) +
labs(
title = "MA(1)プロセスの自己相関 (ACF)",
x = "ラグ (Lag)", y = "自己相関"
) +
theme_minimal()
print(p1)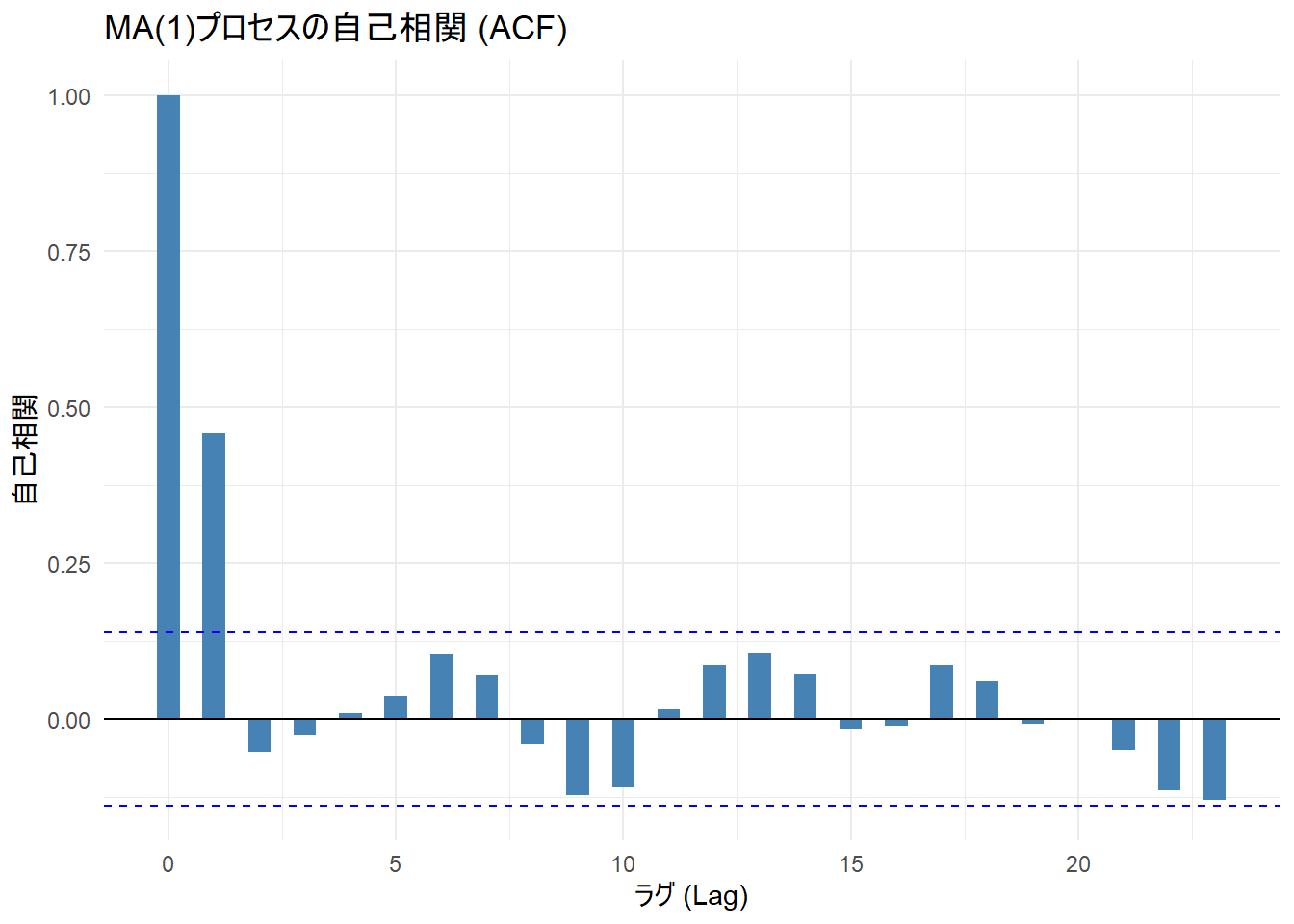
ラグ0 の値(一番左の棒)
- 値が 1.0:
- ラグ0 は「自分自身との相関」を表すため、どのようなデータであっても必ず 1.0 になります。
ラグ1 の値(二番目の棒)
- ラグ1の棒は 0.5 付近まで伸びており、青い点線(95%信頼区間)を上回っています。これは「統計的に有意な正の相関がある」ことを示しています。
- MA(1)モデル(\(X_t = \epsilon_t + 0.8 \epsilon_{t-1}\))では、現在の値と「1つ前の時点のノイズ」が共有されているため、ラグ1には必ず相関が現れます。理論値は約0.49(\(0.8 / (1 + 0.8^2)\))であり、Figure 1 はその特徴を捉えています。
ラグ2 以降の値
- ラグ2以降を見ると、棒の長さが短くなり、全てが青い点線の内側に収まっています。
- これは「ラグ2以降は無相関である(相関が0である)」ことを示唆しています。MA(1)プロセスは「1つ前まで」の影響しか持たないため、理論的にラグ2以降の相関はゼロになります。
引数 type の違いによる比較
set.seed(seed)
# データ生成: 自己回帰モデル AR(1)
# X_t = 0.7 * X_{t-1} + e_t
# 理論的特徴: ACFは指数的に減衰し、PACFはラグ1のみ有意となる
ar_data <- arima.sim(n = n_sample, model = list(ar = 0.7))
# 3つのタイプで計算
res_cor <- acf(ar_data, type = "correlation", plot = FALSE)
res_cov <- acf(ar_data, type = "covariance", plot = FALSE)
res_par <- acf(ar_data, type = "partial", plot = FALSE)
# データを結合して比較
# 注: PACFはラグ1から始まるため調整が必要です
df_type_compare <- rbind(
data.frame(Lag = as.numeric(res_cor$lag), Value = as.numeric(res_cor$acf), Type = "Correlation (ACF)"),
data.frame(Lag = as.numeric(res_cov$lag), Value = as.numeric(res_cov$acf), Type = "Covariance (ACVF)"),
data.frame(Lag = as.numeric(res_par$lag), Value = as.numeric(res_par$acf), Type = "Partial (PACF)")
)
# 可視化
p2 <- ggplot(df_type_compare, aes(x = Lag, y = Value, fill = Type)) +
geom_bar(stat = "identity", width = 0.5) +
geom_hline(yintercept = 0, color = "black") +
facet_wrap(~Type, scales = "free_y", ncol = 1) +
labs(
title = "引数 type による出力の違い (AR(1)プロセス)",
x = "ラグ (Lag)", y = "値"
) +
theme_minimal() +
theme(legend.position = "none")
print(p2)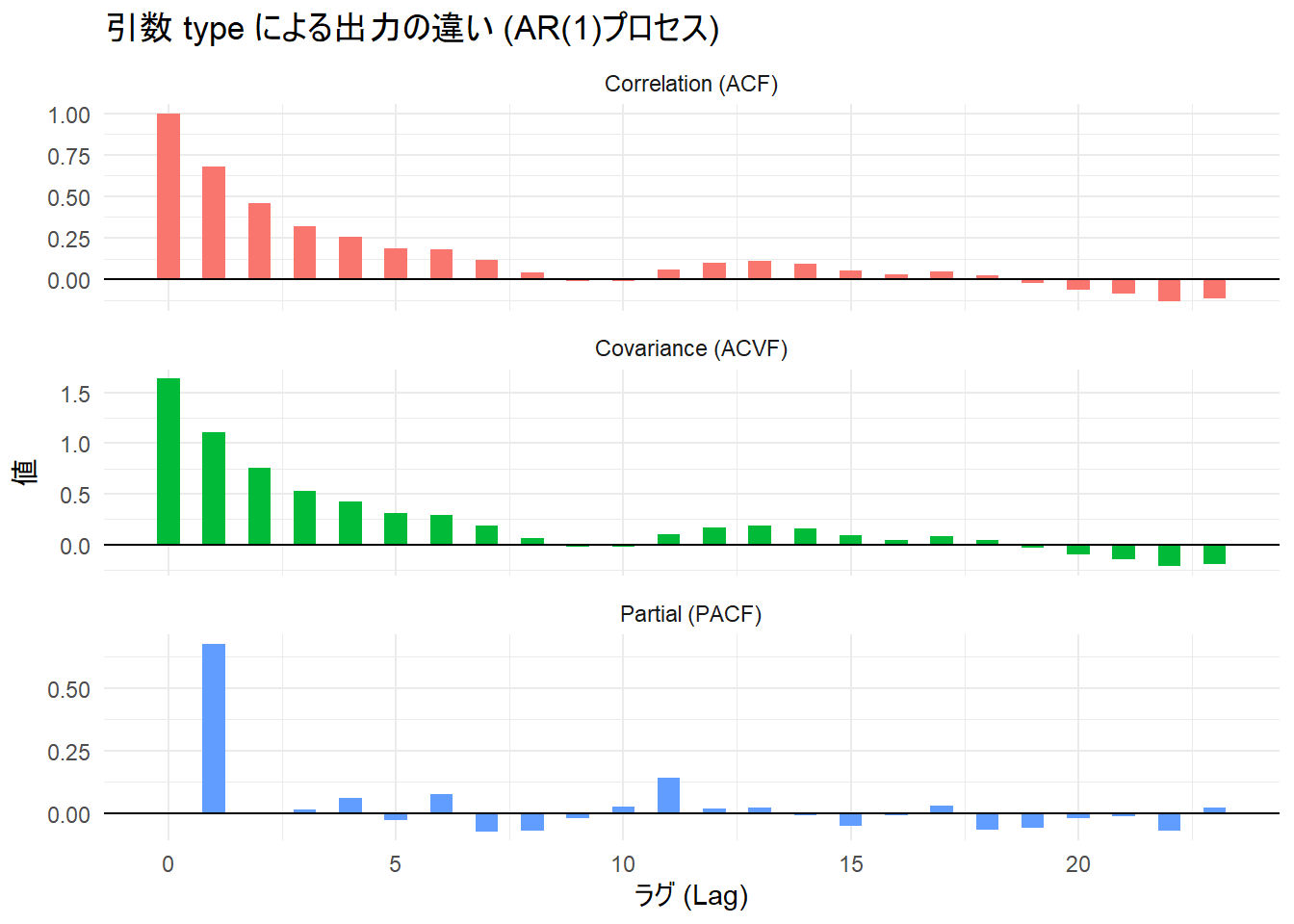
上段:Correlation (ACF / 自己相関関数)
- ラグ0は 1.0 になっています(自分自身との相関なので最大値)。
- ラグが進むにつれて、棒の長さがなだらかに減衰(Exponential Decay)しています。
- AR(1)モデル(係数0.7)では、昨日の影響が今日に残り、今日の影響が明日に残る……というように影響が連鎖するため、相関はすぐには消えません。
- 理論的には \(0.7^k\) のペースで減衰します(\(1.0 \to 0.7 \to 0.49 \to 0.34 \dots\))。グラフはこの特徴を表しています。
- 値は必ず -1 から 1 の間に収まるように正規化されています。
中段:Covariance (ACVF / 自己共分散関数)
- 形状(減衰のパターン)は上段の ACF と完全に同じです。
- 違いは縦軸のスケール(値の大きさ)です。ラグ0の値が 1.0 ではなく 約 1.5 になっています。
- これは正規化前の「生の共分散」です。
- ラグ0の値は、このデータの分散(Variance)そのものを表しています。
- データの単位(円、kgなど)をそのまま反映したい場合に使われますが、パターンの分析には通常ACFが使われます。
下段:Partial (PACF / 偏自己相関関数)
- ラグ1のみが突出しており、ラグ2以降は急激にゼロ付近(無相関)になっています。
- ラグ1の値は、シミュレーションで設定したAR係数(0.7)に近い値を示しています。
- 偏自己相関は、「間のラグの影響を取り除いた、直接的な相関」です。
- AR(1)モデルでは、「昨日の値」さえ分かれば「一昨日の値」は予測に不要(直接的な関係はない)とみなされます。そのため、ラグ2以降はストンと断ち切れたようなグラフになります。
- 「PACFがラグ1で切れている \(\rightarrow\) これはAR(1)モデルだ」 と判断するための診断図です。
引数 demean の違いによる比較
set.seed(seed)
# データ生成: 平均値が大きくズレているホワイトノイズ
# 平均 100, 標準偏差 1
offset_data <- rnorm(n_sample, mean = 100, sd = 1)
# demean = TRUE (デフォルト: 平均を引く)
res_demean_T <- acf(offset_data, demean = TRUE, plot = FALSE)
# demean = FALSE (平均を引かない)
res_demean_F <- acf(offset_data, demean = FALSE, plot = FALSE)
df_demean_compare <- rbind(
data.frame(Lag = as.numeric(res_demean_T$lag), Value = as.numeric(res_demean_T$acf), Setting = "demean = TRUE (通常)"),
data.frame(Lag = as.numeric(res_demean_F$lag), Value = as.numeric(res_demean_F$acf), Setting = "demean = FALSE (非推奨)")
)
p3 <- ggplot(df_demean_compare, aes(x = Lag, y = Value, fill = Setting)) +
geom_bar(stat = "identity", width = 0.5) +
geom_hline(yintercept = 0, color = "black") +
ylim(-0.2, 1.1) + # 範囲を固定して見やすくする
facet_wrap(~Setting, ncol = 1) +
labs(
title = "引数 demean による計算結果の変化",
x = "ラグ (Lag)", y = "自己相関"
) +
theme_minimal() +
theme(legend.position = "none")
print(p3)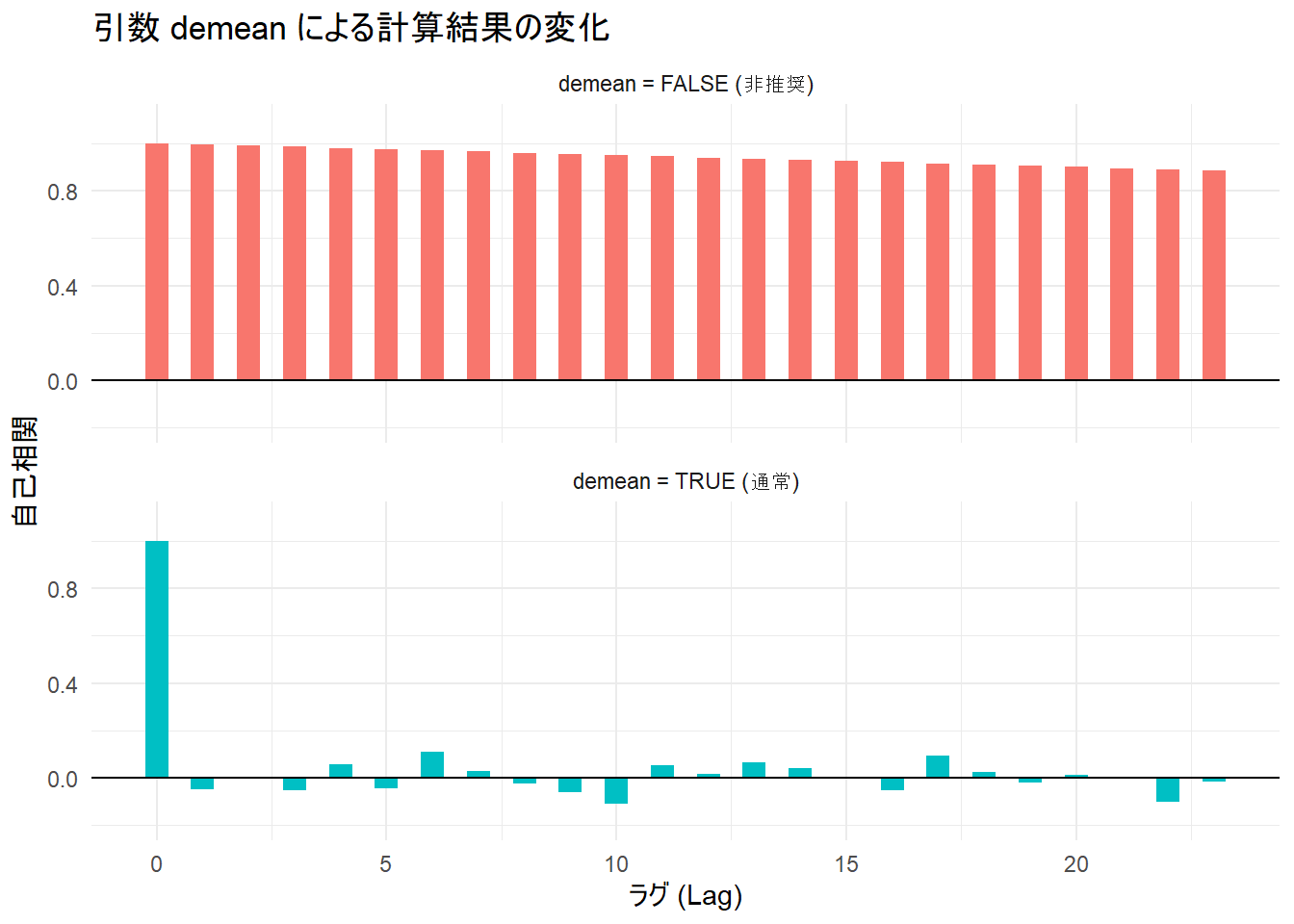
下段:demean = TRUE(通常・デフォルト)
- ラグ0以外は、バーがほとんどゼロ付近(横軸上)にあります。
- 計算前に「データの平均値(約100)」が引き算され、中心化されています。
- 残ったのは純粋な「変動成分(ノイズ)」だけです。
- 生成したデータはホワイトノイズ(無相関)でしたので、ラグ1以降の相関がゼロになるのは正解です。データの真の姿を捉えています。
上段:demean = FALSE(非推奨)
- すべてのラグで、バーが天井(1.0)近くに張り付いています。
- 平均値を引かずに計算しています。
- この場合、計算式(積和)において、「変動(分散)」よりも「平均値の二乗(\(100^2 = 10000\))」の要素が圧倒的に大きくなります。
- その結果、分子と分母が共に大きな値になり、比率がほぼ 1.0 になってしまいます。
- これは「データが常に100付近にある」という事実を示しているだけで、「変動の相関」を示しているわけではありません。
-
demean = FALSEにしてしまうと、平均値が0でない限り、本来知りたい「データの動きの特徴(相関構造)」が、平均値の大きさによって完全に覆い隠されてしまうことがわかります。
以上です。

