
Rで ベクトル誤差修正モデル(VECM) を試みます。
サンプル時系列データは「ともにI(1)」かつ「共和分関係」の2つの時系列データとします。
さらに、1階差分系列の VARモデル による推定結果(共和分を無視(長期構造を無視)し、短期の自己回帰成分のみを考慮した推定結果)とも比較します。
始めにサンプル時系列データを作成します。
モデルは次の通りとし、\(p=2\) とします。
\[\begin{eqnarray}
\Delta Y_t &=& \alpha_y (Y_{t-1} - \beta X_{t-1} - c) + \displaystyle\sum_{i=1}^{p-1} (\gamma_{11,i} \Delta Y_{t-i}) + \displaystyle\sum_{i=1}^{p-1} (\gamma_{12,i} \Delta X_{t-i}) + \epsilon_{yt}\\
\Delta X_t &=& \alpha_x (Y_{t-1} - \beta X_{t-1} - c) + \displaystyle\sum_{i=1}^{p-1} (\gamma_{21,i} \Delta Y_{t-i}) + \displaystyle\sum_{i=1}^{p-1} (\gamma_{22,i} \Delta X_{t-i}) + \epsilon_{xt}
\end{eqnarray}\]
# シミュレーションのパラメータ設定
seed <- 20250605
set.seed(seed)
n_obs <- 1000 # 生成するデータ点の数
# VECMのパラメータ
# 誤差修正項: ECT_t = Y_t - beta * X_t - c_const
alpha_y <- -0.3 # Yの調整係数 (ECT > 0 のとき Y を減少させる)
alpha_x <- 0.15 # Xの調整係数 (ECT > 0 のとき X を増加させ、βXを増やし差を縮める)
beta <- 0.8 # 共和分ベクトルの係数 (Y_t ≈ beta * X_t + c_const)
c_const <- 10 # 共和分関係の定数項
# 差分ラグ項の係数 (p-1 = 1 の場合)
# ΔY_t = ... + gamma11_1*ΔY_{t-1} + gamma12_1*ΔX_{t-1} + ...
# ΔX_t = ... + gamma21_1*ΔY_{t-1} + gamma22_1*ΔX_{t-1} + ...
gamma11_1 <- 0.4 # ΔY_{t-1} が ΔY_t に与える影響
gamma12_1 <- 0.05 # ΔX_{t-1} が ΔY_t に与える影響
gamma21_1 <- 0.1 # ΔY_{t-1} が ΔX_t に与える影響
gamma22_1 <- 0.2 # ΔX_{t-1} が ΔX_t に与える影響
# 誤差項(イノベーション)の標準偏差
sd_eps_y <- 0.1
sd_eps_x <- 0.1
# 初期値の設定
# YとXの初期値
Y_vec <- numeric(n_obs)
X_vec <- numeric(n_obs)
# Y_vec[1] <- 100
# X_vec[1] <- (Y_vec[1] - c_const) / beta # 均衡点に近い値 X = (100-10)/0.8 = 112.5
Y_vec[1] <- 90 # 少し均衡からずらして開始
X_vec[1] <- 100
# ΔYとΔXの初期値 (t=1時点ではラグがないため0とする)
dY_vec <- numeric(n_obs)
dX_vec <- numeric(n_obs)
dY_vec[1] <- 0
dX_vec[1] <- 0
# 誤差修正項を格納するベクトル
ECT_vec <- numeric(n_obs)
# 時系列データの生成ループ (t = 2 から n_obs まで)
for (t in 2:n_obs) {
# 1. 前期の誤差修正項 (ECT_{t-1}) を計算
ECT_current <- Y_vec[t - 1] - beta * X_vec[t - 1] - c_const
ECT_vec[t - 1] <- ECT_current # 保存用
# 2. 誤差項 (ε_yt, ε_xt) を生成
eps_y <- rnorm(1, mean = 0, sd = sd_eps_y)
eps_x <- rnorm(1, mean = 0, sd = sd_eps_x)
# 3. ΔY_t と ΔX_t を計算
dY_vec[t] <- alpha_y * ECT_current +
gamma11_1 * dY_vec[t - 1] +
gamma12_1 * dX_vec[t - 1] +
eps_y
dX_vec[t] <- alpha_x * ECT_current +
gamma21_1 * dY_vec[t - 1] +
gamma22_1 * dX_vec[t - 1] +
eps_x
# 4. Y_t と X_t を計算 (レベルデータ)
Y_vec[t] <- Y_vec[t - 1] + dY_vec[t]
X_vec[t] <- X_vec[t - 1] + dX_vec[t]
}
# 最後のECTを計算
ECT_vec[n_obs] <- Y_vec[n_obs] - beta * X_vec[n_obs] - c_const
# 生成されたデータをデータフレームにまとめる
sim_data <- tidyr::tibble(
Time = 1:n_obs,
Y = Y_vec,
X = X_vec,
Delta_Y = dY_vec,
Delta_X = dX_vec,
ECT = ECT_vec
)作成したサンプル時系列データを可視化します。
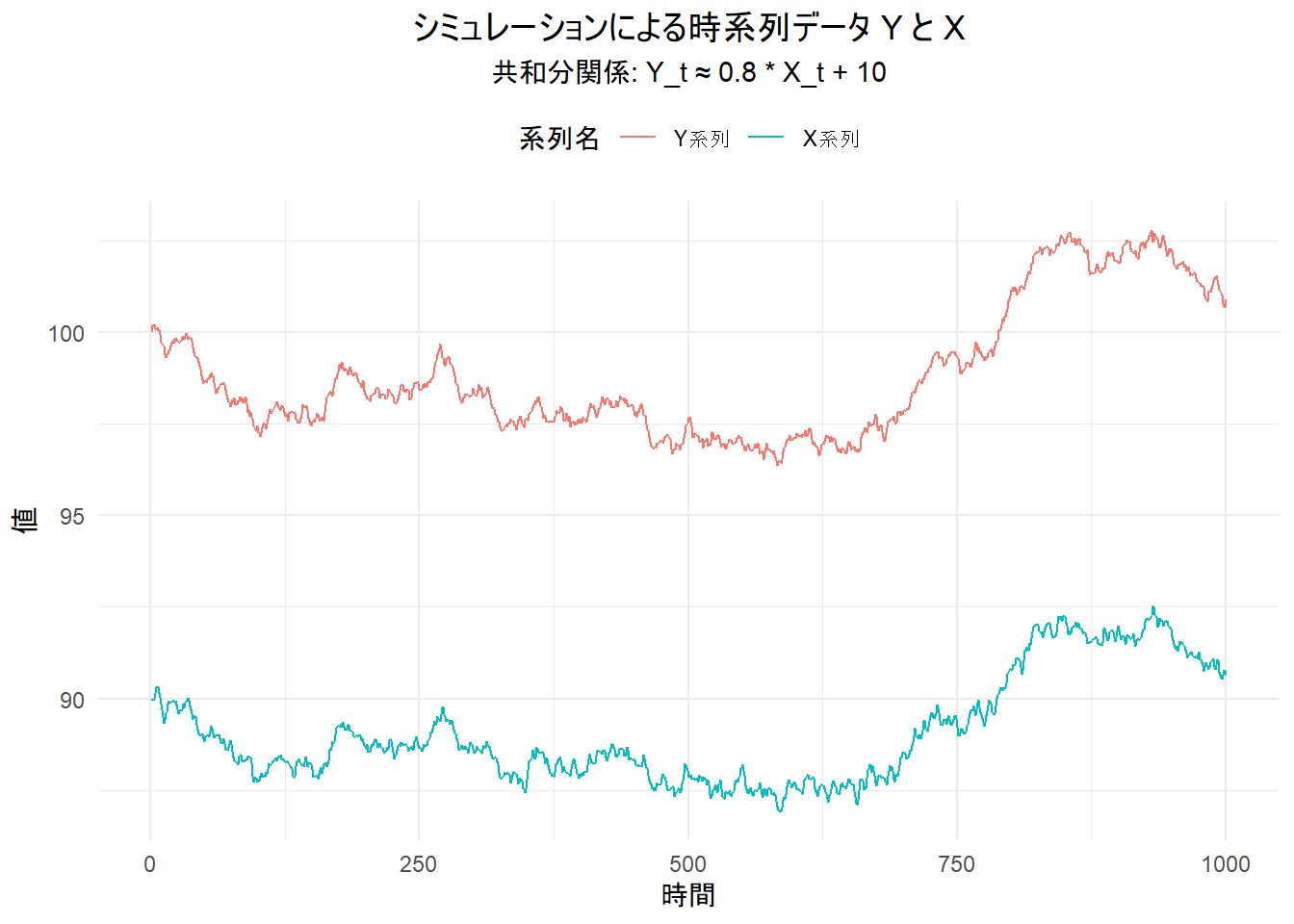
始めに Y と X の時系列プロット (レベルデータ)
library(ggplot2)
ggplot(sim_data, aes(x = Time)) +
geom_line(aes(y = Y, colour = "Y系列")) +
geom_line(aes(y = X, colour = "X系列")) +
labs(
title = "シミュレーションによる時系列データ Y と X",
subtitle = paste0("共和分関係: Y_t ≈ ", beta, " * X_t + ", c_const),
y = "値",
x = "時間",
colour = "系列名"
) +
scale_colour_manual(
values = c("Y系列" = "#00BFC4", "X系列" = "#F8766D"),
labels = c("Y系列", "X系列")
) +
theme_minimal() +
theme(
legend.position = "top",
plot.title = element_text(hjust = 0.5),
plot.subtitle = element_text(hjust = 0.5)
)
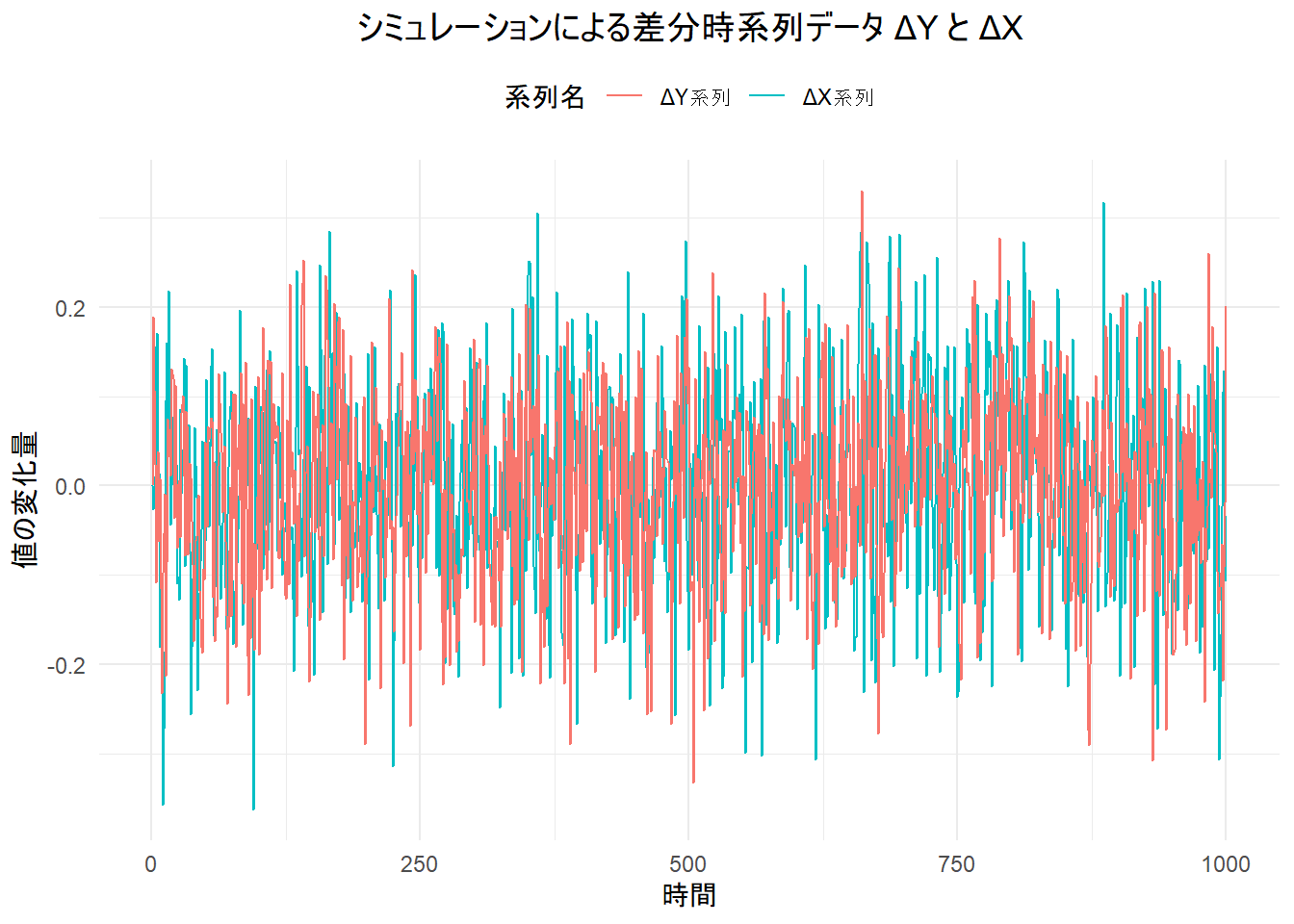
続いて ΔY と ΔX の時系列プロット (差分データ)
ggplot(sim_data, aes(x = Time)) +
geom_line(aes(y = Delta_Y, colour = "ΔY系列")) +
geom_line(aes(y = Delta_X, colour = "ΔX系列")) +
labs(
title = "シミュレーションによる差分時系列データ ΔY と ΔX",
y = "値の変化量",
x = "時間",
colour = "系列名"
) +
scale_colour_manual(
values = c("ΔY系列" = "#00BFC4", "ΔX系列" = "#F8766D"),
labels = c("ΔY系列", "ΔX系列")
) +
theme_minimal() +
theme(
legend.position = "top",
plot.title = element_text(hjust = 0.5)
)
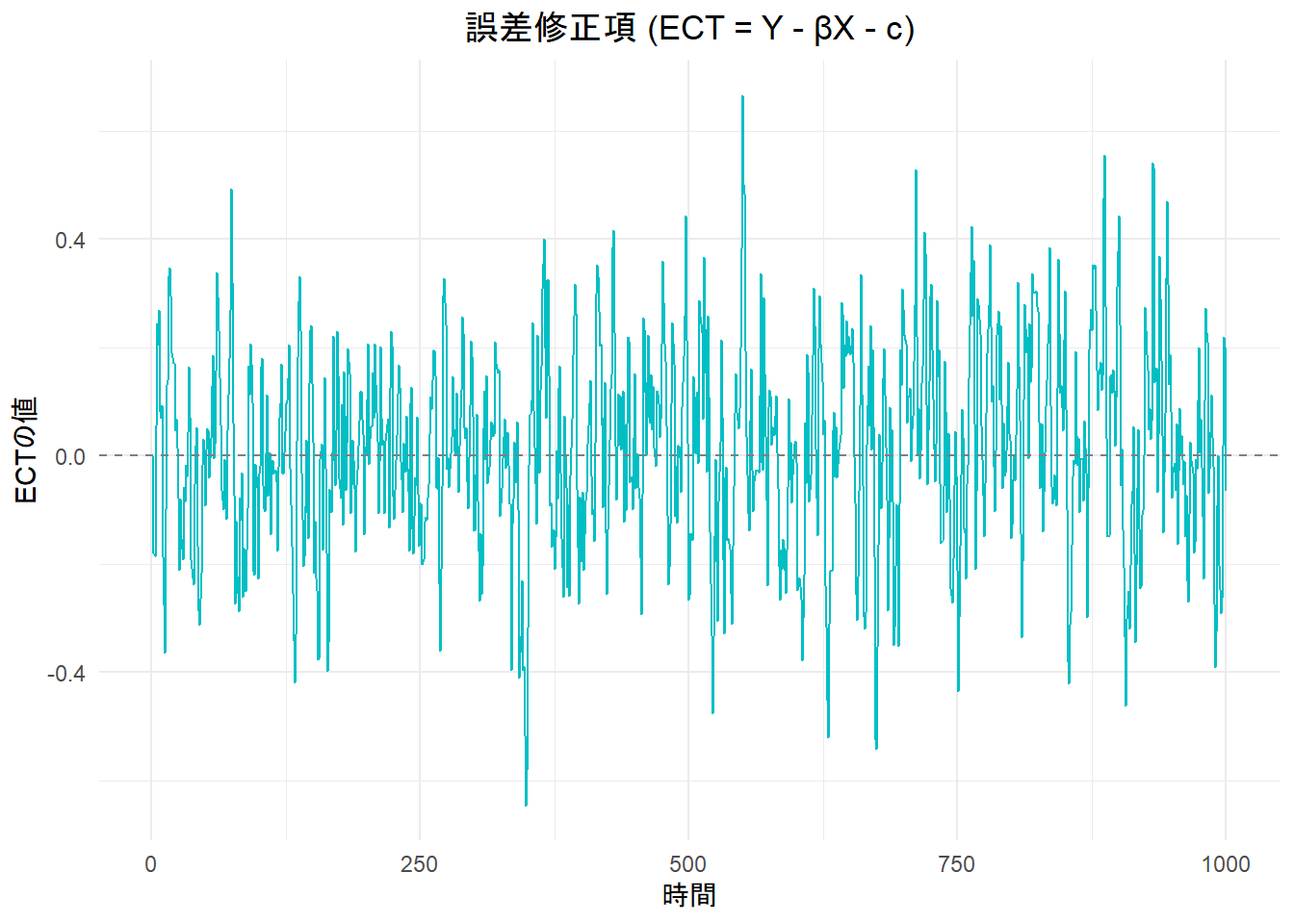
最後は 誤差修正項(ECT) の時系列プロット
ggplot(sim_data, aes(x = Time, y = ECT)) +
geom_line(colour = "#00BFC4") +
geom_hline(yintercept = 0, linetype = "dashed", color = "gray50") +
labs(
title = "誤差修正項 (ECT = Y - βX - c)",
y = "ECTの値",
x = "時間"
) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5),
plot.subtitle = element_text(hjust = 0.5)
)
X と Y を 単位根検定 に掛けます。
library(tseries)
adf.test(sim_data$X)
adf.test(sim_data$Y)
Augmented Dickey-Fuller Test
data: sim_data$X
Dickey-Fuller = -1.8454, Lag order = 9, p-value = 0.6438
alternative hypothesis: stationary
Augmented Dickey-Fuller Test
data: sim_data$Y
Dickey-Fuller = -2.0204, Lag order = 9, p-value = 0.5697
alternative hypothesis: stationaryX と Y の 1階差分 を 単位根検定 に掛けます。
adf.test(sim_data$Delta_X)
adf.test(sim_data$Delta_Y)
Augmented Dickey-Fuller Test
data: sim_data$Delta_X
Dickey-Fuller = -9.9985, Lag order = 9, p-value = 0.01
alternative hypothesis: stationary
Augmented Dickey-Fuller Test
data: sim_data$Delta_Y
Dickey-Fuller = -10.875, Lag order = 9, p-value = 0.01
alternative hypothesis: stationaryX と Y はいずれも I(1) として先に進めます(有意水準5%。以降同様)。
Johansen共和分検定 に掛けます。
なお、サンプルの 誤差修正項 は ECT_t = Y_t - beta * X_t - c_const としているため、引数ecdet は const とします。
library(urca)
jo_test <- ca.jo(sim_data[, c("X", "Y")], type = "trace", ecdet = "const", K = 2)
summary(jo_test)
######################
# Johansen-Procedure #
######################
Test type: trace statistic , without linear trend and constant in cointegration
Eigenvalues (lambda):
[1] 2.158383e-01 8.938508e-04 3.913292e-19
Values of teststatistic and critical values of test:
test 10pct 5pct 1pct
r <= 1 | 0.89 7.52 9.24 12.97
r = 0 | 243.55 17.85 19.96 24.60
Eigenvectors, normalised to first column:
(These are the cointegration relations)
X.l2 Y.l2 constant
X.l2 1.000000 1.0000000 1.0000000
Y.l2 -1.234296 0.3805141 0.5252412
constant 11.119047 -133.1490597 -132.3011732
Weights W:
(This is the loading matrix)
X.l2 Y.l2 constant
X.d -0.1377920 -0.0010179111 1.711838e-15
Y.d 0.2111135 -0.0006899352 -2.585327e-15共和分関係なし(r = 0) が棄却され、1つの共和分関係あり(r <= 1) が棄却できません。
そのうえで、共和分ベクトル(固有ベクトル)の1列目(1つ目の共和分関係)を確認しますと、
1 * X.l2 - 1.234296 * Y.l2 + 11.119047 * constant = (定常誤差)
→ X_t - 1.234296 * Y_t + 11.119047 = (定常誤差)
→ -1.234296 * Y_t = -1 * X_t - 11.119047 + (定常誤差)
→ Y_t = (1 / 1.234296) * X_t + (11.119047 / 1.234296) + (新しい定常誤差)
→ Y_t ≈ 0.8101784 * X_t + 9.008412
となり、誤差修正項である y = 0.8(beta) × x + 10(c_const) に近くなっています。
VECMモデル(rank = 1) を推定します。
# ect は Error Correction Term(誤差修正項)
vecm_model <- cajorls(jo_test, r = 1)
summary(vecm_model$rlm)Response X.d :
Call:
lm(formula = X.d ~ ect1 + X.dl1 + Y.dl1 - 1, data = data.mat)
Residuals:
Min 1Q Median 3Q Max
-0.32748 -0.06522 0.00518 0.07032 0.28287
Coefficients:
Estimate Std. Error t value Pr(>|t|)
ect1 -0.13779 0.01493 -9.232 < 2e-16 ***
X.dl1 0.09786 0.03053 3.205 0.00139 **
Y.dl1 0.28304 0.02831 10.000 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.09744 on 995 degrees of freedom
Multiple R-squared: 0.153, Adjusted R-squared: 0.1504
F-statistic: 59.91 on 3 and 995 DF, p-value: < 2.2e-16
Response Y.d :
Call:
lm(formula = Y.d ~ ect1 + X.dl1 + Y.dl1 - 1, data = data.mat)
Residuals:
Min 1Q Median 3Q Max
-0.298265 -0.066062 0.000046 0.072941 0.299548
Coefficients:
Estimate Std. Error t value Pr(>|t|)
ect1 0.21111 0.01527 13.824 < 2e-16 ***
X.dl1 0.27478 0.03124 8.796 < 2e-16 ***
Y.dl1 0.15303 0.02896 5.284 1.55e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.0997 on 995 degrees of freedom
Multiple R-squared: 0.2356, Adjusted R-squared: 0.2333
F-statistic: 102.2 on 3 and 995 DF, p-value: < 2.2e-16\[\begin{eqnarray}
\Delta x_t &=& -0.13779 \cdot\textrm{ECT}_{t-1} + 0.09786 \cdot \Delta x_{t-1} + 0.28304 \cdot\Delta y_{t-1} + \epsilon_{xt} \\
\Delta y_t &=& 0.21111 \cdot\textrm{ECT}_{t-1} + 0.27478 \cdot \Delta x_{t-1} + 0.15303 \cdot\Delta y_{t-1} + \epsilon_{yt} \\
\textrm{ECT}_{t-1} &=& x_{t-1} - 1.234296 \cdot y_{t-1} + 11.119047
\end{eqnarray}\]
続いて、作成した VECMモデル を利用して、Y の当てはめ処理(Fitting)を行います。
library(dplyr)
# p_level_var = nrow(sim_data) - nrow(vecm_model$rlm$model)
p_level_var <- 2
cat(paste0("VECMの基礎となるレベルVARのラグ次数 (p_level_var): ", p_level_var, "\n"))
# ΔYの当てはめ値を取得
delta_Y_fitted_vecm <- vecm_model$rlm$fitted.values[, "Y.d"]
cat(paste0("VECMによるΔYの当てはめ値の数: ", length(delta_Y_fitted_vecm), "\n"))
# Yのレベルの当てはめ値を計算
# delta_Y_fitted_vecm[j] は、元の時系列の ΔY_{j + p_level_var} の当てはめ。
# Y_fitted_vecm[j] は、元の Y_{j + p_level_var} の当てはめ。
# Y_{j + p_level_var} (fit) = Y_{j + p_level_var - 1} (act) + ΔY_{j + p_level_var} (fit)
Y_fitted_vecm <- numeric(length(delta_Y_fitted_vecm))
for (j in 1:length(delta_Y_fitted_vecm)) {
Y_fitted_vecm[j] <- sim_data$Y[j + p_level_var - 1] + delta_Y_fitted_vecm[j]
}
cat(paste0("VECMによるYのレベルの当てはめ値の数: ", length(Y_fitted_vecm), "\n"))
# 比較のため、実際のYも同じ期間に合わせる
# VECMの推定には最初の p_level_var 個の観測値がラグとして使われるため、
# 当てはめ/予測は (p_level_var + 1) 番目の観測から始まる。
actual_Y_for_vecm <- sim_data$Y[(p_level_var + 1):nrow(sim_data)]
cat(paste0("VECM比較用の実測Yのデータ数: ", length(actual_Y_for_vecm), "\n"))VECMの基礎となるレベルVARのラグ次数 (p_level_var): 2
VECMによるΔYの当てはめ値の数: 998
VECMによるYのレベルの当てはめ値の数: 998
VECM比較用の実測Yのデータ数: 998X と Y の 1階差分同士の VARモデル を作成し、差分VARモデル による Y の当てはめ処理を行います。
# 差分データを準備
diff_data <- sim_data %>%
mutate(
Delta_X_actual = c(NA, diff(X)),
Delta_Y_actual = c(NA, diff(Y))
) %>%
select(Delta_X_actual, Delta_Y_actual) %>%
na.omit() # 最初のNA行を削除
cat(paste0("差分データの行数: ", nrow(diff_data), "\n"))
# 差分VARのラグ次数 p_diff_var は、VECMの p_level_var - 1 に相当
p_diff_var <- p_level_var - 1
cat(paste0("差分VARモデルのラグ次数 (p_diff_var): ", p_diff_var, "\n"))
# 差分VARモデルを推定
dvar_model <- vars::VAR(diff_data, p = p_diff_var, type = "const")
# 差分VARモデルでΔYを予測
fitted_dvar_output <- fitted(dvar_model)
delta_Y_fitted_dvar <- fitted_dvar_output[, "Delta_Y_actual"]
cat(paste0("差分VARによるΔYの当てはめ値の数: ", length(delta_Y_fitted_dvar), "\n"))
# Yのレベルの当てはめ値を計算
# delta_Y_fitted_dvar[j] は、元の時系列の ΔY_{j + p_diff_var + 1} の当てはめ。
# Y_fitted_dvar[j] は、元の Y_{j + p_diff_var + 1} の当てはめ。
# Y_{j + p_diff_var + 1} (fit) = Y_{j + p_diff_var} (act) + ΔY_{j + p_diff_var + 1} (fit)
Y_fitted_dvar <- numeric(length(delta_Y_fitted_dvar))
for (j in 1:length(delta_Y_fitted_dvar)) {
Y_fitted_dvar[j] <- sim_data$Y[j + p_diff_var] + delta_Y_fitted_dvar[j]
}
cat(paste0("差分VARによるYのレベルの当てはめ値の数: ", length(Y_fitted_dvar), "\n"))
# 比較のため、実際のYも同じ期間に合わせる
# 差分系列のVAR(p_diff_var)では、
# 1. 差分を取るために最初の1観測が失われる
# 2. VARのラグとして最初のp_diff_var観測が失われる
# よって、当てはめ/予測は元の時系列の (1 + p_diff_var + 1) = (p_diff_var + 2) 番目の観測から始まる。
actual_Y_for_dvar <- sim_data$Y[(p_diff_var + 2):nrow(sim_data)]
cat(paste0("差分VAR比較用の実測Yのデータ数: ", length(actual_Y_for_dvar), "\n"))差分データの行数: 999
差分VARモデルのラグ次数 (p_diff_var): 1
差分VARによるΔYの当てはめ値の数: 998
差分VARによるYのレベルの当てはめ値の数: 998
差分VAR比較用の実測Yのデータ数: 998VECMモデル と 差分VARモデル それぞれの 平均二乗誤差(MSE) と 平均絶対誤差(MAE) を確認します。
cat("\n--- モデル比較 (Yの当てはめ精度) ---\n")
# VECMの評価指標
mse_vecm <- Metrics::mse(actual_Y_for_vecm, Y_fitted_vecm)
mae_vecm <- Metrics::mae(actual_Y_for_vecm, Y_fitted_vecm)
cat("VECM:\n")
cat(paste0(" 平均二乗誤差 (MSE): ", round(mse_vecm, 6), "\n"))
cat(paste0(" 平均絶対誤差 (MAE): ", round(mae_vecm, 6), "\n"))
cat(paste0(" 評価に使用した観測点の数: ", length(actual_Y_for_vecm), "\n"))
# 差分VARの評価指標
mse_dvar <- Metrics::mse(actual_Y_for_dvar, Y_fitted_dvar)
mae_dvar <- Metrics::mae(actual_Y_for_dvar, Y_fitted_dvar)
cat("\n差分VAR (dVAR):\n")
cat(paste0(" 平均二乗誤差 (MSE): ", round(mse_dvar, 6), "\n"))
cat(paste0(" 平均絶対誤差 (MAE): ", round(mae_dvar, 6), "\n"))
cat(paste0(" 評価に使用した観測点の数: ", length(actual_Y_for_dvar), "\n"))
--- モデル比較 (Yの当てはめ精度) ---
VECM:
平均二乗誤差 (MSE): 0.00991
平均絶対誤差 (MAE): 0.0806
評価に使用した観測点の数: 998
差分VAR (dVAR):
平均二乗誤差 (MSE): 0.011813
平均絶対誤差 (MAE): 0.087067
評価に使用した観測点の数: 998長期的な均衡を考慮しているVECMモデル の方が、差分VARモデル よりも当てはめ精度が高く、共和分 を確認せずに 差分VARモデル で話を進めるのは宜しく無い、というお話しでした。
以上です。

