
Rで ランダム化比較試験:クラスターランダム化比較試験(Cluster Randomized Controlled Trial, CRCT) のシミュレーションを試みます。
なお、以下の架空のストーリー中の会社名、商品名は実在の団体や商品とは関係ありません。
【背景】
全国に多くの小学校を展開する大手教育法人「サイエンス学園」は、児童の理科への興味関心を高めるため、新しい体験型学習プログラム「サイエンス大好き」を開発しました。このプログラムは、教師向けの特別な研修と、児童がグループで実験に取り組むための専用キットで構成されています。
【研究の目的】
この研究の目的は、小学5年生において、新しい学習プログラム「サイエンス大好き」が、従来の教科書中心の授業と比較して、理科学習に対する意欲を向上させる効果があるかを科学的に検証することです。
【研究デザイン:クラスターランダム化比較試験】
- 選択デザイン: クラスターランダム化比較試験を選択。
- もし、同じ学校内のクラスをランダムに分けて、あるクラスは「サイエンス大好き」を、別のクラスは従来通りの授業を行った場合、
- 新しいプログラムを受けた児童が、休み時間に他のクラスの友達に「今日の実験、すごく面白かったよ!」と話すかもしれません。
- 担当する教師同士が、職員室でプログラムの内容について情報交換するかもしれません。
- このように、介入群(新しいプログラム)の情報や影響が対照群(従来の授業)に伝わってしまう(Contamination)可能性があり、その結果、対照群に影響が及んでしまい、プログラムの真の効果を正しく測定できなくなる可能性があります。
- Contaminationを防ぐため、個人やクラス単位ではなく、もっと大きな集団(=クラスター)ごとランダムに割り付ける必要があり、今回のシナリオでは、「学校」を一つのクラスターとします。
- もし、同じ学校内のクラスをランダムに分けて、あるクラスは「サイエンス大好き」を、別のクラスは従来通りの授業を行った場合、
- クラスター: サイエンス学園が運営する小学校 20校。
- 参加者: 各学校に所属する小学5年生全員。
- ランダム化: 学校単位でランダム化を行います。20校を無作為に10校ずつのグループに分けます。
- 介入群 (Intervention Group): 10校の小学校。これらの学校では、5年生の理科の授業で「サイエンス大好き」を半年間実施します。
- 対照群 (Control Group): 10校の小学校。これらの学校では、従来通りの教科書中心の授業を続けます。
- 介入: 介入群の学校の教師は「サイエンス大好き」の研修を受け、授業で専用キットを使用します。
- 評価項目:
- 主要評価項目: 半年後の「理科学習意欲スコア」。アンケート調査によって測定し、1点(全く意欲がない)から10点(非常に意欲がある)で評価します。
- 仮説: 「サイエンス大好き」を導入した学校(介入群)の児童は、従来の授業を続けた学校(対照群)の児童よりも、理科学習意欲スコアが高くなるだろう。
【ストーリーの流れ】
- 研究に参加することに同意したサイエンス学園の小学校20校をリストアップします。
- 乱数によって、20校を介入群(10校)と対照群(10校)にランダムに割り振ります。
- 介入群の学校にのみ、新しいプログラムの教材と研修を提供します。
- 半年間、各学校は割り当てられた方法で理科の授業を実施します。
- 半年後、全20校の5年生全員を対象に、理科学習意欲に関するアンケート調査を行います。
- データ解析チームが、介入群の学校の児童の平均スコアと、対照群の学校の児童の平均スコアを比較します。このとき、「同じ学校の児童の回答は、互いに似通う傾向がある」というクラスターの特性を考慮した混合効果モデルを用いて分析します。
続いてシミュレーションに入ります。
ステップ1: 初期設定
# パラメータ設定
n_schools <- 20 # クラスター(学校)の数
n_students_per_school <- 30 # 各学校の生徒数
n_total_students <- n_schools * n_students_per_school # 全生徒数ステップ2: データフレームの作成とクラスター単位でのランダム化
まず、20校の学校データを作成し、学校単位でランダムに介入群と対照群に割り当てます。
seed <- 20250614
set.seed(seed)
library(dplyr)
# 学校(クラスター)レベルのデータ作成
schools_data <- data.frame(
school_id = 1:n_schools
)
# 学校をランダムに介入群と対照群に割り当てる
schools_data$group <- sample(
rep(c("Intervention", "Control"), times = n_schools / 2)
)
# 生徒レベルのデータを作成
# expand.gridで学校と生徒の組み合わせを全通り作成
students_data <- expand.grid(
student_in_school_id = 1:n_students_per_school,
school_id = 1:n_schools
) %>%
# 学校データと結合して、各生徒がどのグループに属するかを決める
left_join(schools_data, by = "school_id") %>%
# 各生徒にユニークなIDを付与
mutate(student_id = row_number())
cat("\n--- students_data の一部 ---\n\n")
head(students_data)
tail(students_data)
--- students_data の一部 ---
student_in_school_id school_id group student_id
1 1 1 Intervention 1
2 2 1 Intervention 2
3 3 1 Intervention 3
4 4 1 Intervention 4
5 5 1 Intervention 5
6 6 1 Intervention 6
student_in_school_id school_id group student_id
595 25 20 Control 595
596 26 20 Control 596
597 27 20 Control 597
598 28 20 Control 598
599 29 20 Control 599
600 30 20 Control 600ステップ3: 結果(学習意欲スコア)の生成
「同じ学校(クラスター)にいると似通う」という性質を再現するために、「学校ごとのランダム効果」としてモデル化します。
- 基礎意欲スコア: 全体の平均は4点。
- 学校効果(ランダム効果): 学校ごとに教育方針や地域性が異なるため、意欲スコアのベースラインが学校ごとに少しずつ違う。これを平均0、標準偏差0.5の正規分布で表現します。これがクラスター効果です。
- プログラムの効果: 「サイエンス大好き」は、意欲スコアを平均で 1.5点 引き上げると仮定します。
- 個人差: 同じ学校内でも、個人の興味や能力に差があるため、ばらつき(標準偏差1)を設けます。
set.seed(seed)
# 学校ごとのランダム効果(クラスター効果)を生成
schools_data <- schools_data %>%
mutate(school_effect = rnorm(n_schools, mean = 0, sd = 0.5))
# 生徒データに学校効果をマージ
students_data <- students_data %>%
left_join(select(schools_data, school_id, school_effect), by = "school_id")
# 学習意欲スコアを生成
students_data <- students_data %>%
mutate(
motivation_score = 4.0 + # 全体の平均
school_effect + # 学校ごとの効果(クラスター効果)
ifelse(group == "Intervention", 1.5, 0.0) + # 介入効果
rnorm(n(), mean = 0, sd = 1.0) # 個人のばらつき
)
cat("\n--- students_data の一部 ---\n\n")
head(students_data)
tail(students_data)
cat("\n--- 生徒の学習意欲スコアの範囲 ---\n\n")
students_data$motivation_score %>% range()
--- students_data の一部 ---
student_in_school_id school_id group student_id school_effect
1 1 1 Intervention 1 -0.257691
2 2 1 Intervention 2 -0.257691
3 3 1 Intervention 3 -0.257691
4 4 1 Intervention 4 -0.257691
5 5 1 Intervention 5 -0.257691
6 6 1 Intervention 6 -0.257691
motivation_score
1 4.973787
2 6.924002
3 3.718078
4 6.884850
5 4.040664
6 5.975341
student_in_school_id school_id group student_id school_effect
595 25 20 Control 595 -0.5697998
596 26 20 Control 596 -0.5697998
597 27 20 Control 597 -0.5697998
598 28 20 Control 598 -0.5697998
599 29 20 Control 599 -0.5697998
600 30 20 Control 600 -0.5697998
motivation_score
595 1.998908
596 3.526390
597 3.166668
598 2.281895
599 3.579225
600 3.747352
--- 生徒の学習意欲スコアの範囲 ---
[1] 1.262442 8.380499ステップ4: 可視化
クラスター構造を持つデータを可視化します。
library(ggplot2)
ggplot(students_data, aes(x = factor(school_id), y = motivation_score, fill = group)) +
geom_boxplot() +
labs(
title = "学校(クラスター)ごとの理科学習意欲スコア",
subtitle = "同じ色の箱は同じグループに属する学校を示す",
x = "学校ID",
y = "学習意欲スコア (1-10)"
) +
theme(axis.text.x = element_text(angle = 90))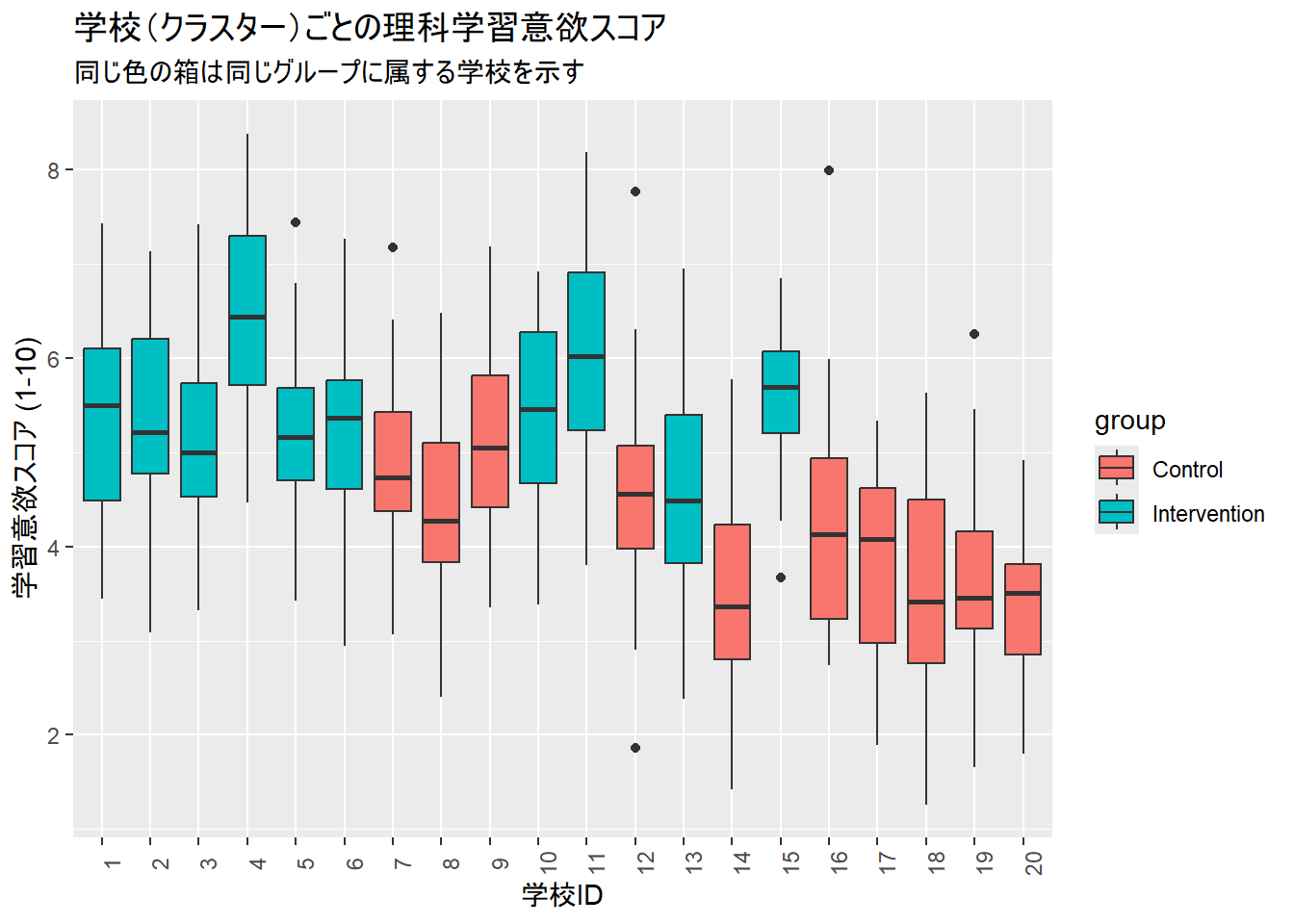
グラフを見ると、介入群(Intervention)の学校は、全体的に対照群(Control)の学校よりもスコアが高い傾向にあります。また、同じ色の中でも箱の位置(中央値)が少しずつ違うことが分かります。これが「学校効果(クラスター効果)」です。
ステップ5: 統計的検定(混合効果モデル)
CRCTのデータを分析する際、もし通常のt検定を使ってしまうと、「同じ学校のデータは独立ではない」という前提を無視することになり、誤って効果を評価してしまう危険性があります。
ここでは、クラスター構造を正しく扱うために線形混合効果モデル (lmer) を用います。
-
motivation_score ~ group: 学習意欲スコアをグループ(介入/対照)によって説明する部分(固定効果)。私たちが見たいプログラムの効果はここに含まれます。 -
(1 | school_id): スコアの切片(ベースライン)がschool_idごとに異なることを許容する部分(ランダム効果)。これによりクラスター効果をモデルに組み込みます。
# 混合効果モデルで分析
# `(1 | school_id)` がクラスター効果を考慮する部分
model <- lmerTest::lmer(motivation_score ~ group + (1 | school_id), data = students_data)
# 結果の要約を表示
summary(model)Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: motivation_score ~ group + (1 | school_id)
Data: students_data
REML criterion at convergence: 1786.6
Scaled residuals:
Min 1Q Median 3Q Max
-2.5921 -0.6908 -0.0062 0.6424 3.6838
Random effects:
Groups Name Variance Std.Dev.
school_id (Intercept) 0.3094 0.5562
Residual 1.0642 1.0316
Number of obs: 600, groups: school_id, 20
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 4.0953 0.1857 18.0000 22.053 1.77e-14 ***
groupIntervention 1.3861 0.2626 18.0000 5.278 5.11e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
grpIntrvntn -0.707ステップ6: 結果の解釈と結論
summary(model) の出力から、特に Fixed effects の部分に注目します。
-
groupInterventionのEstimate:1.3861- これは、対照群(Control)と比較して、介入群(Intervention)のスコアが平均で約1.3861点高いことを示しています。シミュレーションで設定した効果(1.5)に近い値が得られました。
-
Pr(>|t|)(p値):5.11e-05- p値が研究デザインで定めた有意水準を下回っていますので、「グループ間の差は統計的に有意である」と判断します。
【シミュレーション全体のまとめ】
このシミュレーションは、サイエンス学園が行ったクラスターランダム化比較試験の結果を模したものです。学校単位でランダム化することでContaminationを防ぎ、混合効果モデルによる分析で「同じ学校の生徒は似ている」というクラスターの特性を考慮しました。
その結果、新しい体験型学習プログラム「サイエンス大好き」は、従来の授業に比べて、児童の理科学習意欲を有意に向上させる効果があることが示されました。この科学的根拠に基づき、サイエンス学園は全国の系列校にこのプログラムを導入することを決定するでしょう。
以上です。

