
Rで ランダム化比較試験:並行群間比較試験(Parallel study) のシミュレーションを試みます。
なお、以下の架空のストーリー中の会社名、商品名は実在の団体や商品とは関係ありません。
【背景】
大手製薬会社の「快眠製薬」は、長年の研究の末、新しい睡眠改善薬「ヨクネムール」を開発しました。動物実験では有望な結果が得られており、いよいよヒトでの有効性を確認する段階に来ています。
【研究の目的】
この研究の目的は、軽度の睡眠障害に悩む成人において、新薬「ヨクネムール」がプラセボ(偽薬)と比較して、客観的に測定された総睡眠時間を延長させる効果があるかを科学的に検証することです。
【研究デザイン:Parallel Study】
- 参加者: 軽度の睡眠障害を持つ成人100名。参加者は研究内容について十分な説明を受け、同意しています。
- 介入内容:
- 介入群 (Treatment Group): 毎晩就寝前に「ヨクネムール」を1錠、4週間服用する。
- 対照群 (Control Group): 毎晩就寝前に、見た目も味も全く同じ「プラセボ(偽薬)」を1錠、4週間服用する。
- ランダム化: 参加者100名は、コンピューターによる無作為割り付け(ランダム化)によって、50名が介入群、50名が対照群に割り振られます。誰がどちらのグループに入るかは完全に偶然で決まります。
- 盲検化: これは二重盲検試験として行われます。つまり、参加者自身も、データを収集する医師や研究者も、誰が「ヨクネムール」を服用し、誰が「プラセボ」を服用しているのか、試験が終了してデータが解析されるまで知りません。
- 評価項目:
- 主要評価項目: 試験開始から4週間後の「1晩あたりの平均総睡眠時間(分)」。ウェアラブルデバイスを用いて客観的に測定します。
- 仮説: 「ヨクネムール」を服用した介入群は、プラセボを服用した対照群よりも、4週間後の平均総睡眠時間が長くなるだろう。
- 統計検定における有意水準: 5%とします。
【ストーリーの流れ】
- 募集された100名の参加者は、ランダムに介入群と対照群に分けられます。
- 各参加者は、識別番号が振られたボトルを受け取ります。中身が本物の薬か偽薬かは誰にも知らされません。
- 参加者は4週間にわたって薬を服用し、毎日の睡眠時間が記録されます。
- 4週間後、すべてのデータが集められます。
- ここで初めて「開鍵(Unblinding)」が行われ、誰がどちらのグループだったかが明らかにされます。
- データ解析チームが、介入群と対照群の平均睡眠時間を比較し、統計的な差があるかどうかを評価します。
続いてシミュレーションに入ります。
ステップ1: シミュレーションの初期設定
# パラメータ設定
N_total <- 100 # 全参加者数
N_group <- N_total / 2 # 各グループの参加者数ステップ2: データフレームの作成とランダム化
100人の参加者を作成し、ランダムに「介入群 (Treatment)」と「対照群 (Control)」に割り当てます。
seed <- 20250614
set.seed(seed)
# 参加者データフレームの作成
study_data <- data.frame(
participant_id = 1:N_total
)
# ランダムにグループを割り当てる
study_data$group <- sample(
rep(c("Treatment", "Control"), times = N_group)
)
head(study_data) participant_id group
1 1 Treatment
2 2 Treatment
3 3 Treatment
4 4 Treatment
5 5 Treatment
6 6 Controlステップ3: 結果(睡眠時間)の生成
シナリオに基づき、各グループの睡眠時間を生成します。ここでは、以下のように効果を仮定します。
- 基礎睡眠時間: もともとの平均睡眠時間は390分(6.5時間)で、個人差(標準偏差30分)がある。
- プラセボ効果: 対照群(Control)は、偽薬でも期待感などから平均10分睡眠が伸びる。
- ヨクネムールの効果: 介入群(Treatment)は、プラセボ効果に加えて、薬の純粋な効果でさらに25分睡眠が伸びる(合計+35分)。
# 各グループの睡眠時間を生成
# group列の値に応じて、平均値を変えて睡眠時間を生成する
set.seed(seed)
library(dplyr)
study_data <- study_data %>%
mutate(
sleep_duration = case_when(
group == "Treatment" ~ rnorm(n(), mean = 390 + 35, sd = 30),
group == "Control" ~ rnorm(n(), mean = 390 + 10, sd = 30)
)
)
head(study_data) participant_id group sleep_duration
1 1 Treatment 409.5385
2 2 Treatment 426.6562
3 3 Treatment 419.6019
4 4 Treatment 496.2221
5 5 Treatment 413.8731
6 6 Control 377.4600ステップ4: データ集計と可視化
グループごとに平均睡眠時間を計算し、グラフで比較します。
# グループごとの要約統計量を計算
summary_stats <- study_data %>%
group_by(group) %>%
summarise(
count = n(),
mean_sleep = mean(sleep_duration),
sd_sleep = sd(sleep_duration)
)
print(summary_stats)# A tibble: 2 × 4
group count mean_sleep sd_sleep
<chr> <int> <dbl> <dbl>
1 Control 50 394. 28.0
2 Treatment 50 431. 32.1平均睡眠時間は、対照群が394分、介入群が431分となり、介入群の方が長いことがわかります。
箱ひげ図で確認します。
library(ggplot2)
ggplot(study_data, aes(x = group, y = sleep_duration, fill = group)) +
geom_boxplot() +
labs(
title = "睡眠改善薬「ヨクネムール」の効果検証",
subtitle = "Parallel Studyのシミュレーション結果",
x = "グループ",
y = "平均総睡眠時間(分)"
) +
theme_minimal() +
scale_fill_manual(values = c("Control" = "skyblue", "Treatment" = "orange"))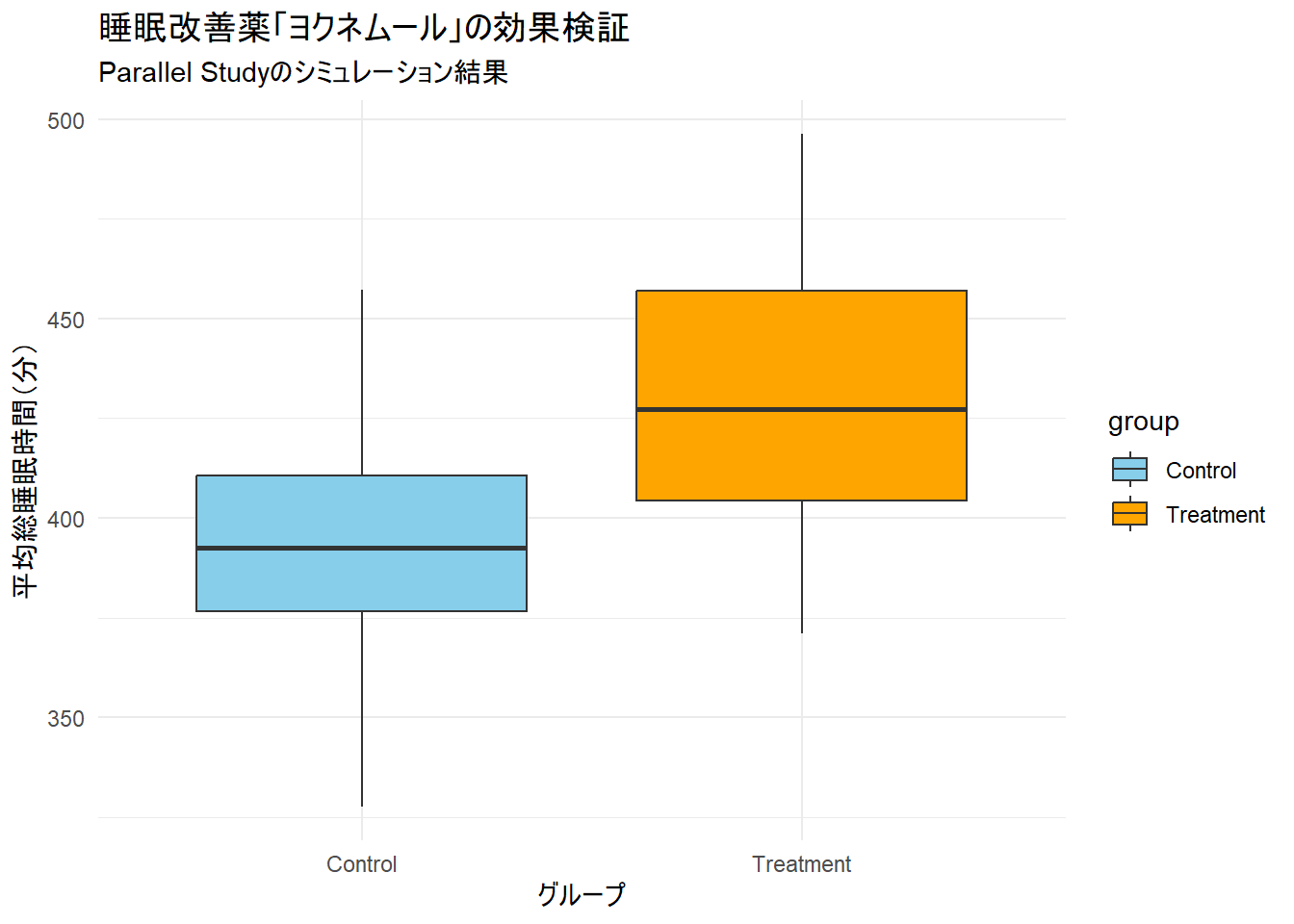
介入群(Treatment)の睡眠時間の分布全体が、対照群(Control)よりも上方にシフトしていることが確認できます。
ステップ5: 統計的検定(t検定)
この平均値の差が、単なる偶然によるものではなく、統計的に意味のある(有意な)差なのかを検定します。2つの独立したグループの平均値の差を比較するため、t検定を用います。
なお、引数は以下の通りとします。
-
alternative = "two.sided"- 意味: 「両側検定」とします。これは、「介入群の平均値が対照群と異なるかどうか」を検定するものです。つまり、介入群の方が良くても(睡眠時間が長くても)、悪くても(睡眠時間が短くても)、とにかく差があるか否かを検定します。
- 今回のシナリオ: 新薬の効果は未知数であり、「睡眠時間を延長する」という期待はあるものの、「逆に短くしてしまう」可能性も理論上はゼロではありません。そのため、どちらの方向の差も検出できる両側検定を採用します。
- 参考として、
alternative = "greater"とすると、「介入群の睡眠時間が対照群より長いこと」のみを検定することになります。
-
mu = 0- 意味: 帰無仮説(棄却したい仮説)における「2群の平均値の差 (μ)」を設定します。
mu = 0は、「2群の母平均に差がない(μ_treatment – μ_control = 0)」という仮説を検定することを意味します。 - 今回のシナリオ: 知りたいのは「薬の効果があるかないか」なので、「2群の間に差がない」という状態を基準に検定するため
mu = 0とおきます。
- 意味: 帰無仮説(棄却したい仮説)における「2群の平均値の差 (μ)」を設定します。
-
paired = FALSE- 意味: 独立2群のt検定(Independent two-sample t-test)とします。
- 今回のシナリオ: 今回はParallel studyですので、介入群と対照群は全く別の参加者で構成されています。よって、2つのグループは独立であるため、
paired = FALSEとおきます。 - 但し、今回は引数
formulaを利用しますので設定不要です。 - 参考として、クロスオーバー試験のように「同じ参加者」が両方の治療を受けるのであれば、
paired = TRUEを設定します。
-
var.equal = FALSE- 意味: 「2つのグループの分散が等しいと仮定しない」とします。この設定で実行されるのがウェルチのt検定 (Welch’s t-test)です。
- 今回のシナリオ: 介入群(新薬)と対照群(プラセボ)で、結果のばらつき(分散)が同じである保証はありません。新薬が一部の人にだけ劇的に効く場合など、分散が異なる可能性は常にあります。
# t検定の実施
t_test_result <- t.test(
formula = sleep_duration ~ group,
data = study_data,
alternative = "two.sided",
mu = 0,
var.equal = FALSE,
conf.level = 0.95
)
# 結果の表示
print(t_test_result)
Welch Two Sample t-test
data: sleep_duration by group
t = -6.0734, df = 96.239, p-value = 2.491e-08
alternative hypothesis: true difference in means between group Control and group Treatment is not equal to 0
95 percent confidence interval:
-48.56223 -24.63865
sample estimates:
mean in group Control mean in group Treatment
394.1468 430.7473 ステップ6: 結果の解釈と結論
- 結論: p値(2.491e-08)が研究デザインで定めた有意水準5%を下回っていますので、「2つのグループの平均睡眠時間に差はない」という仮説(帰無仮説)は棄却されます。つまり、観測された平均睡眠時間の差(約37分)は、偶然とは考えにくく、統計的に有意であると判断します。
【シミュレーション全体のまとめ】
このシミュレーションは、快眠製薬が行ったParallel studyの結果を模したものです。結果、新薬「ヨクネムール」を服用した介入群は、プラセボを服用した対照群に比べて、平均睡眠時間が統計的に有意に長いことが示されました。
したがって、快眠製薬は「新薬ヨクネムールは、軽度の睡眠障害を持つ成人の睡眠時間を延長する効果がある」という結論を導き、このデータを基に国への承認申請を進めることができるでしょう。
以上です。

