
Rで A/Bテスト:ベイズ的アプローチ を試みます。
A/Bテストのシナリオは以下の通りです。
背景
あなたは急成長中のガジェット系スタートアップで、新製品の予約販売ページを担当しています。エンジニアチームから「購入ボタンのデザインを、より大きく、目立つ色に変更すれば予約購入率(CVR)が上がるはずだ」という提案がありました。しかし、デザイナーは「現在のミニマルなデザインはブランドイメージに合っており、派手なボタンは逆効果かもしれない」と懸念しています。
市場投入のタイミングを逃したくないため、できるだけ早く、かつ合理的にどちらのデザインが良いかを決定する必要があります。そのため、十分な証拠が集まり次第、速やかにテストを終了させたいと考えています。
テストの目的
新しいデザインの購入ボタン(B案)が、既存のボタン(A案)よりも予約購入率を向上させるかを、ベイズ統計のアプローチを用いて逐次的に評価し、迅速な意思決定を行う。
テスト設計
- Aグループ(コントロール群): 既存の購入ボタン。
- 過去の類似キャンペーンから、このグループのCVRは 10% 程度だと予想されます。
- Bグループ(テスト群): 新しいデザインの購入ボタン。
- この変更により、CVRが 12% に向上することを期待しています。
- 事前知識(事前分布): 全く情報がないわけではなく、「CVRはだいたい10%前後だろう」という弱い信念があります。この知識をベータ分布 Beta(1, 9) としてモデルに組み込みます。この分布は平均が 1/(1+9) = 0.1 となり、我々の事前知識を表現しています。
意思決定ルール(ベイズ的アプローチ)
テストの最大継続期間は30日間とビジネス上決定し、毎日結果を監視して、以下のいずれかの条件が満たされた時点でテストを終了し、結論を出します。
- 【勝利条件】B案の優位性が確立された場合:
- B案のCVRがA案のCVRを上回る確率 P(CVR_B > CVR_A) が 95% を超えた場合。
- 判断: B案の勝利と判断し、B案を全面的に採用する。
- 【劣後条件】B案の劣位性が明確になった場合:
- A案のCVRがB案のCVRを上回る確率 P(CVR_A > CVR_B) が 95% を超えた場合(これは P(CVR_B > CVR_A) が5%を下回るのと同じ)。
- 判断: B案は効果がない、あるいは逆効果であると判断し、A案を維持する。
- 【タイムアウト】最大期間に達した場合:
- 30日間が経過しても、上記のいずれの条件も満たされなかった場合。
- 判断: 「30日間では、どちらかが優れていると95%の確信度で言うには十分な証拠が集まらなかった」と結論づける。その上で、30日時点での P(CVR_B > CVR_A) の値や期待損失を基に、総合的なビジネス判断(A案維持、リスクを取ってB案採用、など)を下す。例えば、確率が85%で期待損失が非常に小さければ、B案を採用する判断もあり得る。
このルールにより、無駄にテストを続けることなく、合理的かつ迅速な意思決定を目指します。
続いて A/Bテストに入ります。
ステップ1: 事前設定
# --- シナリオ設定 ---
# 「真の」CVR
# そもそも知り得ないパラメータ
# つまりB案勝利のシミュレーションであり、
# 「もしB案の真のCVRがA案より2パーセントポイント高かったとしたら、今回のテスト手法はそれを正しく検知できるか?」のシミュレーションになります。
true_cvr_A <- 0.10
true_cvr_B <- 0.12
# 事前分布 (Beta分布のパラメータ alpha, beta)
# 「CVRは10%くらいだろう」という弱い信念を表現 (平均 1/(1+9) = 0.1)
alpha_prior <- 1
beta_prior <- 9
# 1日あたりの訪問者数 (各グループ)
visitors_per_day <- 1500
# --- 意思決定ルール ---
# BがAを上回る確率の閾値
prob_threshold <- 0.95ステップ2: 逐次シミュレーション
seed <- 20250613
set.seed(seed)
# 毎日データを観測し、信念(事後分布)を更新していくプロセスをシミュレートします。
# 結果を記録するためのデータフレーム
results_log <- data.frame()
# 事後分布のパラメータを事前分布で初期化
alpha_A <- alpha_prior
beta_A <- beta_prior
alpha_B <- alpha_prior
beta_B <- beta_prior
cat("シミュレーション開始...\n")
# シミュレーションループ (最大30日間)
for (day in 1:30) {
# 今日のデータを生成 (二項分布に従う)
conversions_A_today <- rbinom(1, visitors_per_day, true_cvr_A)
conversions_B_today <- rbinom(1, visitors_per_day, true_cvr_B)
# 事後分布のパラメータを更新
# 事後分布 ∝ 尤度 × 事前分布
# Beta分布は二項分布の共役事前分布
# 事前分布 Beta(alpha_prior, beta_prior)
# 観測結果 n 回の試行のうち k 回成功
# 事後分布 Beta(alpha_prior + k, beta_prior + (n - k))
alpha_A <- alpha_A + conversions_A_today
beta_A <- beta_A + (visitors_per_day - conversions_A_today)
alpha_B <- alpha_B + conversions_B_today
beta_B <- beta_B + (visitors_per_day - conversions_B_today)
# --- 意思決定ルールの評価 ---
# モンテカルロシミュレーションで事後分布から大量にサンプリング
n_samples <- 100000
posterior_samples_A <- rbeta(n_samples, alpha_A, beta_A)
posterior_samples_B <- rbeta(n_samples, alpha_B, beta_B)
# BがAを上回る確率 P(CVR_B > CVR_A) を計算
prob_B_beats_A <- mean(posterior_samples_B > posterior_samples_A)
# 期待損失を計算 (Bを選んだ場合の間違った意思決定による損失)
loss_if_choose_B <- pmax(0, posterior_samples_A - posterior_samples_B)
expected_loss_B <- mean(loss_if_choose_B)
# ログに記録
current_log <- data.frame(
day = day,
prob_B_beats_A = prob_B_beats_A,
expected_loss_B = expected_loss_B
)
results_log <- rbind(results_log, current_log)
# 終了条件のチェック
if (prob_B_beats_A > prob_threshold) {
cat(paste0("テスト終了 (", day, "日目): \n"))
cat(paste0(" BがAを上回る確率: ", round(prob_B_beats_A, 3), " ( > 閾値 ", prob_threshold, ")\n"))
break
}
# 最終日まで終了しなかった場合
if (day == 30) {
cat("30日間テストを継続しましたが、明確な結論は出ませんでした。\n")
}
}シミュレーション開始...
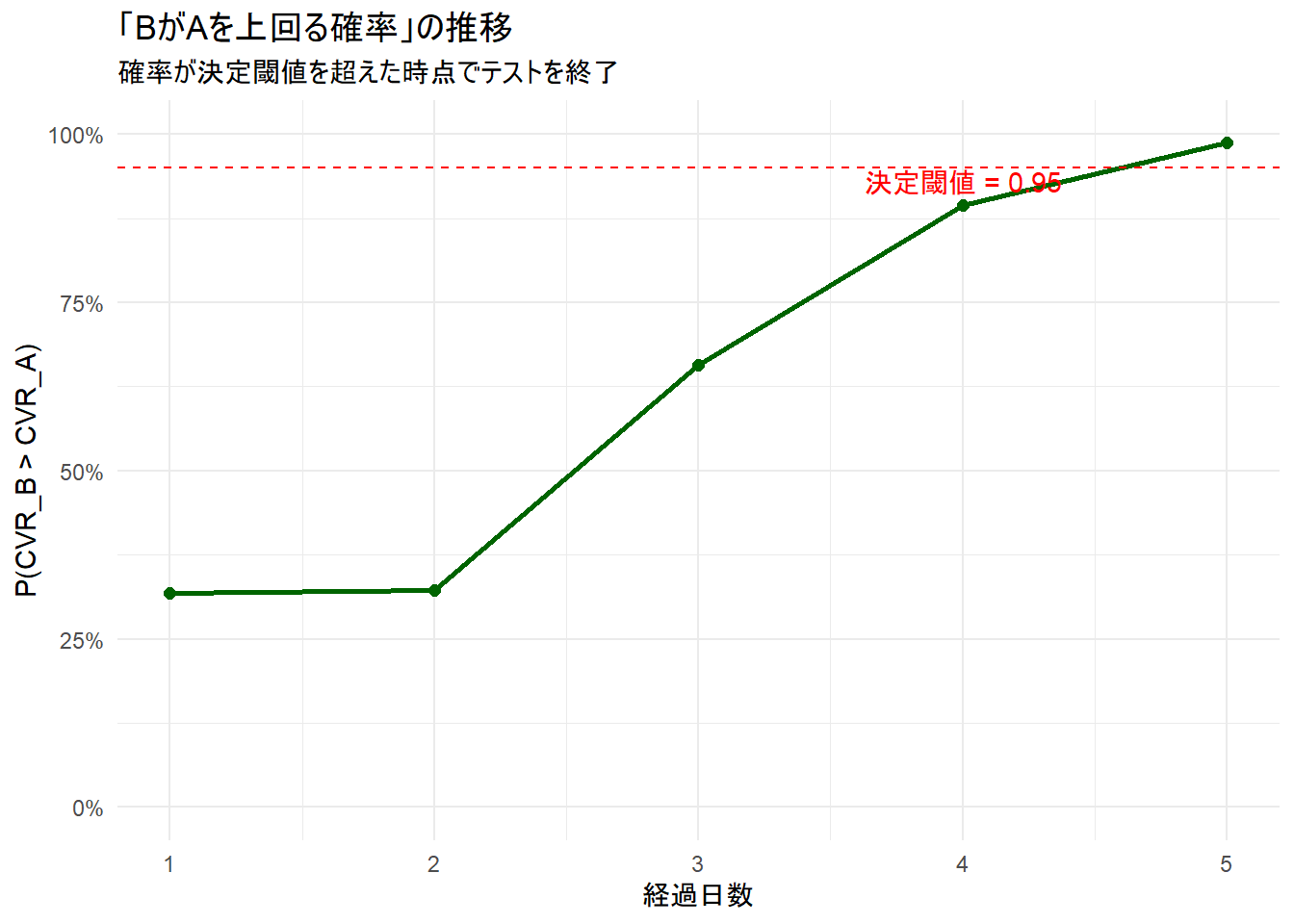
テスト終了 (5日目):
BがAを上回る確率: 0.988 ( > 閾値 0.95)ステップ3: 結果の可視化
library(ggplot2)
# 1. 最終日の事後分布をプロット
final_posterior_data <- data.frame(
value = c(posterior_samples_A, posterior_samples_B),
group = rep(c("A: 既存ボタン", "B: 新デザイン"), each = n_samples)
)
g1 <- ggplot(final_posterior_data, aes(x = value, fill = group)) +
geom_density(alpha = 0.7) +
scale_fill_manual(values = c("A: 既存ボタン" = "skyblue", "B: 新デザイン" = "salmon")) +
labs(
title = paste0("最終日 (", day, "日目) のCVR事後分布"),
subtitle = "各デザインのCVRがどの値を取りそうかの確率分布",
x = "コンバージョン率 (CVR)",
y = "確率密度",
fill = "グループ"
) +
theme_minimal() +
theme(legend.position = "bottom")
print(g1)
# 2. BがAを上回る確率の推移をプロット
g2 <- ggplot(results_log, aes(x = day, y = prob_B_beats_A)) +
geom_line(color = "darkgreen", linewidth = 1) +
geom_point(color = "darkgreen", size = 2) +
geom_hline(yintercept = prob_threshold, linetype = "dashed", color = "red") +
annotate("text",
x = max(results_log$day) * 0.8, y = prob_threshold - 0.02,
label = paste("決定閾値 =", prob_threshold), color = "red"
) +
scale_y_continuous(labels = scales::percent, limits = c(0, 1)) +
labs(
title = "「BがAを上回る確率」の推移",
subtitle = "確率が決定閾値を超えた時点でテストを終了",
x = "経過日数",
y = "P(CVR_B > CVR_A)"
) +
theme_minimal()
print(g2)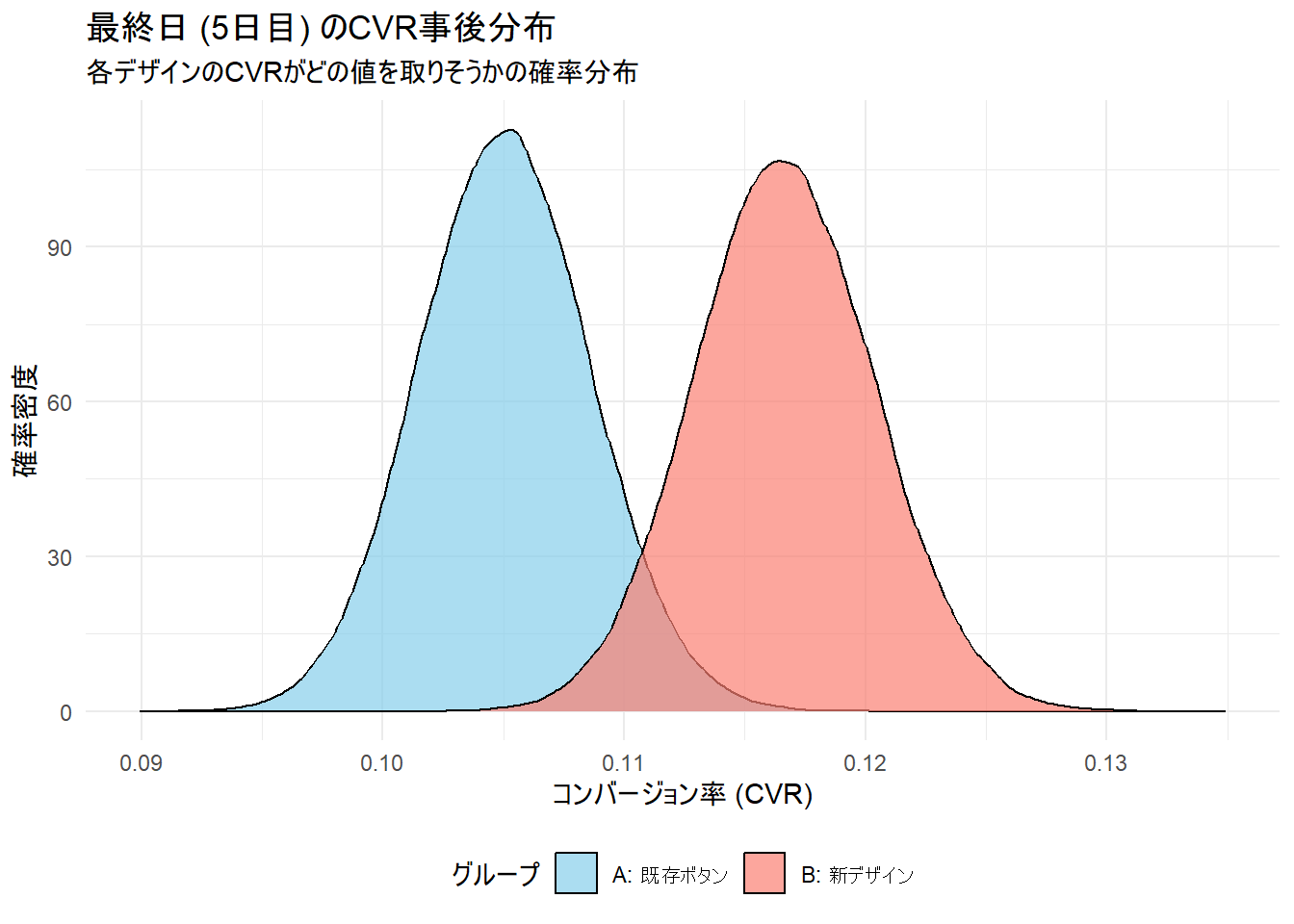
ステップ4: 結果の解釈と結論
cat("\n--- 最終的な結論 ---\n")
# 最終日のデータを取得
final_day_stats <- results_log[nrow(results_log), ]
total_visitors <- visitors_per_day * final_day_stats$day
# AとBの事後分布の要約統計量
summary_A <- quantile(posterior_samples_A, probs = c(0.025, 0.5, 0.975))
summary_B <- quantile(posterior_samples_B, probs = c(0.025, 0.5, 0.975))
cat(paste0("テストは ", day, " 日間で終了しました。\n"))
cat(paste0("総訪問者数は各グループ ", total_visitors, " 人です。\n\n"))
cat(paste0("新しいデザインBのCVRが既存のAを上回る確率は ", round(final_day_stats$prob_B_beats_A * 100, 1), "% です。\n"))
cat("これは我々が設定した95%の信頼度閾値を超えています。\n\n")
cat("A(既存)のCVRの95%信用区間:", paste0(round(summary_A[1] * 100, 1), "% ~ ", round(summary_A[3] * 100, 1), "% (中央値: ", round(summary_A[2] * 100, 1), "%)\n"))
cat("B(新規)のCVRの95%信用区間:", paste0(round(summary_B[1] * 100, 1), "% ~ ", round(summary_B[3] * 100, 1), "% (中央値: ", round(summary_B[2] * 100, 1), "%)\n\n"))
cat(paste0("B案を採用した場合の期待損失は ", round(final_day_stats$expected_loss_B * 100, 4), " パーセントポイントと非常に小さく、リスクは低いと判断できます。\n"))
cat("ビジネス判断: 新しいデザインのボタンBを全面的に採用することを強く推奨します。\n")
--- 最終的な結論 ---
テストは 5 日間で終了しました。
総訪問者数は各グループ 7500 人です。
新しいデザインBのCVRが既存のAを上回る確率は 98.8% です。
これは我々が設定した95%の信頼度閾値を超えています。
A(既存)のCVRの95%信用区間: 9.8% ~ 11.2% (中央値: 10.5%)
B(新規)のCVRの95%信用区間: 10.9% ~ 12.4% (中央値: 11.7%)
B案を採用した場合の期待損失は 0.0021 パーセントポイントと非常に小さく、リスクは低いと判断できます。
ビジネス判断: 新しいデザインのボタンBを全面的に採用することを強く推奨します。以上です。

