
RStan を利用して 状態空間モデル(ローカルレベルモデル+カルマンフィルタ、パラメーター未知、季節性データ) を試みます。
1. シナリオ設定:リゾート地における小規模ジェラート店の月間売上
シミュレーションの舞台として、ある海沿いのリゾート地にある小規模なジェラート店の月間売上(単位:万円)を考えます。
ストーリー: このジェラート店は、地元の新鮮なフルーツを使ったジェラートが人気で、オープンしてから10年が経ちました。この店の売上には、以下のような特徴があります。
季節性 (Seasonal Component): リゾート地のため、売上は夏(7月-8月)にピークを迎え、冬(12月-2月)に大きく落ち込みます。この季節による変動パターンは毎年繰り返されます。これはモデルの「季節性」の部分に相当します。
レベルの変動 (Local Level): 店の基本的な売上水準(レベル)は一定ではありません。
- 3年前に、近隣に大型のリゾートホテルが開業し、客足が伸びて売上のベースが上がりました。
- 5年前に、人気テレビ番組で紹介され、一時的に売上が急増しましたが、その後少し落ち着きました。
- 昨年、すぐ近くに競合となるスムージー店がオープンし、じわじわと売上のベースが下がっているように感じられます。
このように、店の基本的な人気度やブランド力、周辺環境の変化といった予測不能な要因によって、売上の「地力」とも言えるレベルが時間とともにランダムに変動します。これが「ローカルレベルモデル」で捉えるべき状態の推移であり、この変動の大きさがシステムノイズ (
sigma_w) に相当します。このシナリオでは、システムノイズはゼロに近くなく、ある程度の大きさを持つと想定されます。観測ノイズ (Observation Noise): その月の天候不順(長雨など)や、短期的なイベントの有無、あるいは単なる偶然によって、月ごとの売上は、基本的なレベルと季節性を足し合わせたものからさらにばらつきます。これが観測ノイズ (
sigma_v) です。
2. サンプルデータの生成
上記のシナリオに基づいて、Rで10年分(120ヶ月)の月間売上データを生成します。
# シミュレーションの条件設定
seed <- 20250628
set.seed(seed)
T <- 120 # データ期間 (10年 * 12ヶ月)
S <- 12 # 季節周期 (12ヶ月)
# 真のパラメータ
mu <- numeric(T)
season <- numeric(T)
y <- numeric(T)
# ノイズの標準偏差
sigma_w_true <- 15 # システムノイズ(レベル): 競合やメディア露出などによる変動
sigma_s_true <- 5 # システムノイズ(季節): 季節パターンの微小な変動
sigma_v_true <- 50 # 観測ノイズ: 天候などによるランダムな変動
# 初期値
mu[1] <- 300 # 初期の売上レベル
# 初期の季節効果(合計が0になるようにsin波で作成)
initial_season <- 150 * sin(2 * pi * (1:S) / S)
initial_season <- initial_season - mean(initial_season)
season[1:S] <- initial_season
# 時系列データの生成
for (t in 2:T) {
# レベルの更新
mu[t] <- mu[t - 1] + rnorm(1, mean = 0, sd = sigma_w_true)
# 季節効果の更新 (t > S の場合)
if (t > S) {
# 過去(S-1)個の季節効果の合計にマイナスをつけたものが期待値
expected_season <- -sum(season[(t - S + 1):(t - 1)])
season[t] <- expected_season + rnorm(1, mean = 0, sd = sigma_s_true)
}
}
# 観測データの生成
y <- mu + season + rnorm(T, mean = 0, sd = sigma_v_true)
# 負の売上は不自然なので0にクリップ
y[y < 0] <- 0
# 生成したデータの可視化
sim_data <- data.frame(
time = 1:T,
y = y,
true_level = mu,
true_season = season
)
library(ggplot2)
ggplot(sim_data, aes(x = time)) +
geom_line(aes(y = true_level, color = "真のレベル (μ)")) +
geom_line(aes(y = y, color = "観測売上 (y)")) +
labs(
title = "シミュレーションデータ:ジェラート店の月間売上",
x = "月",
y = "売上 (万円)",
color = "データ"
) +
theme_bw()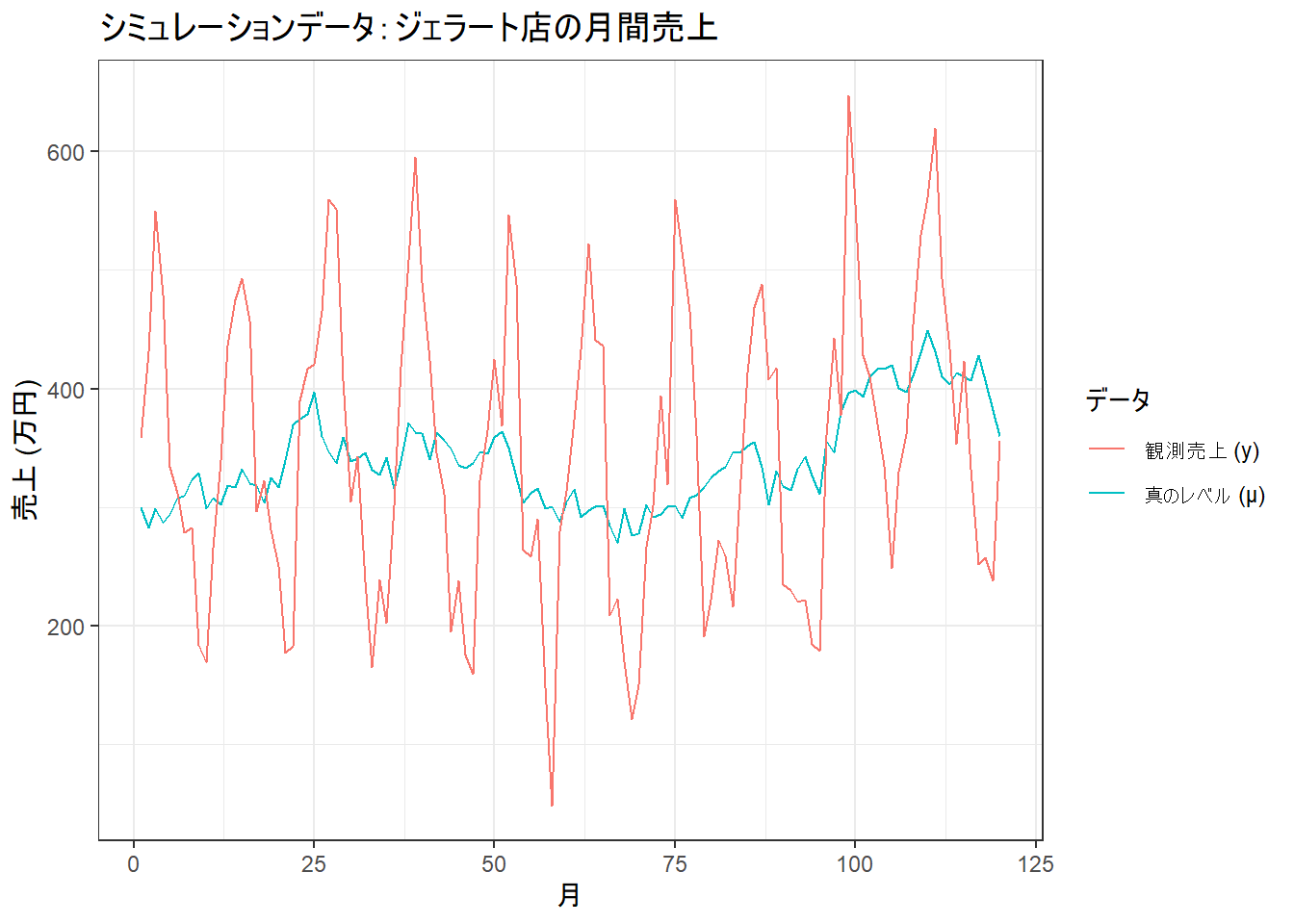
生成されたデータを見ると、明確な季節変動とともに、データの中心となる「レベル」が時間とともに緩やかに上下していることが確認できます。これがモデルで推定したい対象です。
3. Stanモデリング
次に、このデータを分析するための状態空間モデルをStanで記述します。モデルはローカルレベルと季節性の要素を両方含みます。
モデルの数式表現:
- 観測方程式: \(y_t \sim \text{Normal}(\mu_t + \text{season}_t, \sigma_v)\)
- 状態方程式(レベル): \(\mu_t \sim \text{Normal}(\mu_{t-1}, \sigma_w)\)
- 状態方程式(季節): \(\text{season}_t \sim \text{Normal}(-\sum_{j=1}^{S-1} \text{season}_{t-j}, \sigma_s)\)
ここで、\(t\)は時点、\(\mu_t\)はレベル、\(\text{season}_t\)は季節効果、\(\sigma_v, \sigma_w, \sigma_s\)はそれぞれ観測ノイズ、レベルのシステムノイズ、季節性のシステムノイズの標準偏差です。
Stanコード
- パラメータ未知:
s_w,s_v,s_sなどをparametersブロックで定義。 - ドメイン知識の活用:
- システムノイズ (
s_w) の範囲設定: ジェラート店の売上レベルの変動は、全くのゼロ(s_w=0)ではなく、かといって毎月50万円以上も変動するような無秩序なものでもない、というドメイン知識を反映し、parametersブロックでreal<lower=0.1, upper=50> s_w;と範囲を設定します。 - 事前分布: 上記の範囲を考慮し、
s_wの事前分布をnormal(10, 20)としています。これにより、10万円前後の変動を想定しつつも、広い範囲を探索できます。他のパラメータにも同様に情報を持つ事前分布を設定します。 - 初期値:
mu[1]の事前分布は、最初の観測値y[1]を中心に設定します。
- システムノイズ (
- 季節性の処理: 周期
Sの季節性をsum-to-zero制約の形でモデル化しています。
model_code <- "
data {
int<lower=1> T; // 時系列の長さ
vector[T] y; // 観測データ
int<lower=1> S; // 季節周期
real mean_y; // 観測データの平均値
}
parameters {
// --- 非中心化パラメータ化のためのノイズ項 ---
// これらは標準正規分布からサンプリングされる
vector[T-1] mu_raw; // レベルの変動ノイズ
vector[T-S] season_raw; // 季節性の変動ノイズ
// --- 初期値 ---
real mu_init; // レベルの初期値
vector[S-1] season_init_raw; // 最初の(S-1)個の季節効果
// --- ノイズの標準偏差 ---
real<lower=0.1, upper=50> s_w; // システムノイズSD (レベル)
real<lower=0, upper=30> s_s; // システムノイズSD (季節)
real<lower=1, upper=200> s_v; // 観測ノイズSD
}
transformed parameters {
vector[T] mu;
vector[T] season;
// --- 状態変数の構築 ---
// 1. レベル (mu) の構築
mu[1] = mu_init;
// 非中心化:ノイズ項に標準偏差を掛けて累積和を計算
for (t in 2:T) {
mu[t] = mu[t-1] + mu_raw[t-1] * s_w;
}
// 2. 季節性 (season) の構築
// 2.1 初期値(1~S)の構築
season[1:(S-1)] = season_init_raw;
// 2.2 識別性のためのハード制約: S番目は合計が0になるように決定
season[S] = -sum(season_init_raw);
// 2.3 状態遷移(S+1~T)
for (t in (S+1):T) {
// 非中心化:期待値に、ノイズ項 * 標準偏差を加える
season[t] = -sum(season[(t-S+1):(t-1)]) + season_raw[t-S] * s_s;
}
}
model {
// --- 事前分布 ---
// 1. 非中心化パラメータ(ノイズ項)
mu_raw ~ std_normal(); // normal(0, 1)と同じ
season_raw ~ std_normal();
// 2. 初期値
// レベルの初期値は、全データの平均あたりと仮定
mu_init ~ normal(mean_y, 100);
// 季節効果の初期値
season_init_raw ~ normal(0, 50);
// 3. ノイズの標準偏差
s_w ~ normal(10, 20);
s_s ~ normal(5, 10);
s_v ~ normal(50, 50);
// --- 観測方程式 ---
// 尤度計算
y ~ normal(mu + season, s_v);
}
generated quantities {
vector[T] y_pred;
for (t in 1:T) {
y_pred[t] = normal_rng(mu[t] + season[t], s_v);
}
}
"4. RStanによるシミュレーション実行と結果解釈
最後に、RからStanを呼び出してMCMCシミュレーションを実行し、結果を分析・可視化します。
# RStanの読み込み
library(rstan)
stan_output <- "D:/stan_output"
# Stanの並列計算設定
rstan_options(auto_write = TRUE)
options(mc.cores = parallel::detectCores())
sapply(X = c("rstan"), packageVersion)$rstan
[1] 2 32 7# Stanに渡すデータ
stan_data <- list(
T = T,
y = y,
S = S,
mean_y = mean(y) # 全データの平均を渡す
)
# Stanモデルの実行
fit <- stan(
model_code = model_code,
data = stan_data,
iter = 6000,
warmup = 3000,
chains = 4,
seed = seed,
thin = 1
)
# stanfit オブジェクトの保存
setwd(stan_output)
saveRDS(object = fit, file = "stan_fit.rds")# stanfit オブジェクトの読み込み
setwd(stan_output)
fit <- readRDS("stan_fit.rds")
# --- 結果の確認 ---
# 収束診断
print(fit, pars = c("s_w", "s_v", "s_s", "lp__"), digits_summary = 3)
# トレースプロットで収束を確認
rstan::traceplot(fit, pars = c("s_w", "s_v", "s_s"))Inference for Stan model: anon_model.
4 chains, each with iter=6000; warmup=3000; thin=1;
post-warmup draws per chain=3000, total post-warmup draws=12000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff
s_w 13.280 0.088 4.173 6.203 10.135 12.916 16.054 22.325 2255
s_v 51.378 0.067 4.456 43.146 48.287 51.165 54.272 60.745 4385
s_s 4.763 0.073 3.371 0.208 2.095 4.216 6.854 12.647 2140
lp__ -660.428 0.249 12.823 -686.255 -668.923 -660.181 -651.607 -635.848 2650
Rhat
s_w 1.002
s_v 1.000
s_s 1.001
lp__ 1.003
Samples were drawn using NUTS(diag_e) at Sat Jun 28 17:57:45 2025.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).
stan実行の結果、以下の警告メッセージがでます。
警告メッセージ:
1: There were 280 divergent transitions after warmup. See

 mc-stan.org
to find out why this is a problem and how to eliminate them.
2: Examine the pairs() plot to diagnose sampling problems
mc-stan.org
to find out why this is a problem and how to eliminate them.
2: Examine the pairs() plot to diagnose sampling problemsさらに、トレースプロット(Figure 2)も きれいな結果 ではありませんが、 推定結果(平均値)は sigma_w_true = 15 に対して、s_w は 13.280、sigma_s_true = 5 に対して s_sは 4.763、sigma_v_true = 50 に対して s_v は 51.378 であり、いずれの真値も 95%信用区間に収まっており、かつ Rhat は 1.00x との結果ですので、ここは割り切って このまま進めてしまいます。
# --- 結果の可視化 ---
# MCMCサンプルの抽出
samples <- rstan::extract(fit)
# プロット用のデータフレームを作成
# シミュレーションデータ(sim_data)と推定結果を結合する
library(dplyr)
result_df <- sim_data %>%
# 推定されたレベルの中央値と信用区間を追加
mutate(
mu_median = apply(samples$mu, 2, median),
mu_lower = apply(samples$mu, 2, quantile, probs = 0.025),
mu_upper = apply(samples$mu, 2, quantile, probs = 0.975),
# 推定された季節性の中央値と信用区間を追加
season_median = apply(samples$season, 2, median),
season_lower = apply(samples$season, 2, quantile, probs = 0.025),
season_upper = apply(samples$season, 2, quantile, probs = 0.975)
)
# レベル成分をプロット
ggplot(result_df, aes(x = time)) +
# 推定されたレベルの95%信用区間をリボンで表示
geom_ribbon(aes(ymin = mu_lower, ymax = mu_upper, fill = "推定値の95%信用区間"), alpha = 0.3) +
# 推定されたレベルの中央値を線で表示
geom_line(aes(y = mu_median, color = "推定されたレベル (中央値)")) +
# 真のレベルを破線で表示
geom_line(aes(y = true_level, color = "真のレベル")) +
# ラベルとタイトルの設定
labs(
title = "推定されたレベル成分と真の値の比較",
x = "月 (Time)",
y = "レベル (Level)",
color = "系列",
fill = ""
) +
# 色と凡例の設定
scale_color_manual(
name = "系列",
values = c("推定されたレベル (中央値)" = "darkorange", "真のレベル" = "black")
) +
scale_fill_manual(
name = "",
values = c("推定値の95%信用区間" = "darkorange")
) +
# テーマの設定
theme_bw() +
theme(legend.position = "bottom")
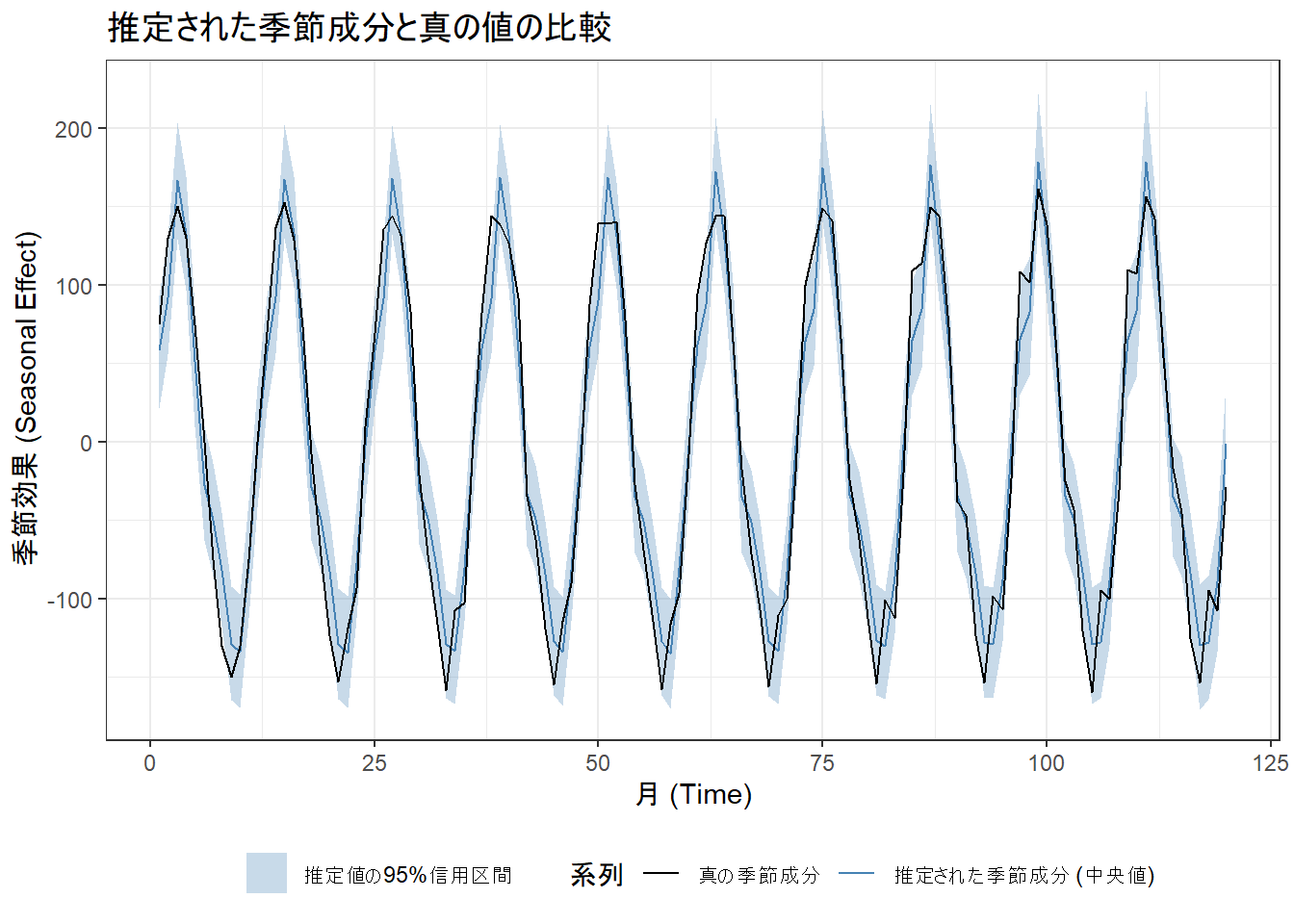
# 季節成分をプロット
ggplot(result_df, aes(x = time)) +
# 推定された季節成分の95%信用区間をリボンで表示
geom_ribbon(aes(ymin = season_lower, ymax = season_upper, fill = "推定値の95%信用区間"), alpha = 0.3) +
# 推定された季節成分の中央値を線で表示
geom_line(aes(y = season_median, color = "推定された季節成分 (中央値)")) +
# 真の季節成分を破線で表示
geom_line(aes(y = true_season, color = "真の季節成分")) +
# ラベルとタイトルの設定
labs(
title = "推定された季節成分と真の値の比較",
x = "月 (Time)",
y = "季節効果 (Seasonal Effect)",
color = "系列",
fill = ""
) +
# 色と凡例の設定
scale_color_manual(
name = "系列",
values = c("推定された季節成分 (中央値)" = "steelblue", "真の季節成分" = "black")
) +
scale_fill_manual(
name = "",
values = c("推定値の95%信用区間" = "steelblue")
) +
# テーマの設定
theme_bw() +
theme(legend.position = "bottom")
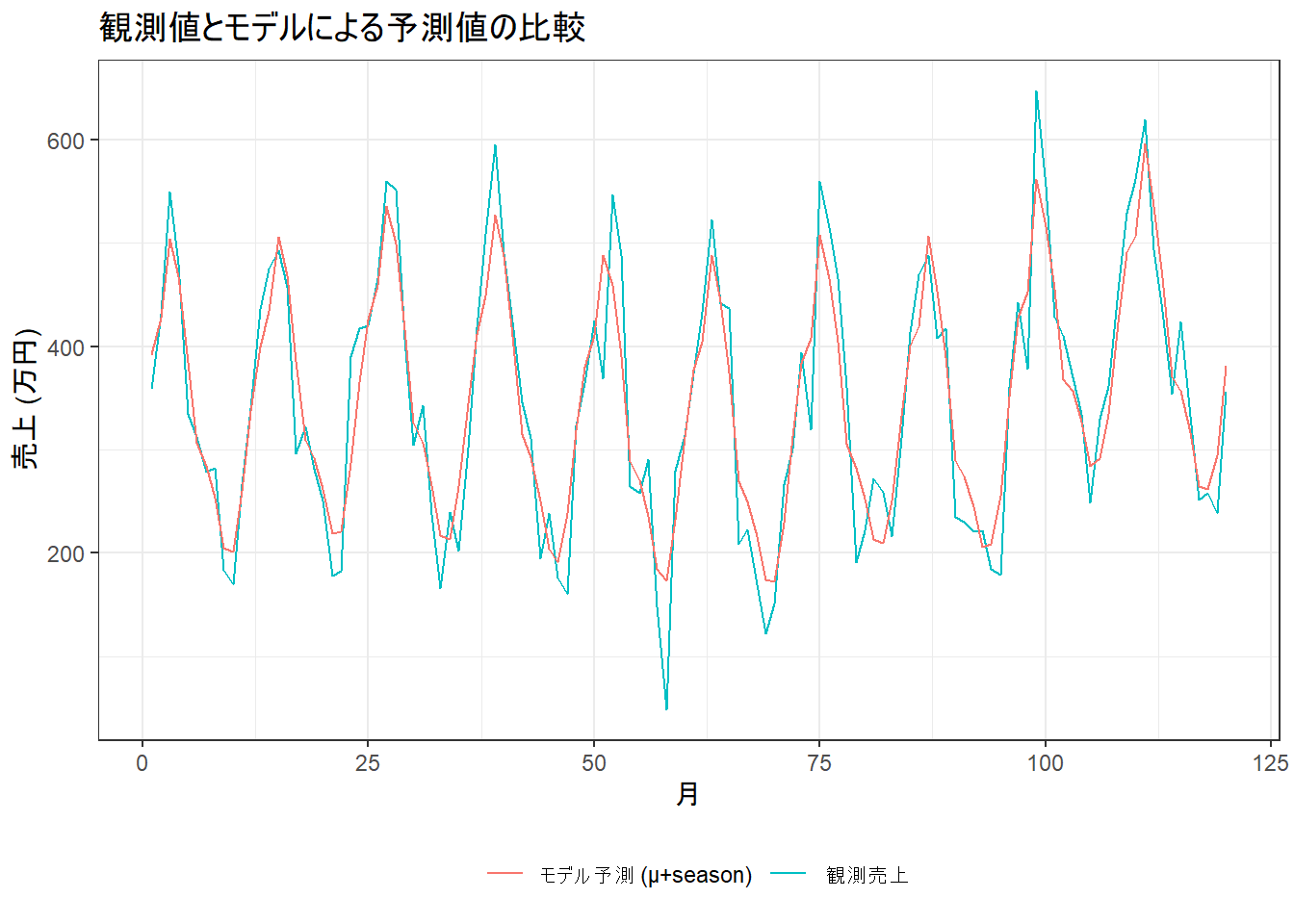
# 観測値と推定されたレベル+季節性のプロット
ggplot(result_df, aes(x = time)) +
geom_line(aes(y = y, color = "観測売上")) +
geom_line(aes(y = mu_median + season_median, color = "モデル予測 (μ+season)")) +
labs(
title = "観測値とモデルによる予測値の比較",
x = "月", y = "売上 (万円)", color = ""
) +
theme_bw() +
theme(legend.position = "bottom")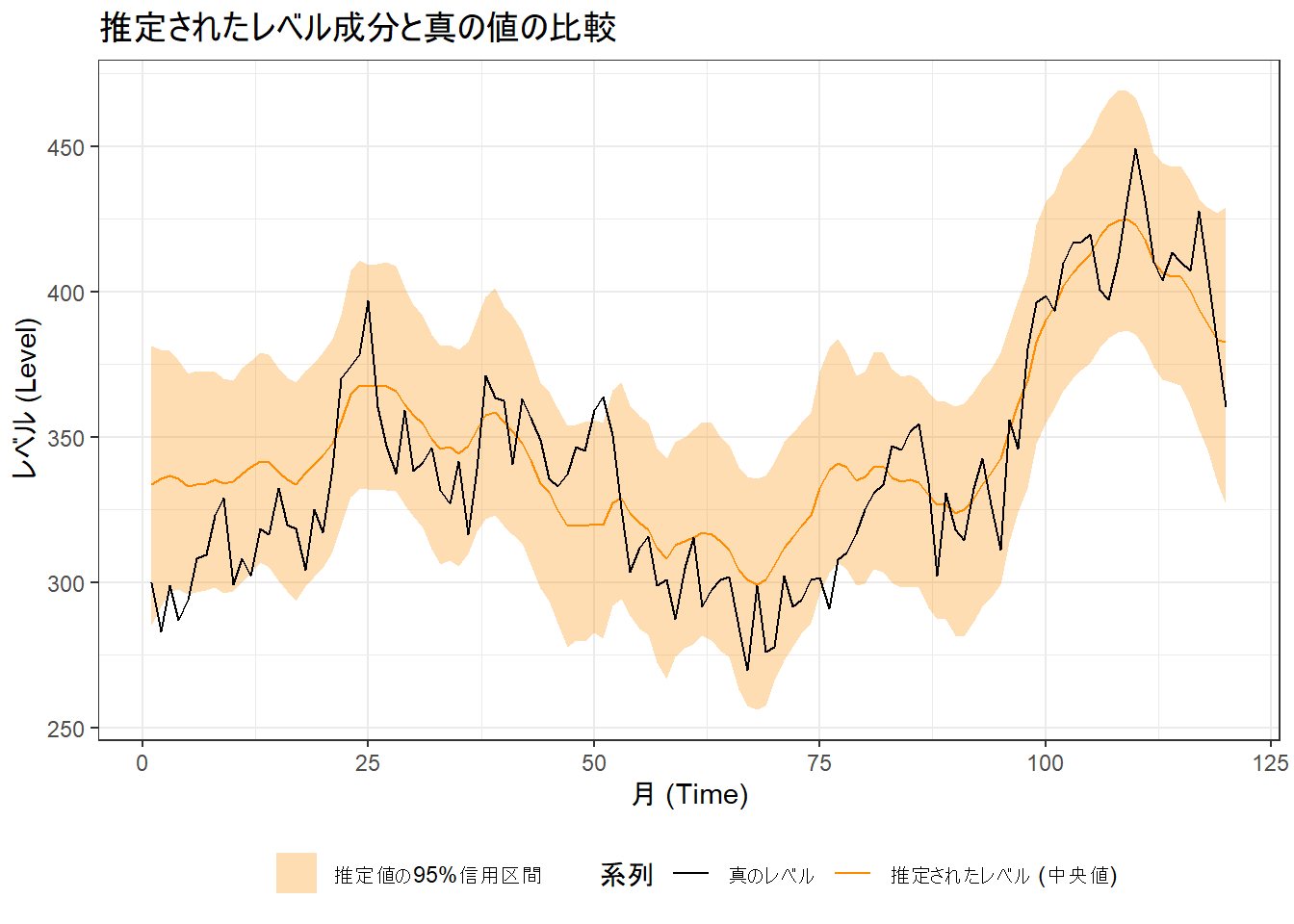
- 水準(レベル)の推定: 「推定されたレベル成分と真の値の比較」(Figure 3)を見ますと、95%信用区間(橙色の帯)が真の値を ほぼ カバーしています。
- 季節効果の推定: 「推定された季節成分と真の値の比較」(Figure 4)を見ますと、95%信用区間(青色の帯)は真の12か月の季節パターンを ほぼ カバーしています。
- モデルの当てはまり: 「観測値とモデルによる予測値の比較」(Figure 5) は、観測値とモデルが予測する「水準+季節性」を比較したものです。モデルによる適合値が観測値の動きに ほぼ追従 できていることが確認できます。
以上です。

