
RStan を利用して 状態空間モデル(ローカルレベルモデル+カルマンフィルタ、パラメーター未知) を試みます。
1. ストーリーとシナリオ設定
シナリオ:山間部の河川における日間平均水位の観測
- 背景: ある山間部の河川に、水位を自動で24時間測定し、その平均値を毎日記録するセンサーが設置されています。この地域の天候は変わりやすく、予測困難なゲリラ豪雨が時折発生します。また、上流には農業用の小さな取水堰があり、地域住民によって不定期に操作されます。
- 観測されるデータ (
y_t): センサーによって記録された「日間平均水位」。このセンサーには、波による細かな揺れや、機器自体の電子的なノイズが含まれており、完全に正確な値ではありません(観測ノイズv_t)。 - 直接観測できない真の状態 (
μ_t): その日の「真の平均水位」。この真の水位は、前日の水位を基準としつつも、ゲリラ豪雨による急な増水や、取水堰の操作による水位の低下など、予測できない日々の要因によってランダムに変動します。この日々の変動がシステムノイズw_tに相当します。 - モデル構築に際して:
- ローカルレベルモデルに合致: 真の水位(
μ_t)が前日の水位(μ_{t-1})にランダムな変動(w_t)を加えたものとして振る舞い(ランダムウォーク)、観測値(y_t)は真の水位に観測誤差(v_t)が加わったもの、という構造がローカルレベルモデルに適合します。 - システムノイズは0に近くない: ゲリラ豪雨や堰の操作は、水位の「基本レベル」を日々変化させるため、システムノイズ
σ_wは決して0にはなりません。 - ドメイン知識の活用: 水位の日々の変動幅(システムノイズ)や観測機器の誤差(観測ノイズ)には、常識的な範囲が存在します。「1日で水位が10メートルも変動する」や「観測誤差が±5メートル」といったことは考えにくいため、これらの知見をモデルの事前分布に組み込みます。
- ローカルレベルモデルに合致: 真の水位(
2. カルマンフィルタについて
カルマンフィルタは、ノイズを含む観測値から、直接観測できない内部の状態を効率的に推定するためのアルゴリズムです。状態空間モデルにおける尤度計算や状態推定に広く用いられます。
アルゴリズムは、以下の2つのステップを時系列データに沿って逐次的に繰り返すことで構成されます。
- 予測 (Prediction) ステップ:
- 目的:1期前の状態推定値を用いて、現在の状態を予測する。
- 処理:「昨日の真の水位はこれくらいだったから、今日の真の水位はこのあたりだろう」と予測します。このとき、システムノイズの分だけ、予測の不確実性(誤差共分散)は増大します。
- フィルタリング (Filtering / Update) ステップ:
- 目的:現在の観測値を使って、予測した状態をより確からしい値に修正(更新)する。
- 処理:「予測した水位と、実際にセンサーが観測した水位を比較する。その差(予測誤差)が大きければ、予測を大幅に修正し、小さければ少しだけ修正する」という考え方で、状態の推定値を更新します。この更新により、観測値という新しい情報を得たため、推定の不確実性は減少します。
この「予測→更新」のサイクルを繰り返すことで、データが一つずつ入ってくるたびに、状態の最も確からしい推定値とその不確実性をリアルタイムで更新し続けることができます。Stanでは、このカルマンフィルタの計算過程をモデルに組み込むことで、複雑な時系列モデルの尤度を計算し、ベイズ推定を実行することが可能になります。
3. RとRStanによるシミュレーション実装
3.1. 準備とデータ生成
まず、必要なライブラリをロードし、上記のシナリオに沿った人工データを生成します。
library(rstan)
sapply(X = c("rstan"), packageVersion)
stan_output <- "D:/stan_output"
# Stanの並列計算設定
rstan_options(auto_write = TRUE)
options(mc.cores = parallel::detectCores())
seed <- 20250628$rstan
[1] 2 32 7# データの生成
set.seed(seed)
T <- 150 # 観測期間 (日数)
mu_zero <- 5.0 # 初期水位 (メートル)
# パラメータの真の値 (未知として推定する対象)
sigma_w_true <- 0.2 # システムノイズの標準偏差 (日々の水位変動の大きさ)
sigma_v_true <- 0.4 # 観測ノイズの標準偏差 (センサーの測定誤差)
# 状態(mu)と観測値(y)を生成
mu_true <- numeric(T)
y <- numeric(T)
# t=1 の状態
w <- rnorm(1, mean = 0, sd = sigma_w_true)
mu_true[1] <- mu_zero + w
v <- rnorm(1, mean = 0, sd = sigma_v_true)
y[1] <- mu_true[1] + v
# t=2以降の状態
for (t in 2:T) {
w <- rnorm(1, mean = 0, sd = sigma_w_true)
mu_true[t] <- mu_true[t - 1] + w
v <- rnorm(1, mean = 0, sd = sigma_v_true)
y[t] <- mu_true[t] + v
}
# 生成したデータの可視化
true_data <- tibble::tibble(
time = 1:T,
mu_true = mu_true,
y = y
)
library(ggplot2)
ggplot(true_data, aes(x = time)) +
geom_line(aes(y = mu_true, color = "真の水位 (μ_t)"), linewidth = 1) +
geom_point(aes(y = y, color = "観測値 (y_t)"), alpha = 0.7) +
labs(
title = "シミュレーションデータ",
subtitle = "真の水位と観測値の推移",
x = "日数", y = "水位 (m)", color = "データ系列"
) +
scale_color_manual(values = c("真の水位 (μ_t)" = "dodgerblue", "観測値 (y_t)" = "black")) +
theme_bw() +
theme(legend.position = "bottom")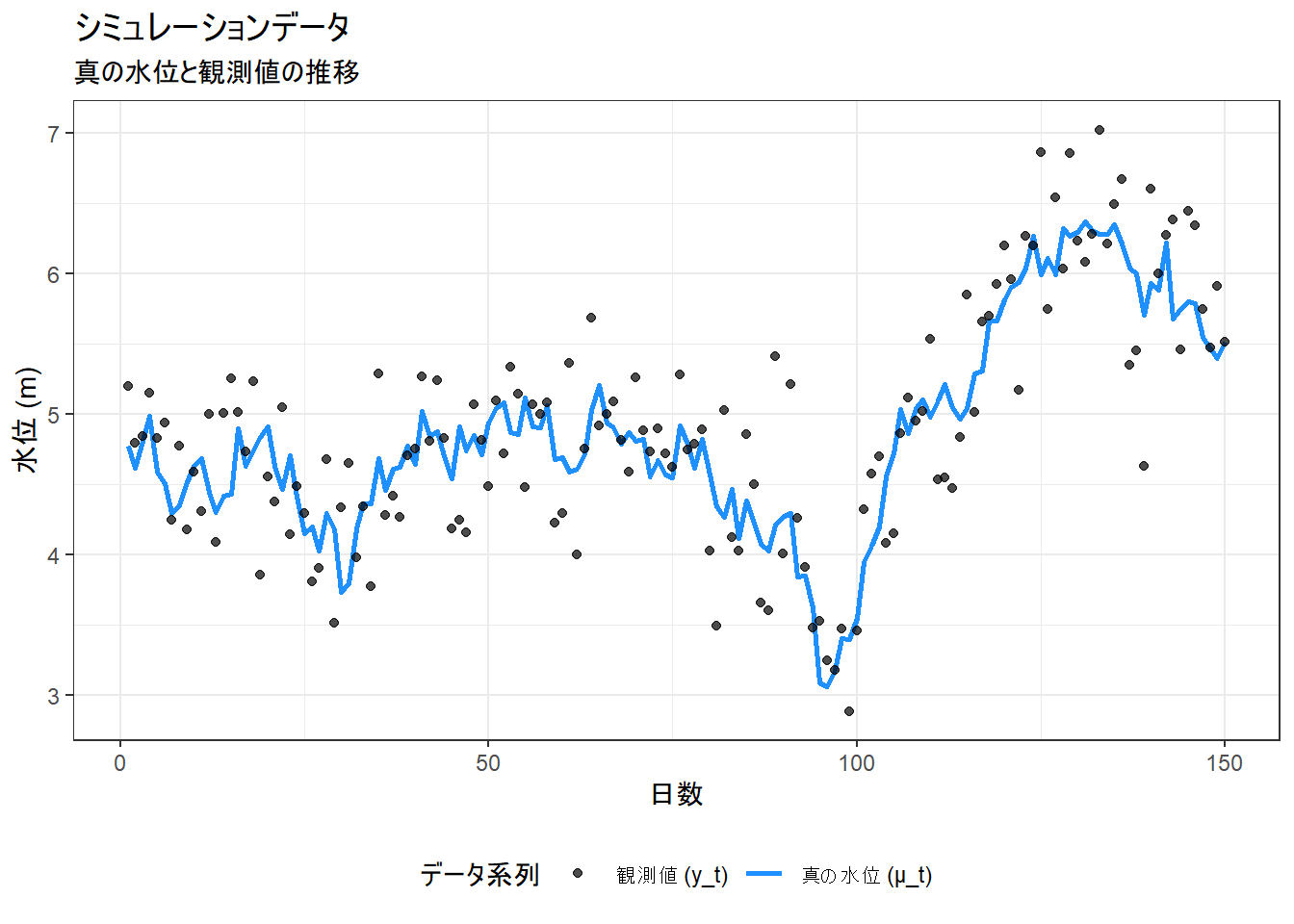
3.2. Stanコード (ローカルレベルモデル + カルマンフィルタ)
【コードのポイント】
-
parametersブロック:-
sigma_wにドメイン知識として下限0.01(1cm)、上限0.5(50cm)を設定します。これは「水位の変動が1日に1cm未満や50cmを超えることは稀である」という知見を反映しています。
-
-
transformed parametersブロック:- カルマンフィルタの「予測」と「フィルタリング(更新)」の計算をここで行います。
- 計算された各時点の対数尤度を
log_likベクトルに保存します。
-
modelブロック:-
log_likの合計をtargetに加算して、モデル全体の尤度を計算します。 - 各パラメータに事前分布を設定します。
-
sigma_wの事前分布にはnormal(0.1, 0.2)を指定しています。これは0.01から0.5の範囲内で、比較的小さな変動(10cm程度)が起こりやすいだろう、というドメイン知識を反映したものです。Stanは宣言された上限・下限に基づき、自動的に切断正規分布として扱います。 -
mu_zero(初期状態)の事前分布は、最初の観測値y[1]に近いはずだという知識を入れています。
-
-
model_code <- "
data {
int<lower=1> T; // 時系列の長さ
vector[T] y; // 観測値ベクトル
}
parameters {
real mu_zero; // 初期状態 (t=0)
real<lower=0> sigma_v; // 観測ノイズの標準偏差
real<lower=0.01, upper=0.5> sigma_w; // システムノイズの標準偏差 (ドメイン知識)
}
transformed parameters {
// カルマンフィルタの計算用変数
vector[T] mu_pred; // 状態の一期先予測
vector[T] P_pred; // 一期先予測の誤差の分散
vector[T] mu_filt; // フィルタリング後の状態
vector[T] P_filt; // フィルタリング後の誤差の分散
vector[T] K; // カルマンゲイン
vector[T] log_lik; // 各時点の対数尤度
// 初期値 (t=1)
mu_pred[1] = mu_zero;
P_pred[1] = 10; // 初期分散は大きめに設定 (無情報)
// t=1 のフィルタリングと尤度計算
K[1] = P_pred[1] / (P_pred[1] + sigma_v^2);
mu_filt[1] = mu_pred[1] + K[1] * (y[1] - mu_pred[1]);
P_filt[1] = (1 - K[1]) * P_pred[1];
log_lik[1] = normal_lpdf(y[1] | mu_pred[1], sqrt(P_pred[1] + sigma_v^2));
// t=2 から T までのループ
for (t in 2:T) {
// 予測ステップ
mu_pred[t] = mu_filt[t-1];
P_pred[t] = P_filt[t-1] + sigma_w^2;
// フィルタリング(更新)ステップ
K[t] = P_pred[t] / (P_pred[t] + sigma_v^2);
mu_filt[t] = mu_pred[t] + K[t] * (y[t] - mu_pred[t]);
P_filt[t] = (1 - K[t]) * P_pred[t];
// 尤度計算
log_lik[t] = normal_lpdf(y[t] | mu_pred[t], sqrt(P_pred[t] + sigma_v^2));
}
}
model {
// 事前分布 (ドメイン知識を反映)
mu_zero ~ normal(y[1], 2.0); // 初期状態は最初の観測値の近傍
sigma_v ~ normal(0, 1.0); // 観測ノイズは0に近いがある程度ばらつく
sigma_w ~ normal(0.1, 0.2); // システムノイズは0.1(10cm)あたりが中心と想定
// 対数尤度をターゲットに加算
target += sum(log_lik);
}
"3.3. Stanの実行と結果の分析
作成したStanコードを実行し、結果を可視化します。
# Stanに渡すデータリスト
stan_data <- list(T = T, y = y)
# Stanモデルのコンパイルと実行
fit <- stan(
model_code = model_code,
data = stan_data,
iter = 4000,
warmup = 2000,
chains = 4,
seed = seed
)
# stanfit オブジェクトの保存
setwd(stan_output)
saveRDS(object = fit, file = "stan_fit.rds")# stanfit オブジェクトの読み込み
setwd(stan_output)
fit <- readRDS("stan_fit.rds")
# 収束診断 (Rhatが1.1未満であれば概ね良好)
print(fit, pars = c("mu_zero", "sigma_v", "sigma_w"))
# MCMCサンプルを抽出
samples <- rstan::extract(fit)
# パラメータの事後分布をプロット
p1 <- ggplot(tibble::tibble(sigma_v = samples$sigma_v), aes(x = sigma_v)) +
geom_density(fill = "skyblue", alpha = 0.7) +
geom_vline(xintercept = sigma_v_true, color = "red", linetype = "dashed", linewidth = 1) +
labs(
title = "観測ノイズ (sigma_v) の事後分布",
subtitle = paste0("真値 = ", sigma_v_true), x = "sigma_v"
) +
theme_bw()
p2 <- ggplot(tibble::tibble(sigma_w = samples$sigma_w), aes(x = sigma_w)) +
geom_density(fill = "lightgreen", alpha = 0.7) +
geom_vline(xintercept = sigma_w_true, color = "red", linetype = "dashed", linewidth = 1) +
labs(
title = "システムノイズ (sigma_w) の事後分布",
subtitle = paste0("真値 = ", sigma_w_true), x = "sigma_w"
) +
theme_bw()
# パラメータのプロットを並べて表示(Figure 2)
library(patchwork)
p1 + p2
# トレースプロットを表示(Figure 3)
bayesplot::mcmc_trace(fit, pars = c("sigma_v", "sigma_w"))Inference for Stan model: anon_model.
4 chains, each with iter=4000; warmup=2000; thin=1;
post-warmup draws per chain=2000, total post-warmup draws=8000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
mu_zero 5.10 0.02 1.69 1.74 3.95 5.11 6.24 8.38 6776 1
sigma_v 0.44 0.00 0.03 0.37 0.41 0.44 0.46 0.50 6197 1
sigma_w 0.18 0.00 0.03 0.12 0.16 0.18 0.20 0.26 6282 1
Samples were drawn using NUTS(diag_e) at Sat Jun 28 06:53:20 2025.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).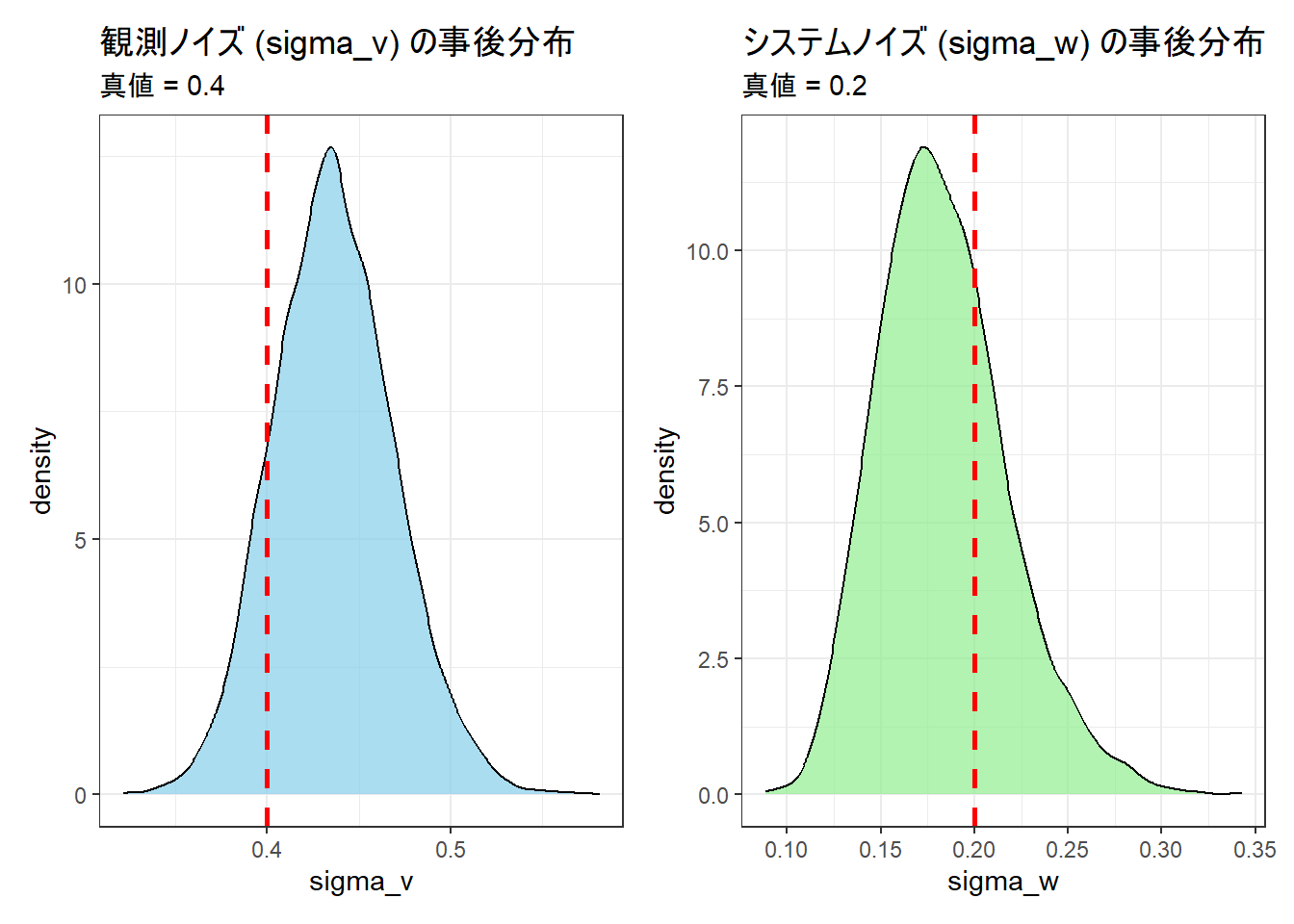
実行結果(パラメータ推定)
Figure 2 の事後分布のヒストグラムを確認しますと、sigma_v も sigma_w も 真値とピークにズレが生じていますが、sigma_v と sigma_w の Rhat はいずれも1.00、かつ、それぞれの95%信用区間内に sigma_v(真値: 0.4)もsigma_w(真値: 0.2)も含まれていますので、本シミュレーションではこのまま先に進みます。
3.4. 状態推定結果の可視化
最後に、推定された状態 mu_filt の推移をプロットし、真の値や観測値と比較します。
library(dplyr)
# 推定された状態(mu_filt)の要約統計量を取得
mu_summary <- summary(fit, pars = "mu_filt")$summary %>%
as_tibble() %>%
mutate(time = 1:T)
# 可視化
ggplot(true_data, aes(x = time)) +
# 95%信用区間
geom_ribbon(data = mu_summary, aes(ymin = `2.5%`, ymax = `97.5%`), fill = "skyblue", alpha = 0.8) +
# 真の水位
geom_line(aes(y = mu_true, color = "真の水位 (μ_t)"), linewidth = 1) +
# 観測値
geom_point(aes(y = y, color = "観測値 (y_t)"), alpha = 0.6) +
# 状態の事後中央値
geom_line(data = mu_summary, aes(y = `50%`, color = "推定された水位 (μ_t)"), linewidth = 1) +
labs(
title = "状態推定の結果",
subtitle = "カルマンフィルタによる水位の推定値と95%信用区間",
x = "日数", y = "水位 (m)", color = "データ系列"
) +
scale_color_manual(values = c(
"真の水位 (μ_t)" = "black",
"観測値 (y_t)" = "gray50",
"推定された水位 (μ_t)" = "dodgerblue"
)) +
theme_bw() +
theme(legend.position = "bottom")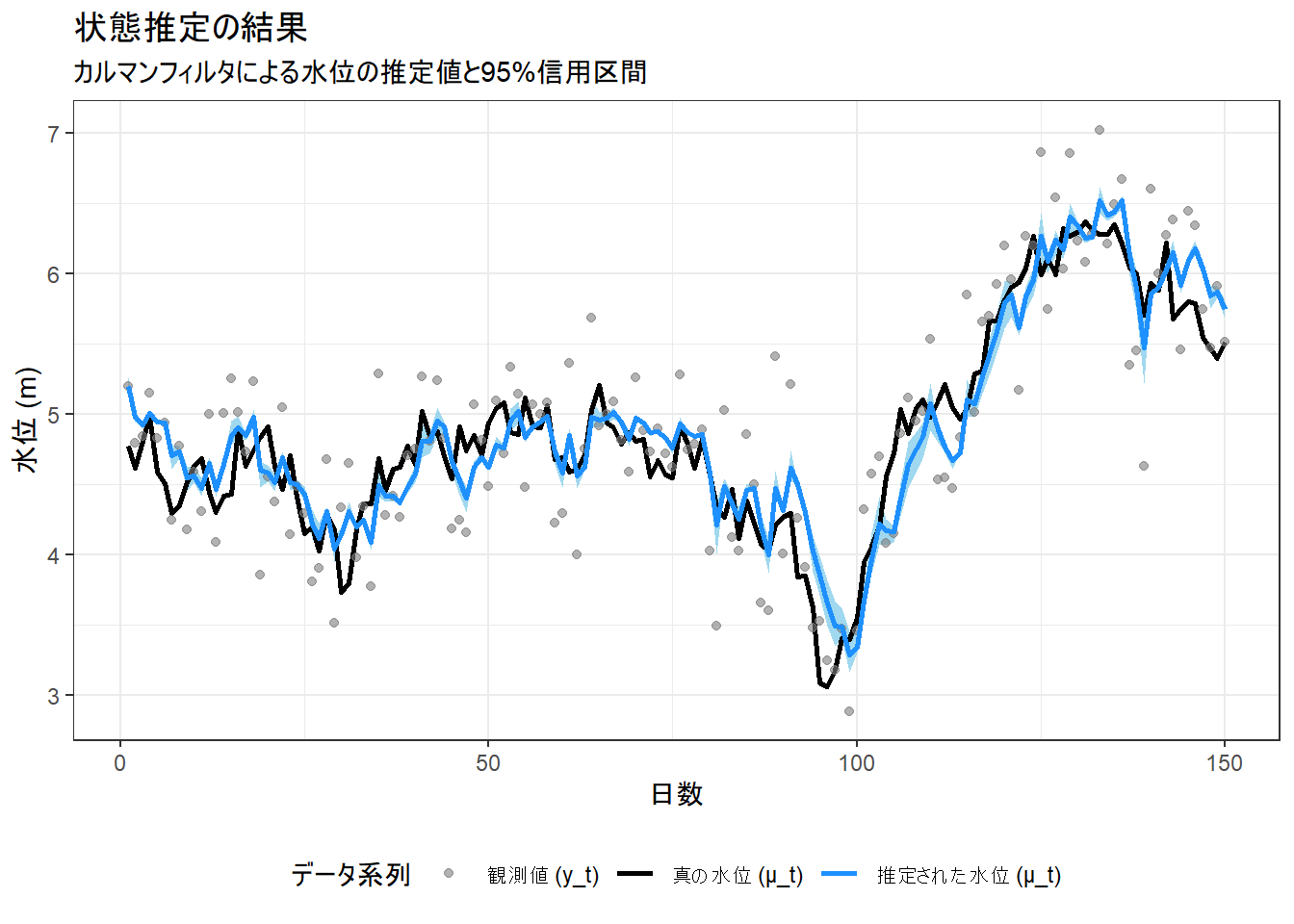
以上です。

