
RStan を利用して 状態空間モデル(ローカルレベルモデル、パラメーター未知) を試みます。
はじめに:ローカルレベルモデルについて
ローカルレベルモデルは、状態空間モデルの中で最も基本的なモデルの一つです。観測できない「真の状態(レベル)」が時間とともにランダムウォークし、我々が観測できるのはその「真の状態」に観測ノイズが加わった値である、と考えます。
数式で表すと以下のようになります。
- 観測方程式: \(y_t = \alpha_t + v_t, \quad v_t \sim N(0, \sigma_v^2)\)
- 状態方程式: \(\alpha_t = \alpha_{t-1} + w_t, \quad w_t \sim N(0, \sigma_w^2)\)
ここで、
- \(y_t\): 時刻\(t\)における観測値
- \(\alpha_t\): 時刻\(t\)における状態(観測できない真のレベル)
- \(v_t\): 観測ノイズ(平均0, 分散\(\sigma_v^2\)の正規分布に従う)
- \(w_t\): システムノイズ(平均0, 分散\(\sigma_w^2\)の正規分布に従う)
- \(\sigma_v^2\): 観測ノイズの分散
- \(\sigma_w^2\): システムノイズの分散
今回は、これらのパラメーター(\(\alpha_t\), \(\sigma_v\), \(\sigma_w\))が未知であるとして、データから推定するシミュレーションを行います。
1. ストーリーとシナリオ設定
シナリオ:新しくオープンした個人経営ベーカリーの100日間の日次売上
このシナリオは、ローカルレベルモデルのシミュレーションに適しています。
観測値 (\(y_t\)): 毎日のレジで記録された売上。レジの打ち間違い、釣銭のミス、記録漏れなど、日々のオペレーションに伴う小さな誤差(観測ノイズ)が含まれます。
状態 (\(\alpha_t\)): その日の「真の売上レベル」。これは、店の評判、リピーターの定着、口コミの広がり、季節限定商品の投入、天候、近隣でのイベント開催など、様々な要因によって日々少しずつ変動します。この前日からの「真の売上レベル」の変動がシステムノイズです。
システムノイズが0に近くないと考える理由: 新設の店舗であるため、開店当初は知名度が低く売上も低いですが、口コミやリピーターの増加によって売上レベルは徐々に上昇傾向にあると考えられます。また、テレビや雑誌で紹介された翌日には売上レベルが急上昇したり、逆に近所で大規模な工事が始まって客足が遠のきレベルが低下したりと、予測不能な外的要因による「真の売上レベル」の変動(システムノイズ)は、無視できない大きさで発生すると考えるのが自然です。
ドメイン知識の注入:
- 売上規模: 個人経営のベーカリーなので、1日の売上は数万円から数十万円程度と想定できます。例えば、開店当初の真の売上レベル(\(\alpha_1\))は平均10万円、標準偏差2万円程度だと見当をつけられます。
- システムノイズの大きさ (\(\sigma_w\)): 「真の売上レベル」が1日で変動する幅は、せいぜい数千円から2万円程度でしょう。極端に小さい(例: 100円)や、極端に大きい(例: 5万円)ことは考えにくいです。そこで、システムノイズの標準偏差 \(\sigma_w\) は500円から20,000円の範囲に収まると仮定します。
- 観測ノイズの大きさ (\(\sigma_v\)): レジの打ち間違いなどは、売上全体から見れば比較的小さいはずです。
これらのドメイン知識をStanのモデル(特に事前分布)に組み込みます。
2. Rによるシミュレーションデータ生成
まず、上記のシナリオに基づいた人工的な観測データを作成します。
library(rstan)
sapply(X = c("rstan"), packageVersion)
stan_output <- "D:/stan_output"
# Stanの並列計算設定
rstan_options(auto_write = TRUE)
options(mc.cores = parallel::detectCores())$rstan
[1] 2 32 7seed <- 20250627
# シミュレーションの条件設定
T <- 100 # 観測期間 (100日間)
alpha_0_true <- 100000 # 初期の真の売上レベル (10万円)
sigma_w_true <- 2500 # システムノイズの標準偏差 (真の値)
sigma_v_true <- 4000 # 観測ノイズの標準偏差 (真の値)
# 状態と観測値の時系列データを生成
set.seed(seed)
alpha_true <- numeric(T)
y_obs <- numeric(T)
w <- rnorm(T, mean = 0, sd = sigma_w_true)
v <- rnorm(T, mean = 0, sd = sigma_v_true)
# ローカルレベルモデルに従ってデータを生成
alpha_true[1] <- alpha_0_true + w[1]
y_obs[1] <- alpha_true[1] + v[1]
for (t in 2:T) {
alpha_true[t] <- alpha_true[t - 1] + w[t]
y_obs[t] <- alpha_true[t] + v[t]
}
# 生成したデータの可視化
sim_data <- data.frame(
time = 1:T,
alpha_true = alpha_true,
y_obs = y_obs
)
library(ggplot2)
ggplot(sim_data, aes(x = time)) +
geom_line(aes(y = alpha_true, color = "真の状態 (alpha)"), linewidth = 1) +
geom_point(aes(y = y_obs, color = "観測値 (y)")) +
scale_color_manual(values = c("真の状態 (alpha)" = "darkred", "観測値 (y)" = "skyblue")) +
labs(
title = "シミュレーションデータ:ベーカリーの日次売上",
x = "日数",
y = "売上(円)",
color = "データ系列"
) +
theme_bw()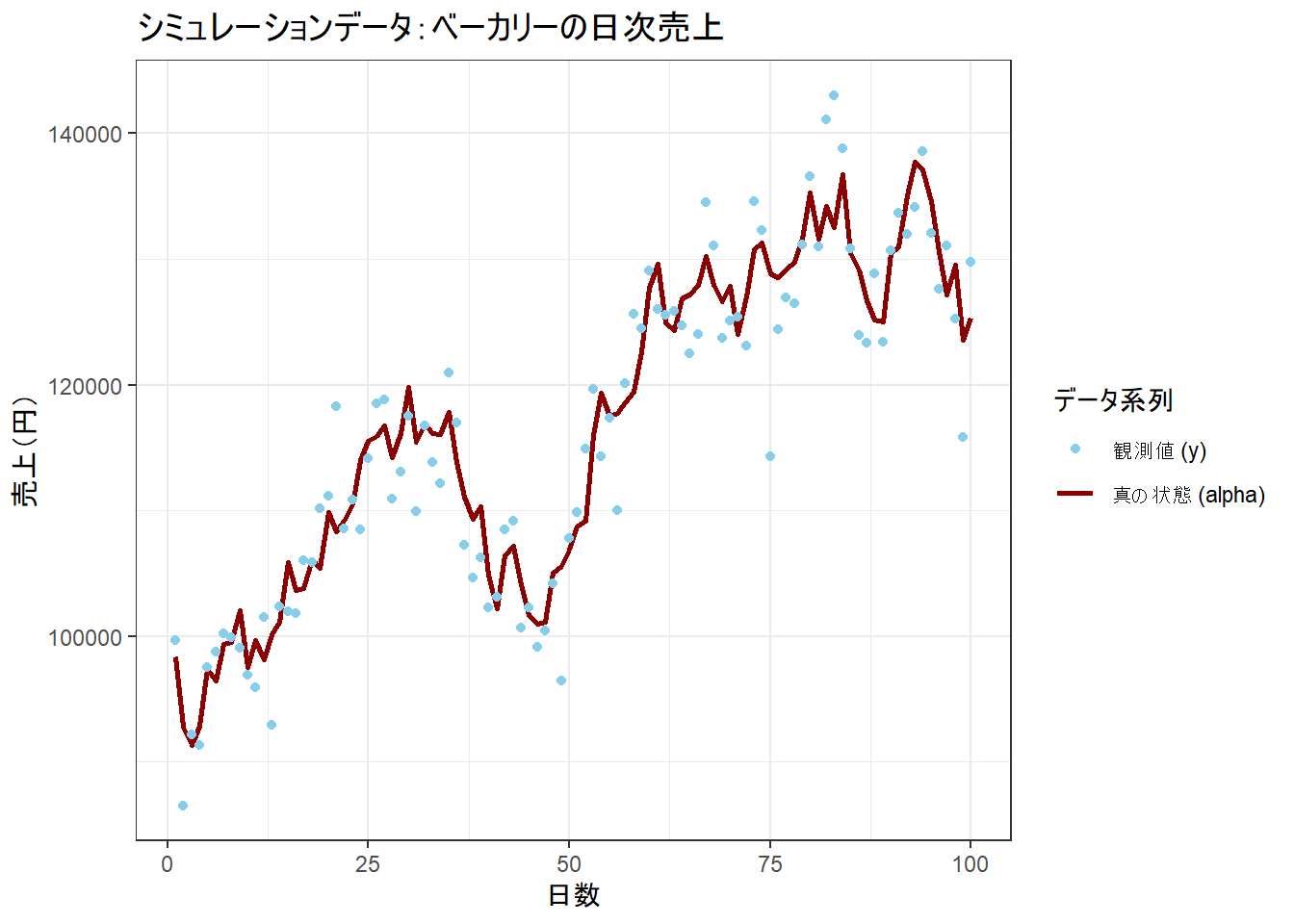
このプロットから、真の状態(赤線)がランダムウォークしており、その周りに観測値(青点)がばらついている様子が確認できます。
3. Stanコードの作成
次に、ローカルレベルモデルをStanで記述します。
モデルにはドメイン知識を事前分布やパラメーターの制約に反映させています。
model_code <- "
data {
int<lower=1> T; // データの期間
vector[T] y; // 観測値ベクトル
}
parameters {
vector[T] alpha; // 状態ベクトル
real<lower=0> sigma_v; // 観測ノイズの標準偏差
real<lower=500, upper=20000> sigma_w; // システムノイズの標準偏差(ドメイン知識による制約)
}
model {
// --- 状態方程式 (システムモデル) ---
// alpha[2]からalpha[T]までが、一つ前のalphaに依存する
// ベクトル化表記:
alpha[2:T] ~ normal(alpha[1:(T-1)], sigma_w);
// forループで書くと以下の通り
// for (t in 2:T) {
// alpha[t] ~ normal(alpha[t-1], sigma_w);
// }
// --- 観測方程式 ---
// 観測値yは、対応する状態alphaに依存する
y ~ normal(alpha, sigma_v);
// --- 事前分布 ---
// 初期状態alpha[1]の事前分布(ドメイン知識)
// 開店初日の売上レベルは平均10万円、標準偏差2万円程度と仮定
alpha[1] ~ normal(100000, 20000);
// 観測ノイズの標準偏差の事前分布
// 裾の重いコーシー分布を無情報に近い形で使用
sigma_v ~ cauchy(0, 5000);
// システムノイズの標準偏差の事前分布
// parametersブロックの制約 <lower=500, upper=20000> に対応する
// 一様分布の対数尤度をtargetに加算する。
target += uniform_lpdf(sigma_w | 500, 20000);
}
generated quantities {
// 1期先の予測値を生成
real alpha_pred;
real y_pred;
alpha_pred = normal_rng(alpha[T], sigma_w);
y_pred = normal_rng(alpha_pred, sigma_v);
}
"4. RStanによるモデリング実行
作成したStanコードとシミュレーションデータを用いて、MCMCによるパラメーター推定を実行します。
# Stanに渡すデータの準備
stan_data <- list(T = T, y = y_obs)
# Stanモデルのコンパイルと実行
fit <- stan(
model_code = model_code,
data = stan_data, # 投入データ
iter = 6000, # MCMCのステップ数
warmup = 3000, # バーンイン期間
chains = 4, # チェーンの数
seed = seed # 乱数シード
)
# stanfit オブジェクトの保存
setwd(stan_output)
saveRDS(object = fit, file = "stan_fit.rds")5. 結果の確認と可視化
以下に示します通り、本シミュレーションの結果からは、きれいなトレースプロットと事後分布のヒストグラム は得られませんでした。
なお、sigma_w と sigma_v の R-hat は共に 1 であり、真のパラメーター(sigma_w_true = 2500, sigma_v_true = 4000)はそれぞれの95%信用区間(2387.22~5212.41 と 1954.68~4432.62)に含まれているから、と自分を慰めて先に進みます。
R-hat
# stanfit オブジェクトの読み込み
setwd(stan_output)
fit <- readRDS("stan_fit.rds")
# パラメーターの R-hat を確認
print(fit,
pars = c("sigma_v", "sigma_w", "lp__"),
probs = c(0.025, 0.5, 0.975)
)Inference for Stan model: anon_model.
4 chains, each with iter=6000; warmup=3000; thin=1;
post-warmup draws per chain=3000, total post-warmup draws=12000.
mean se_mean sd 2.5% 50% 97.5% n_eff Rhat
sigma_v 3320.44 22.76 618.40 1954.68 3358.93 4432.62 738 1
sigma_w 3609.44 23.84 717.08 2387.22 3542.81 5212.41 905 1
lp__ -1710.84 0.49 13.36 -1734.26 -1711.35 -1685.57 738 1
Samples were drawn using NUTS(diag_e) at Fri Jun 27 16:48:54 2025.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).トレースプロット
bayesplot::mcmc_trace(fit, pars = c("sigma_v", "sigma_w"))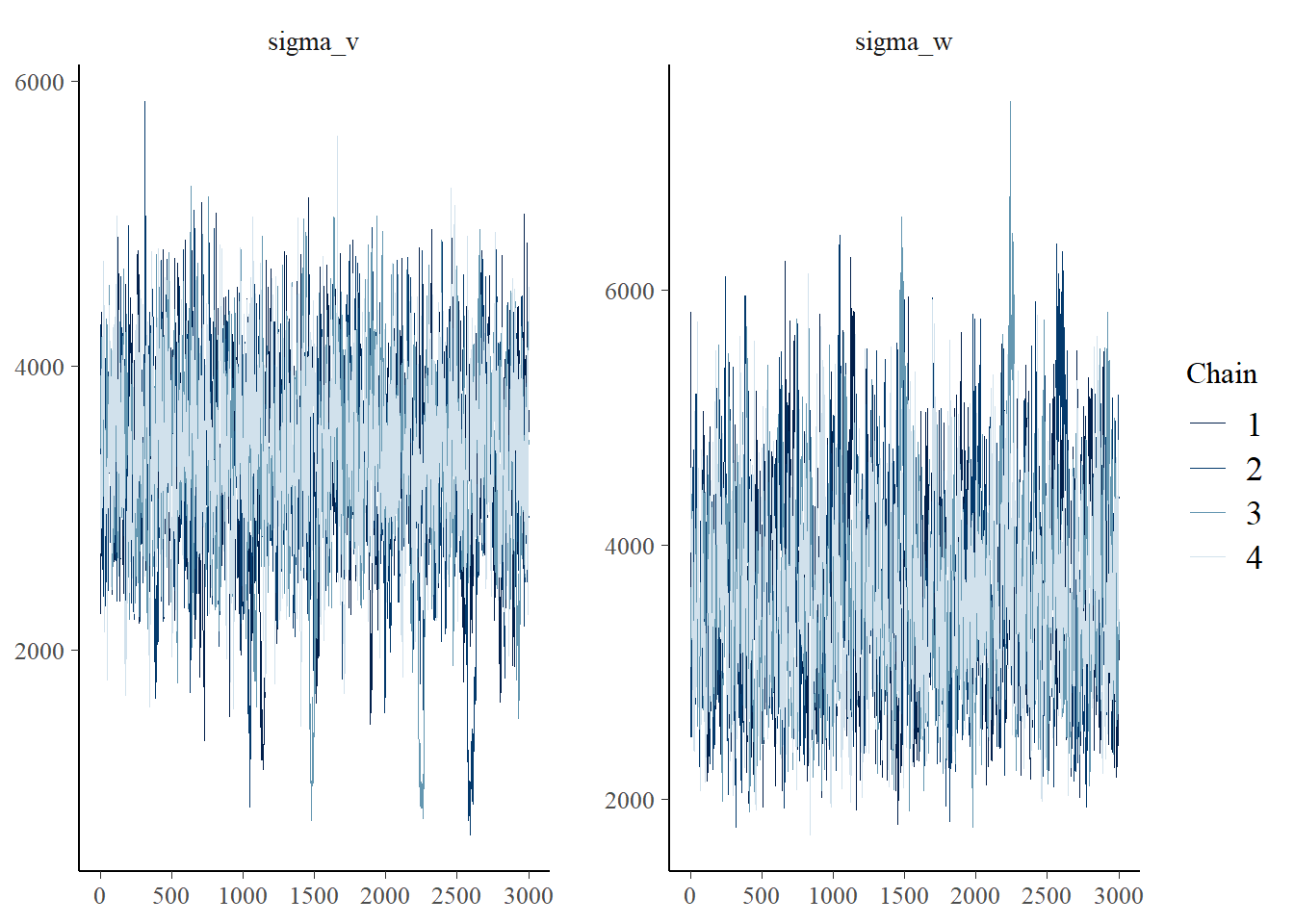
パラメーターの事後分布
赤の破線がシミュレーションで設定した真の値です。
# MCMCサンプルの抽出
mcmc_sample <- rstan::extract(fit)
# パラメーターの事後分布をプロット
p1 <- bayesplot::mcmc_hist(fit, pars = "sigma_w") +
geom_vline(xintercept = sigma_w_true, color = "red", linetype = "dashed") +
labs(title = "システムノイズ標準偏差 (sigma_w) の事後分布")
p2 <- bayesplot::mcmc_hist(fit, pars = "sigma_v") +
geom_vline(xintercept = sigma_v_true, color = "red", linetype = "dashed") +
labs(title = "観測ノイズ標準偏差 (sigma_v) の事後分布")
library(patchwork)
p1 + p2 # patchworkでプロットを並べる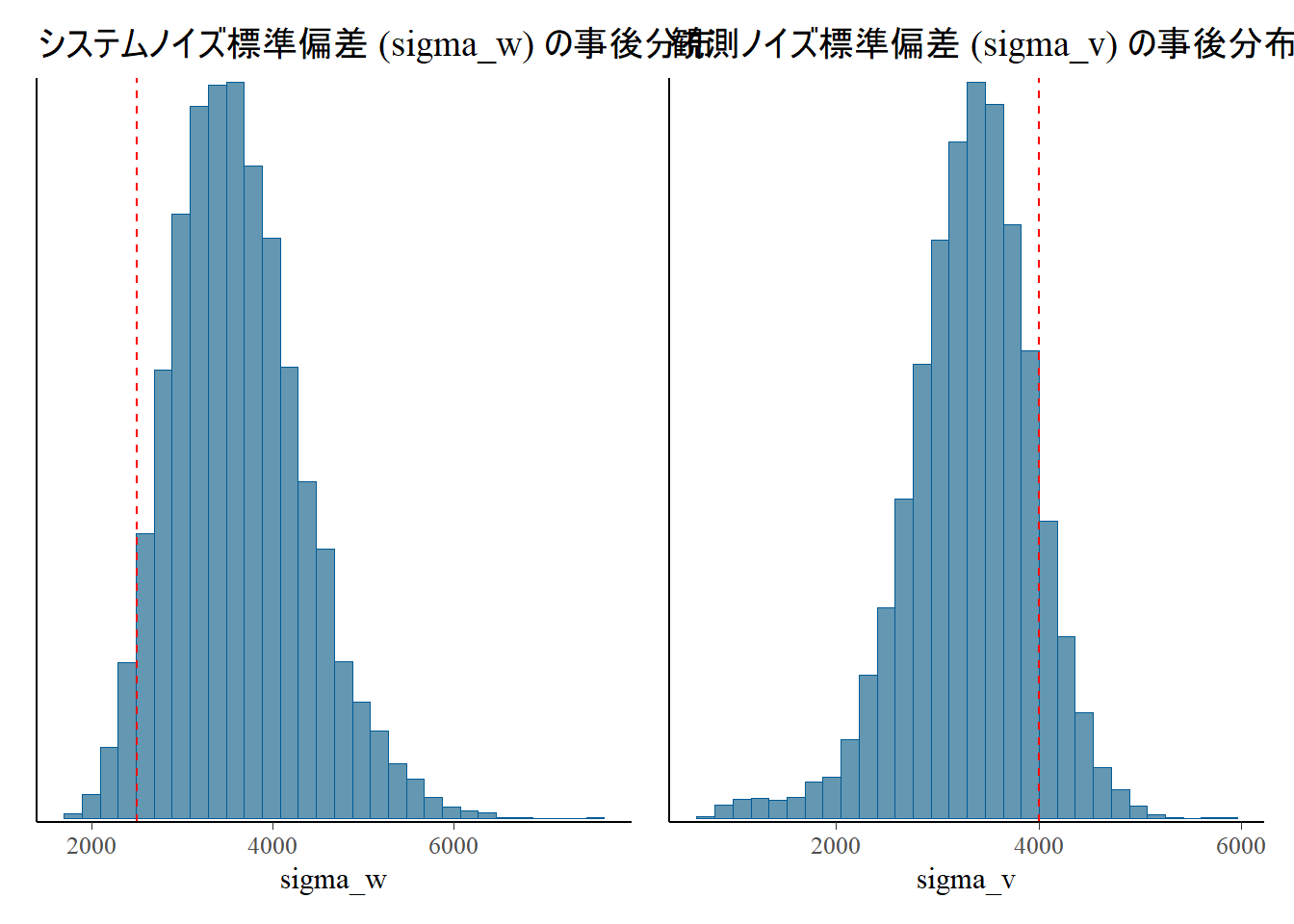
状態の推定結果の可視化
最後に、モデルが推定した「真の売上レベル」(\(\alpha_t\))の推移を、観測値やシミュレーション上の真の状態と比較します。
# alphaの事後分布から中央値と95%信用区間を計算
alpha_est <- summary(fit, pars = "alpha")$summary
alpha_summary <- data.frame(
time = 1:T,
mean = alpha_est[, "mean"],
lower = alpha_est[, "2.5%"],
upper = alpha_est[, "97.5%"]
)
# 結果をプロット
ggplot(alpha_summary, aes(x = time)) +
geom_ribbon(aes(ymin = lower, ymax = upper), fill = "skyblue", alpha = 0.5) +
geom_line(aes(y = mean, color = "推定された状態 (alpha)"), linewidth = 1) +
geom_line(data = sim_data, aes(y = alpha_true, color = "真の状態"), linewidth = 1) +
geom_point(data = sim_data, aes(y = y_obs, color = "観測値"), alpha = 0.6) +
scale_color_manual(
name = "データ系列",
values = c(
"推定された状態 (alpha)" = "blue",
"真の状態" = "darkred",
"観測値" = "black"
)
) +
labs(
title = "ローカルレベルモデルによる状態の推定結果",
x = "日数",
y = "売上(円)"
) +
theme_bw()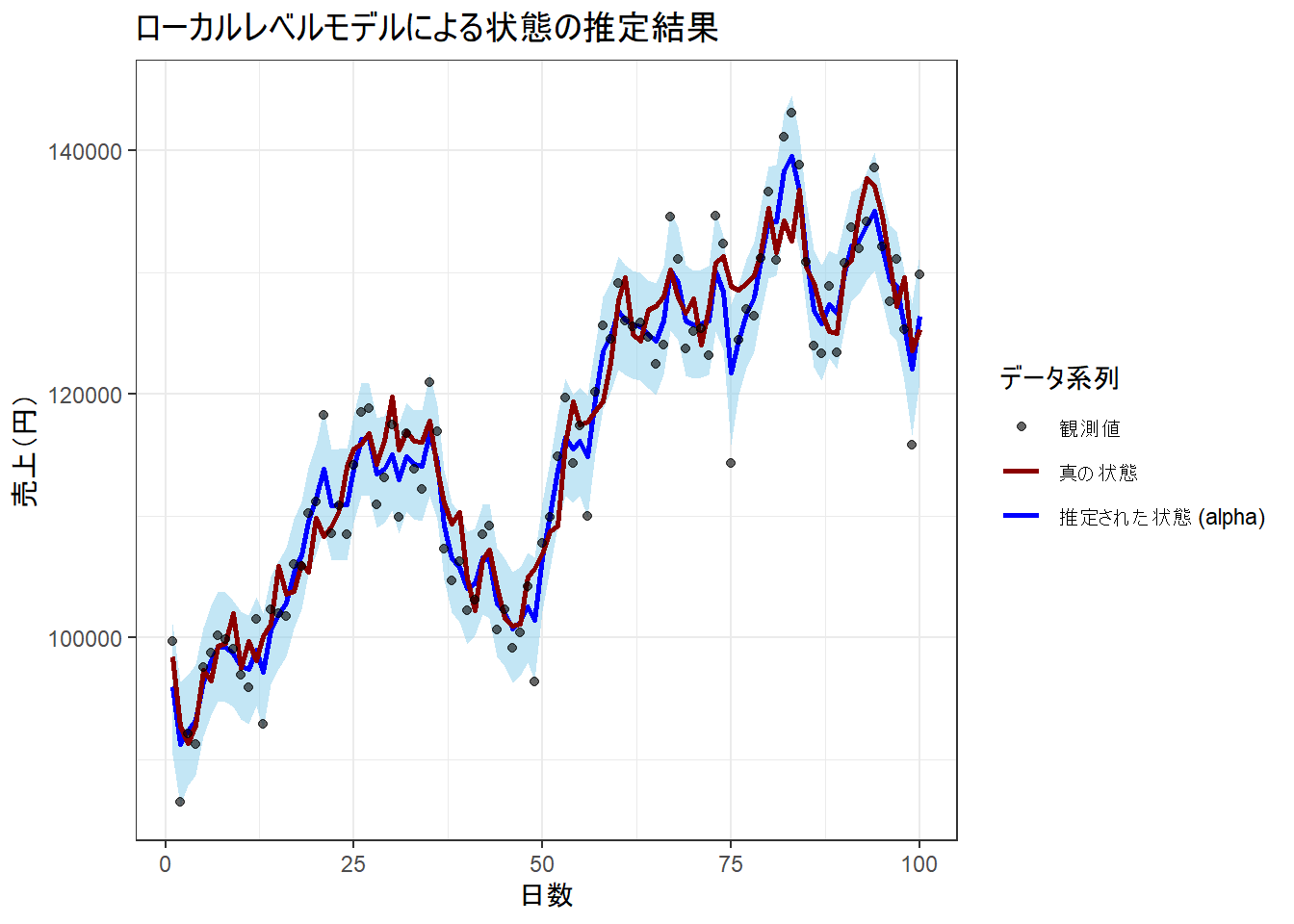
- 黒点(観測値): 日々のばらつきが大きい売上データです。
- 赤線(真の状態): シミュレーションで作成した、本来観測できない「真の売上レベル」です。
- 青線(推定された状態): モデルが観測値から推定した「真の売上レベル」の事後中央値です。
- 水色の帯(95%信用区間): 推定の不確実性の幅です。
以上です。

