
RStan を利用して 単回帰分析 の結果を利用した 外挿 を試みます。
1. ストーリー、シナリオ
舞台は、海辺の町にある架空の小さなパン屋さん「ふわふわベーカリー」。
店主のあなたは、最近、ある傾向に気づきました。それは、「日中の最高気温が高い日ほど、冷たい飲み物と相性の良いクロワッサンの売上が伸びる」ということです。
もしこの関係を数値でしっかり捉えることができれば、天気予報を見て翌日のクロワッサンの仕込み量を最適化し、フードロスを減らしながら販売機会を最大化できるかもしれません。
そこであなたは、過去30日間の「日中の最高気温(度)」と「クロワッサンの売上個数」を記録したデータを分析することにしました。さらに、これからやってくる真夏日(例えば30度)には、一体どれくらい売れるのかを予測(外挿)して、特別な準備をしたいと考えています。
- 説明変数 (X): 日中の最高気温 (度)
- 目的変数 (Y): クロワッサンの売上個数
このシナリオで、気温と売上の関係をベイズ単回帰モデルで分析し、まだ経験したことのない気温での売上を予測してみましょう。
なお、あまりに気温が高いと、または低いとそもそも外に出ないし、特に暑いと食欲は・・・・、というストーリは 無視 し、あくまでも 単純な線形 の話とします。
2. RStanによる単回帰分析の実行
まず、必要なライブラリをロードし、シナリオに沿ったシミュレーションデータを作成します。
2.1. 準備とデータ生成
# RStanの読み込み
library(rstan)
stan_output <- "D:/stan_output"
# Stanの並列計算設定
rstan_options(auto_write = TRUE)
options(mc.cores = parallel::detectCores())
# rstan のバージョン確認
cat("--- パッケージ rstan のバージョン確認 ---\n")
sapply(X = c("rstan"), packageVersion)--- パッケージ rstan のバージョン確認 ---
$rstan
[1] 2 32 7seed <- 20250629
set.seed(seed)
# ---- シミュレーションデータの作成 ----
# ストーリーに基づいたパラメータを設定
N <- 30 # 観測日数
alpha_true <- 20 # 気温0度の時の基礎売上(切片)
beta_true <- 5 # 気温が1度上がるごとの売上増加数(傾き)
sigma_true <- 8 # 日々のばらつき(標準偏差)
# 説明変数:気温データ (15度〜25度の範囲で観測)
temperature <- runif(N, 15, 25)
# 目的変数:クロワッサンの売上個数データ
# y = a + b*x + ε (εは正規分布に従う誤差)
sales <- round(alpha_true + beta_true * temperature + rnorm(N, 0, sigma_true))
sales[sales < 0] <- 0 # 売上はマイナスにならない
# データフレームにまとめる
bakery_data <- data.frame(temperature, sales)
# 生成したデータの一部を確認
head(bakery_data) temperature sales
1 15.87028 104
2 18.78233 106
3 16.51059 108
4 17.75212 119
5 24.73507 144
6 18.15727 115# データをプロットして関係性を確認
library(ggplot2)
ggplot(bakery_data, aes(x = temperature, y = sales)) +
geom_point(color = "skyblue", size = 3) +
labs(
title = "気温とクロワッサンの売上(観測データ)",
x = "最高気温 (度)",
y = "クロワッサン売上個数"
) +
theme_bw()
生成されたデータを見ると、気温が高いほど売上が増加する傾向が見て取れます。
2.2. Stanモデルの記述
次に、単回帰分析を行うためのStanモデルを記述します。
model_code <- "
data {
int<lower=0> N; // データ数
vector[N] x; // 説明変数 (temperature)
vector[N] y; // 目的変数 (sales)
}
parameters {
real alpha; // 切片 (intercept)
real beta; // 傾き (slope)
real<lower=0> sigma; // 誤差の標準偏差
}
model {
// 事前分布 (比較的情報量の少ない弱情報事前分布)
alpha ~ normal(0, 100);
beta ~ normal(0, 100);
sigma ~ cauchy(0, 5);
// 尤度 (単回帰モデルの本体)
// y は 平均 alpha + beta * x, 標準偏差 sigma の正規分布に従う
y ~ normal(alpha + beta * x, sigma);
}
generated quantities {
// 予測分布を生成するための部分
vector[N] y_pred;
for (n in 1:N) {
y_pred[n] = normal_rng(alpha + beta * x[n], sigma);
}
}
"なお、もし店主が「気温が上がっても売上が減ることは絶対にない」という強い信念(事前知識)を持っていれば、傾きbetaの事前分布をnormal(0, 100)ではなく、betaが必ず正の値を取るような分布(例: lognormal分布や範囲制約)に設定することも出来ます。
2.3. MCMCによるパラメータ推定
作成したStanモデルとデータを使って、MCMC(マルコフ連鎖モンテカルロ法)を実行し、パラメータ alpha, beta, sigma の事後分布を求めます。
# Stanに渡すためのデータをリスト形式で準備
data_list <- list(
N = nrow(bakery_data),
x = bakery_data$temperature,
y = bakery_data$sales
)
# StanモデルのコンパイルとMCMCの実行
fit <- stan(
model_code = model_code,
data = data_list, # データ
seed = seed, # 乱数シード
iter = 2000, # サンプリング回数
warmup = 1000, # バーンイン期間
chains = 4 # MCMCのチェーン数
)
# stanfit オブジェクトの保存
setwd(stan_output)
saveRDS(object = fit, file = "stan_fit.rds")# stanfit オブジェクトの読み込み
setwd(stan_output)
fit <- readRDS("stan_fit.rds")
cat("--- 結果の要約 ---\n")
summary(fit, pars = c("alpha", "beta", "sigma"), probs = c(0.025, 0.5, 0.975))$summary
sampler_params <- get_sampler_params(fit, inc_warmup = FALSE)
divergences <- sum(sapply(sampler_params, function(x) sum(x[, "divergent__"])))
cat("\nDivergent Transitionsの数:", divergences, "\n")--- 結果の要約 ---
mean se_mean sd 2.5% 50% 97.5% n_eff
alpha 34.921371 0.34340894 11.6008698 11.690520 35.141888 57.786486 1141.190
beta 4.247691 0.01623420 0.5500276 3.163192 4.246486 5.352274 1147.908
sigma 7.812061 0.02813581 1.0576854 6.073530 7.696665 10.198079 1413.169
Rhat
alpha 1.001809
beta 1.001659
sigma 1.000139
Divergent Transitionsの数: 0 Stan実行の結果、警告メッセージ は出ませんでしたが、各パラメータの事後分布の平均値を確認しますと、alpha_true=20, beta_true=5, sigma_true=8 ですので alpha は 35 と離れています。
但し、3つの真のパラメータはいずれも95%信用区間に含まれており、Rhat も 1.0 に近く、Divergent Transitions も 0 であるため、本シミュレーションではこのまま先に進みます。
3. 予測モデルを利用した外挿
推定したモデルを使って、観測範囲外の気温におけるクロワッサンの売上を外挿してみましょう。
3.1. 予測値の計算とグラフ化
MCMCによって得られたパラメータのサンプル(事後分布)を使い、観測範囲外の気温における売上の予測分布を計算します。
# MCMCサンプルを抽出
mcmc_samples <- rstan::extract(fit)
# 予測したい新しい気温データ(観測範囲外を含む)
temp_new <- seq(10, 35, length.out = 100)
# 各MCMCサンプルを使って、回帰直線の予測値を計算
pred_mu <- sapply(temp_new, function(t) mcmc_samples$alpha + mcmc_samples$beta * t)
pred_mu_mean <- apply(pred_mu, 2, mean)
pred_mu_ci <- apply(pred_mu, 2, quantile, probs = c(0.025, 0.975))
# 各MCMCサンプルを使って、将来のデータを予測
pred_y <- sapply(temp_new, function(t) {
mu <- mcmc_samples$alpha + mcmc_samples$beta * t
rnorm(length(mu), mu, mcmc_samples$sigma)
})
pred_y_ci <- apply(pred_y, 2, quantile, probs = c(0.025, 0.975))
# グラフ化のためにデータフレームを整形
pred_df <- data.frame(
temperature = temp_new,
mu_mean = pred_mu_mean,
mu_ci_lower = pred_mu_ci[1, ],
mu_ci_upper = pred_mu_ci[2, ],
y_ci_lower = pred_y_ci[1, ],
y_ci_upper = pred_y_ci[2, ]
)
# 外挿部分を可視化するためのグラフ作成
ggplot(pred_df, aes(x = temperature)) +
# 95%予測区間(薄い青色リボン)
geom_ribbon(aes(ymin = y_ci_lower, ymax = y_ci_upper), fill = "skyblue", alpha = 0.3) +
# 95%信用区間(濃い青色リボン)
geom_ribbon(aes(ymin = mu_ci_lower, ymax = mu_ci_upper), fill = "blue", alpha = 0.4) +
# 回帰直線(事後平均)
geom_line(aes(y = mu_mean), color = "darkblue", linewidth = 1) +
# 元のデータ点
geom_point(data = bakery_data, aes(x = temperature, y = sales), color = "black", size = 2.5) +
# 観測範囲を区切る縦線
geom_vline(xintercept = max(bakery_data$temperature), linetype = "dashed", color = "red") +
geom_vline(xintercept = min(bakery_data$temperature), linetype = "dashed", color = "red") +
annotate("text", x = max(bakery_data$temperature), y = 50, label = "←観測範囲 | 外挿範囲→", color = "red") +
annotate("text", x = min(bakery_data$temperature), y = 50, label = "←外挿範囲 | 観測範囲→", color = "red") +
scale_x_continuous(breaks = seq(10, 35, 5)) +
labs(
title = "ベイズ単回帰による売上予測と外挿",
subtitle = "リボン:青(信用区間), 水色(予測区間)",
x = "最高気温 (度)",
y = "クロワッサン売上個数"
) +
coord_cartesian(ylim = c(0, 220)) +
theme_bw()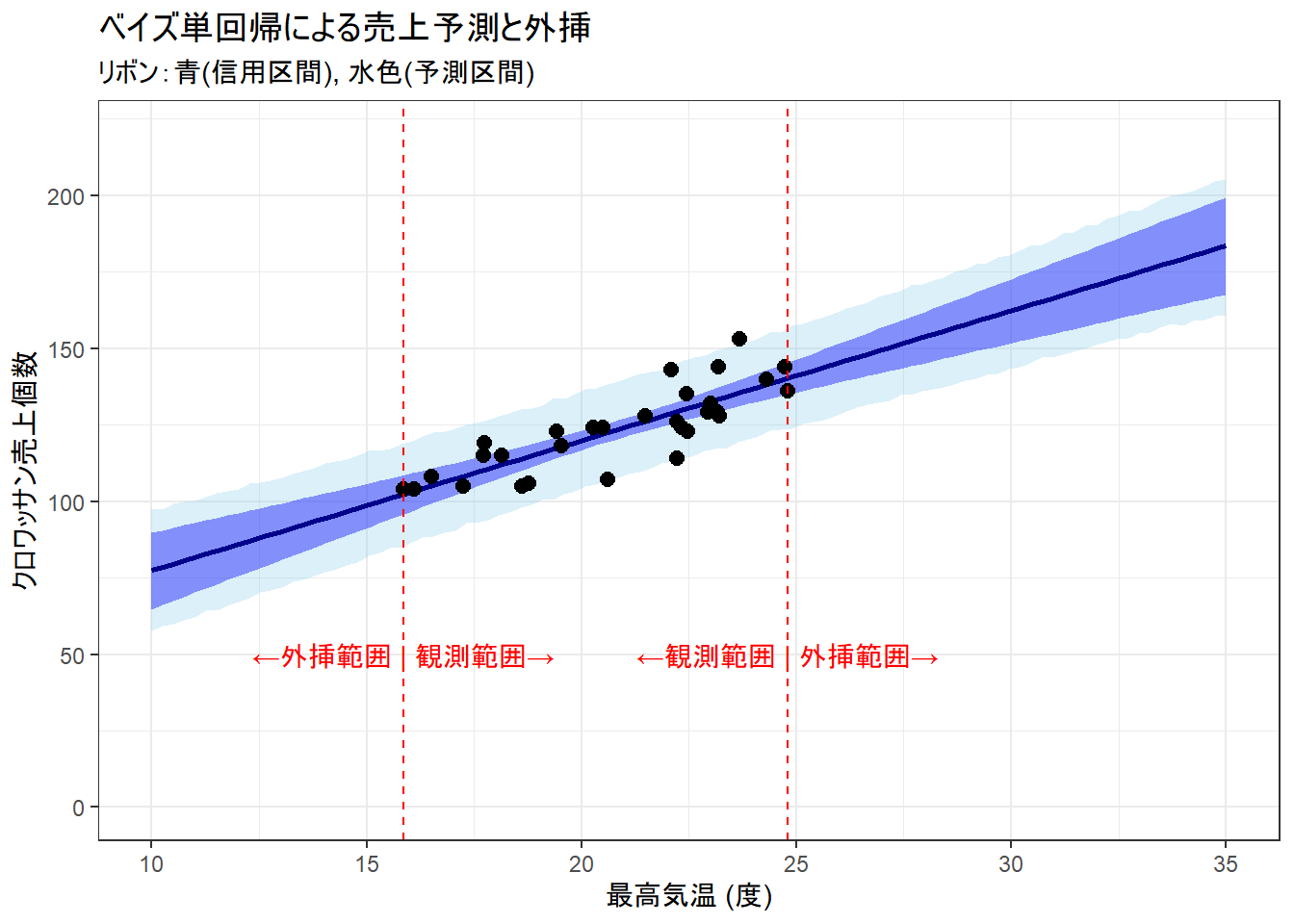
3.2. グラフの解説
- 黒い点: 実際に観測した30日分のデータ(気温と売上)です。
- 濃い青の線: 推定された回帰直線(
y = alpha + beta * x)の平均です。 - 濃い青のリボン (95%信用区間): 回帰直線そのものの不確実性を表します。「真の平均的な売上ライン」が95%の確率でこの範囲に存在することを示します。観測データから離れる(外挿する)ほど、線の位置が不確かになるため、リボンの幅が広がっていきます。
- 水色のリボン (95%予測区間): これから新しく観測される1日の売上が95%の確率で含まれる範囲です。これは、回帰直線の不確実性(濃い青リボン)に加えて、データ自体のばらつき(
sigma)も考慮しているため、幅がより広くなります。 - 赤い破線: 観測データの気温の最大値と最小値を示します。この線より外側が「外挿」を行っている領域です。
3.3. 外挿結果の解釈
グラフからわかるように、観測データがない外挿領域では、信用区間・予測区間ともに気温の変化に伴って幅が広がっていきます。
例えば、気温30度の日の売上を予測すると、
- 平均的には 約160個 (
34.9 + 4.25 * 30) 売れそうです。 - しかし、95%予測区間を見ると、売上は約140個から180個という広い範囲に分布する可能性があることがわかります。
この「不確実性の可視化」により、店主は「平均160個くらい仕込もう。でも、運が悪ければ140個しか売れないかもしれないし、運が良ければ180個売れるチャンスもある」というリスクを定量的に把握した上で、仕込み量を決めることができます。
3.4 特定の気温における売上予測
MCMCシミュレーションによって得られたパラメータの事後分布(mcmc_samples)を用いて、特定の気温における売上がどのようになるかを数値で予測します。
ここでは、予測される売上の平均値と、その売上が95%の確率で収まる範囲である95%予測区間を計算します。
予測コード
# 予測したい気温のベクトル
target_temps <- c(28, 30, 35)
# 各気温での予測分布を生成し、要約する
# lapply を使って、各気温に対して同じ処理を繰り返す
prediction_summary_list <- lapply(target_temps, function(temp) {
# 1. 予測の平均(mu)を各MCMCサンプルで計算
# mcmc_samplesにはalphaとbetaのサンプルが4000個入っている
pred_mu <- mcmc_samples$alpha + mcmc_samples$beta * temp
# 2. 予測分布(y_pred)を生成
# 各MCMCサンプルのパラメータ(pred_mu, sigma)を使って、
# 正規分布から新しいデータをシミュレーションする
y_pred <- rnorm(
n = length(pred_mu), # サンプル数 (4000)
mean = pred_mu,
sd = mcmc_samples$sigma
)
# 3. 予測分布の要約統計量を計算し、データフレームとして返す
# 売上個数は整数なのでround()で丸める
data.frame(
"気温(度)" = temp,
"予測売上_平均" = round(mean(y_pred)),
"予測売上_中央値" = round(median(y_pred)),
"95%予測区間_下限" = round(quantile(y_pred, 0.025)),
"95%予測区間_上限" = round(quantile(y_pred, 0.975)),
check.names = FALSE, # 列名に特殊文字を許す
row.names = NULL
)
})
# リストを一つのデータフレームにまとめる
prediction_summary_df <- do.call(rbind, prediction_summary_list)
cat("--- 予測結果 ---\n")
print(prediction_summary_df)--- 予測結果 ---
気温(度) 予測売上_平均 予測売上_中央値 95%予測区間_下限 95%予測区間_上限
1 28 154 154 136 172
2 30 162 162 144 181
3 35 184 184 161 206結果の解釈
この表から、パン屋の店主は以下のような具体的な意思決定の情報を得ることができます。
- 気温28度の日:
- 平均して 154個 程度の売上が見込める。
- ただし、不確実性を考慮すると、売上は95%の確率で 136個から172個 の範囲に収まるだろう。もしフードロスを絶対に避けたいなら136個、機会損失を避けたいなら172個に近い数を準備するなど、リスク許容度に応じた判断ができる。
- 気温30度の日:
- 平均売上予測は 162個 に上昇する。
- 95%予測区間は 144個から181個 となり、28度の日と比べて不確実性の幅が1個分であるが広がっている。
- 気温35度の日:
- 平均売上予測は 184個 となる。
- 95%予測区間は 161個から206個 と、28度の日と比べて9個分、不確実性の幅が広がる。35度という未経験の気温での売上予測には、これだけの不確実性が伴うことを定量的に把握できる。
このように、ベイズ推定を用いた外挿は、単一の予測値を提示するだけでなく、その予測に伴う「不確実性の大きさ」を示すことで意思決定を支援します。
以上です。

