
RStan を利用して 時変係数モデル を試みます。
1. ストーリー、シナリオの設定
シナリオ:新発売スマートフォンの広告キャンペーン効果分析
ある電機メーカーが、画期的な新機能を搭載したスマートフォンを発売しました。発売から1年間(52週間)、毎週テレビCMを中心とした広告キャンペーンを展開します。
私たちはこの企業のデータサイエンティストとして、「週ごとの広告投下量(GRP)が、週ごとの売上台数にどのような影響を与えているか」を分析するタスクを任されました。
この関係性を分析する上で、私たちは以下の仮説を立てました。
- 初期効果と摩耗効果(Wear-out Effect): キャンペーン開始当初は、新製品の目新しさから広告効果は非常に高いでしょう。しかし、週を追うごとに消費者が広告に慣れてしまい、その効果(係数)は徐々に低下していく(摩耗していく)と予想されます。
- 外部からの突発的なイベント: キャンペーン開始から30週目に、強力なライバル企業が競合製品を市場に投入しました。この出来事により、自社製品の広告が相対的に注目されにくくなり、広告効果が一時的あるいは恒久的に急落する可能性があります。
このように、広告投下量(説明変数)が売上(応答変数)に与える影響(係数)は、期間を通じて一定ではなく、時間とともに「滑らかに変化」し、時には「急激に変化」すると考えられます。このような動的な関係性を捉えるため、以下の動機により時変係数モデルを用いた分析を行うことにしました。
- マーケティングにおける広告効果は、「摩耗効果」のように時間経過で変化すると考えられ、「競合の参入」といった外部環境の変化が、その関係性に影響を与えることも自明です。そのため、係数が時間を通じて一定であると仮定するモデル(例:
sales ~ grp)では、誤った示唆を導く危険性があります。 - 時変係数モデルは、係数が時間と共に確率的に変動することを前提とし、データが示す滑らかな変化と急激な変化の両方を捉えることができます。もし固定係数のモデルを使っていたら、広告効果は期間全体の平均値としてたった一つの数値でしか推定されず、「いつ効果が高かったのか」、「競合のインパクトはどの程度だったのか」といった問いに答えることができません。
2. RとRStanによるシミュレーションと推定
2.1. 準備:必要なパッケージの読み込み
まず、分析に必要なRパッケージを準備します。
# RStanの読み込み
library(rstan)
stan_output <- "D:/stan_output"
# Stanの並列計算設定
rstan_options(auto_write = TRUE)
options(mc.cores = parallel::detectCores())
# rstan のバージョン確認
cat("--- パッケージ rstan のバージョン確認 ---\n")
sapply(X = c("rstan"), packageVersion)--- パッケージ rstan のバージョン確認 ---
$rstan
[1] 2 32 72.2. シミュレーションデータの生成
上記のシナリオに沿ったデータを生成します。
-
alpha: 基礎的な売上レベル(切片)。緩やかに変動すると仮定。 -
beta: 広告効果(時変係数)。徐々に低下し、30週目に急落するように設定。
# データ生成の設定
seed <- 20250702
set.seed(seed)
T <- 52 # 観測期間:52週間
# --- 真のパラメータを生成 ---
# 1. 基礎売上レベル(時変切片 alpha_t)
# ランダムウォークで生成
alpha_true <- numeric(T)
alpha_true[1] <- 100 # 初期値
sigma_w_alpha <- 2 # システムノイズの標準偏差
for (t in 2:T) {
alpha_true[t] <- alpha_true[t - 1] + rnorm(1, mean = 0, sd = sigma_w_alpha)
}
# 2. 広告効果(時変係数 beta_t)
# シナリオに沿って生成
beta_true <- numeric(T)
beta_true[1] <- 2.5 # 初期値
sigma_w_beta <- 0.1 # システムノイズの標準偏差
for (t in 2:T) {
beta_true[t] <- beta_true[t - 1] + rnorm(1, mean = 0, sd = sigma_w_beta)
}
# 摩耗効果を表現するために、全体的に少しずつ減少させる
beta_true <- beta_true - seq(0, 1, length.out = T)
# 30週目に競合が登場し、効果が急落するイベント
beta_true[30:T] <- beta_true[30:T] - 1.0
# 3. 説明変数:広告投下量(GRP)
# 毎週のGRPをランダムに生成
X_grp <- round(runif(T, min = 50, max = 150))
# 4. 観測ノイズ
sigma_v <- 20 # 観測ノイズの標準偏差
# 5. 観測データ(売上 Y_sales)の生成
# 観測方程式: Y_t = alpha_t + beta_t * X_t + v_t
Y_sales <- numeric(T)
for (t in 1:T) {
Y_sales[t] <- alpha_true[t] + beta_true[t] * X_grp[t] + rnorm(1, mean = 0, sd = sigma_v)
}
Y_sales <- round(Y_sales) # 売上台数なので整数に丸める
# --- 生成したデータをデータフレームにまとめる ---
sim_data <- tidyr::tibble(
time = 1:T,
sales = Y_sales,
grp = X_grp,
alpha_true = alpha_true,
beta_true = beta_true
)
# --- 生成したデータの可視化 ---
library(ggplot2)
p1 <- ggplot(sim_data, aes(x = time, y = sales)) +
geom_line() +
labs(title = "週次売上台数の推移", x = "週", y = "売上台数") +
theme_bw()
p2 <- ggplot(sim_data, aes(x = time, y = beta_true)) +
geom_line(color = "red", linewidth = 1) +
geom_vline(xintercept = 30, linetype = "dashed") +
annotate("text", x = 30.5, y = 1.2, label = "競合製品の登場", hjust = 0, size = 4) +
labs(title = "真の広告効果(beta)の推移", x = "週", y = "広告効果(係数)") +
theme_bw()
# patchworkでグラフを並べる
library(patchwork)
p1 + p2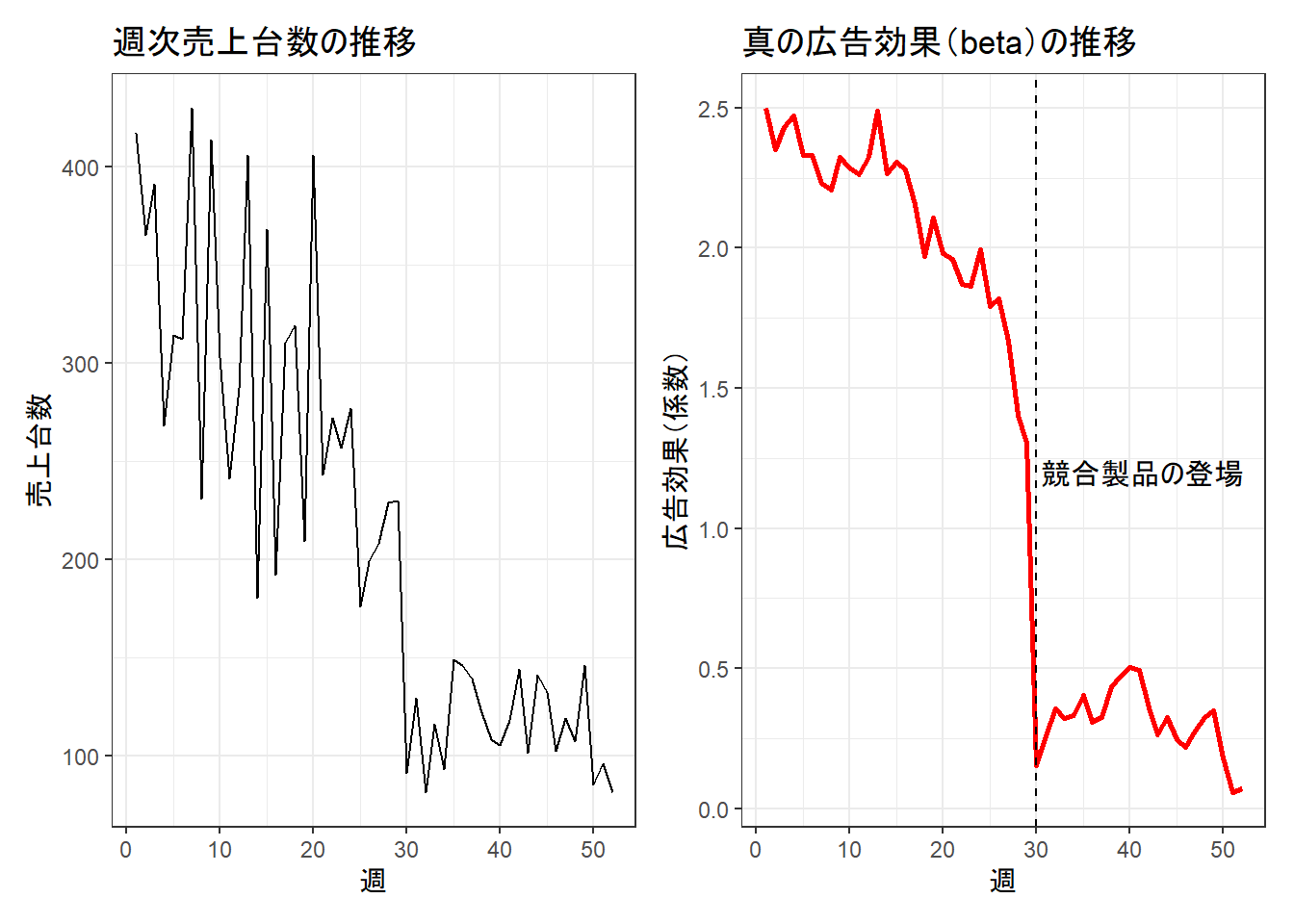
左のグラフがシミュレーションで生成された「観測データ(週次売上)」、右のグラフが我々が推定したい「隠れた状態(広告効果の真の値)」です。betaが徐々に低下し、30週目に急落しているのがわかります。
2.3. Stanによるモデリング
次に、このデータを分析するための状態空間モデルをStanで記述します。 状態方程式(alphaとbetaの動き)を非中心化パラメータ化(NCP)で実装します。NCPは、システムノイズの標準偏差が小さい場合にMCMCのサンプリング効率を改善するテクニックです。
モデルの構造
- 観測方程式:
sales[t] ~ normal(alpha[t] + beta[t] * grp[t], sigma_v) - 状態方程式 (alpha):
alpha[t] ~ normal(alpha[t-1], sigma_w_alpha) - 状態方程式 (beta):
beta[t] ~ normal(beta[t-1], sigma_w_beta)
model_code <- "
data {
int<lower=1> T; // 期間の長さ
vector[T] y; // 観測値 (売上)
vector[T] x; // 説明変数 (GRP)
}
parameters {
// 非中心化された状態変数
vector[T] alpha_raw;
vector[T] beta_raw;
// 初期値
real alpha1;
real beta1;
// 標準偏差パラメータ
real<lower=0> sigma_v; // 観測ノイズのSD
real<lower=0> sigma_w_alpha; // alphaのシステムノイズのSD
real<lower=0> sigma_w_beta; // betaのシステムノイズのSD
}
transformed parameters {
vector[T] alpha; // 時変切片
vector[T] beta; // 時変係数
// 初期値の設定
alpha[1] = alpha1;
beta[1] = beta1;
// 非中心化パラメータ化による状態方程式
// alpha[t] = alpha[t-1] + alpha_raw[t] * sigma_w_alpha;
// beta[t] = beta[t-1] + beta_raw[t] * sigma_w_beta;
for (t in 2:T) {
alpha[t] = alpha[t-1] + alpha_raw[t] * sigma_w_alpha;
beta[t] = beta[t-1] + beta_raw[t] * sigma_w_beta;
}
}
model {
// 事前分布
alpha_raw ~ std_normal(); // normal(0, 1)と同じ
beta_raw ~ std_normal(); // normal(0, 1)と同じ
// 初期値の事前分布(少し広めの弱情報事前分布)
alpha1 ~ normal(y[1], 100);
beta1 ~ normal(0, 10);
// 標準偏差の事前分布
sigma_v ~ student_t(3, 0, 50);
sigma_w_alpha ~ student_t(3, 0, 5);
sigma_w_beta ~ student_t(3, 0, 1);
// 尤度(観測方程式)
// ベクトル化して効率的に記述
y ~ normal(alpha + beta .* x, sigma_v);
}
"2.4. RStanによるMCMC推定の実行
作成したStanモデルを使って、シミュレーションデータを分析します。
# Stanに渡すデータリストを作成
stan_data <- list(
T = T,
y = sim_data$sales,
x = sim_data$grp
)
# StanモデルのコンパイルとMCMCの実行
fit <- stan(
model_code = model_code,
data = stan_data,
iter = 2000,
warmup = 1000,
chains = 4,
seed = seed
)
# stanfit オブジェクトの保存
setwd(stan_output)
saveRDS(object = fit, file = "stan_fit.rds")以下の警告メッセージが出ます。
警告メッセージ:
1: There were 31 divergent transitions after warmup. See

 mc-stan.org
to find out why this is a problem and how to eliminate them.
2: Examine the pairs() plot to diagnose sampling problems
mc-stan.org
to find out why this is a problem and how to eliminate them.
2: Examine the pairs() plot to diagnose sampling problems2.5. 結果の可視化と解釈
MCMCで得られた事後分布から、時変係数の推定値(中央値と95%信用区間)を抽出し、真の値と比較します。
# stanfit オブジェクトの読み込み
setwd(stan_output)
fit <- readRDS("stan_fit.rds")
# MCMCサンプルを抽出
mcmc_samples <- rstan::extract(fit)
# 推定結果をデータフレームにまとめる
library(dplyr)
result_df <- tidyr::tibble(
time = 1:T,
# alpha(時変切片)の事後統計量
alpha_mean = apply(mcmc_samples$alpha, 2, mean),
alpha_median = apply(mcmc_samples$alpha, 2, median),
alpha_l95 = apply(mcmc_samples$alpha, 2, quantile, probs = 0.025),
alpha_u95 = apply(mcmc_samples$alpha, 2, quantile, probs = 0.975),
# beta(時変係数)の事後統計量
beta_mean = apply(mcmc_samples$beta, 2, mean),
beta_median = apply(mcmc_samples$beta, 2, median),
beta_l95 = apply(mcmc_samples$beta, 2, quantile, probs = 0.025),
beta_u95 = apply(mcmc_samples$beta, 2, quantile, probs = 0.975)
) %>%
# シミュレーションの真の値を結合
left_join(sim_data, by = "time")
# --- 結果のプロット ---
# 1. 時変切片 alpha のプロット
p_alpha <- ggplot(result_df, aes(x = time)) +
geom_ribbon(aes(ymin = alpha_l95, ymax = alpha_u95), fill = "skyblue", alpha = 0.5) +
geom_line(aes(y = alpha_median), color = "dodgerblue", linewidth = 1) +
geom_line(aes(y = alpha_true), color = "black", linetype = "dashed") +
labs(
title = "時変切片 (alpha) の推定結果",
subtitle = "実線: 推定中央値, 網掛け: 95%信用区間, 破線: 真値",
x = "週", y = "基礎売上レベル"
) +
theme_bw() +
theme(plot.subtitle = element_text(size = 9))
# 2. 時変係数 beta のプロット
p_beta <- ggplot(result_df, aes(x = time)) +
geom_ribbon(aes(ymin = beta_l95, ymax = beta_u95), fill = "salmon", alpha = 0.5) +
geom_line(aes(y = beta_median), color = "firebrick", linewidth = 1) +
geom_line(aes(y = beta_true), color = "black", linetype = "dashed") +
geom_vline(xintercept = 30, linetype = "dashed") +
annotate("text", x = 30.5, y = 1.2, label = "競合製品の登場", hjust = 0, size = 4) +
labs(
title = "時変係数 (beta) の推定結果",
subtitle = "実線: 推定中央値, 網掛け: 95%信用区間, 破線: 真値",
x = "週", y = "広告効果(係数)"
) +
theme_bw() +
theme(plot.subtitle = element_text(size = 9))
p_alpha + p_beta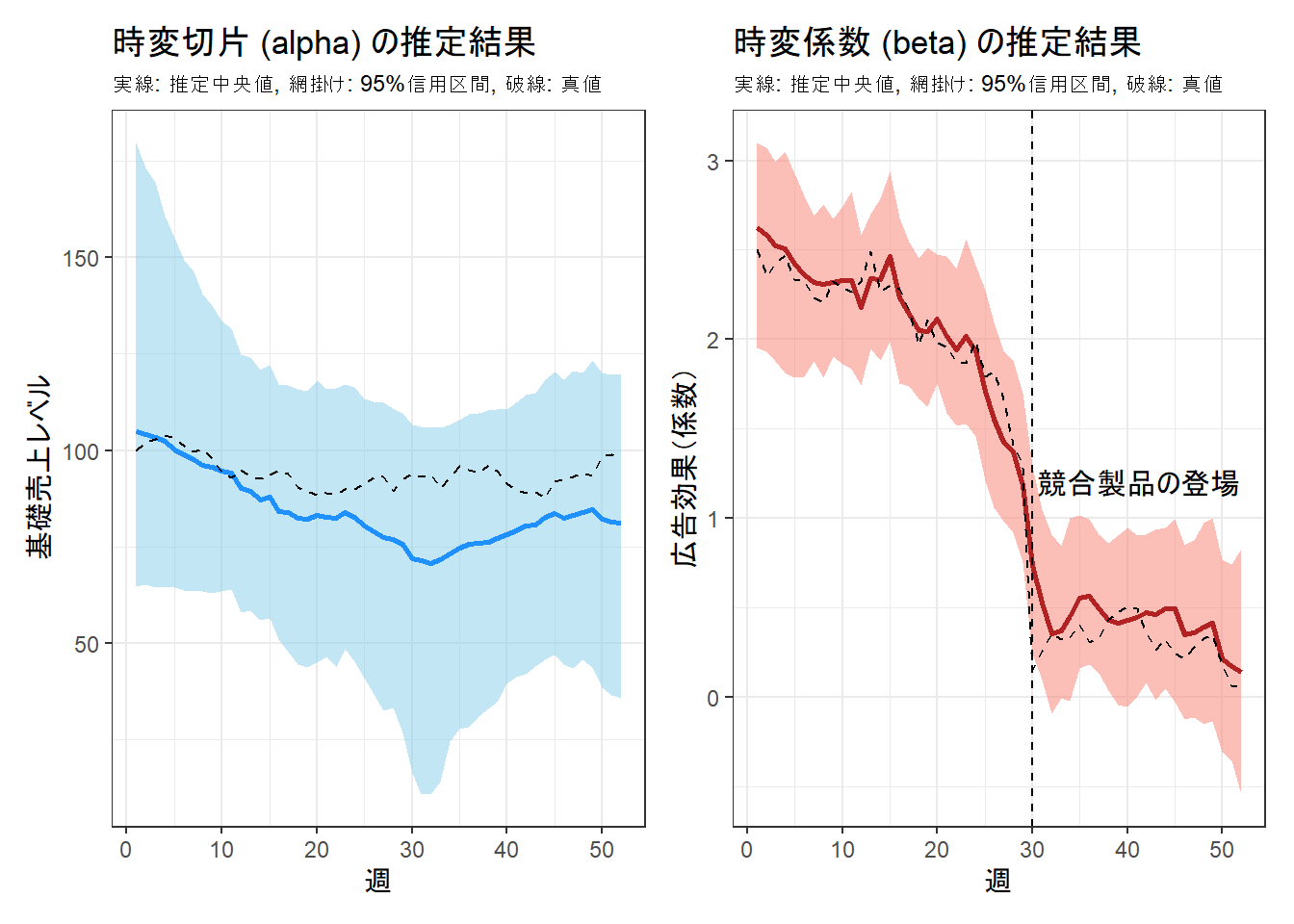
結果の解釈:
- 左のグラフ(alpha): 「推定値の中央値(青い実線)は真の値(黒い破線)をよく追従している」 とは言えない 結果になりました(残念)。なお、真の値は常に95%信用区間(水色の帯)の中には収まっています。
- 右のグラフ(beta): 広告効果のグラフです。モデルは、キャンペーン初期の高い効果、その後の滑らかな摩耗効果、そして30週目の急激な効果の低下という、シナリオ通りの動きを ほぼ 推定できています(競合登場による急落をデータから学習できているようです)。
以上です。

