
関数名: hurst_rs
時系列データの「ハースト指数(Hurst exponent)」を「R/S解析(Rescaled Range Analysis:再スケール範囲解析)」により計算する関数です。
ハースト指数は、時系列データが持つ「長期記憶性(過去の傾向が未来にどう影響するか)」や「フラクタル特性」を測るための指標です。
コードの流れ
- ウィンドウサイズ(区間長)の決定:
ns <- unique(floor(exp(seq(log(min_n), log(n/2), length.out = 20))))データを分割するためのブロックサイズ(m)の配列を作ります。min_n(最小10)からデータ長の半分(n/2)までの値を、対数スケールで等間隔になるように約20個生成しています。
- ブロックごとの計算(R/Sの算出):
設定した各ブロックサイズ m について、データを重複しないように分割し、各ブロックで以下の計算を行います。
- 偏差の累積和:
dev <- cumsum(block - mean(block))- ブロック内の各データから平均を引き、その累積和を求めます。
- 範囲 (Range: R):
R <- max(dev) - min(dev)- 累積和の最大値と最小値の差(範囲)を計算します。
- 標準偏差 (Standard Deviation: S):
S <- sd(block)- ブロック内のデータの標準偏差を計算します。
- 再スケール化範囲:
R / S- 範囲
Rを標準偏差Sで割り、スケールを調整します。
- 平均値の算出:
mean(rs, na.rm = TRUE)同じサイズ m のブロックから得られた R/S の値の平均を求めます。本処理をすべてのウィンドウサイズ ns について行います。
- 両対数グラフ上での線形回帰(ハースト指数の算出):
coef(lm(log(rs_mean[valid]) ~ log(ns[valid])))[2]ブロックサイズ ns(\(x\)軸)と、そのサイズのときの R/S の平均値 rs_mean(\(y\)軸)について、それぞれ自然対数(log)をとって単回帰分析(lm)を行います。この回帰直線の「傾き」がハースト指数となります。
戻り値(ハースト指数 \(H\))の見方
本関数が返す値(傾き)を \(H\) とすると、一般的に以下のように解釈されます。
- \(H \approx 0.5\)(0.5前後):
- ランダムウォーク(ブラウン運動)。過去のデータは未来の動きに影響を与えません。
- \(0.5 < H \le 1\):
- パーシステント(持続的 / 長期記憶性あり)。過去に上昇傾向があれば今後も上昇しやすく、トレンドが継続しやすい性質を示します。
- \(0 \le H < 0.5\):
- アンチパーシステント(平均回帰的)。過去に上昇した後は下降しやすく、ギザギザと平均に戻ろうとする動きが強いことを示します。
Rコード
hurst_rs <- function(x, min_n = 10) {
# 時系列データの長さを取得
n <- length(x)
# 分割するウィンドウ(ブロック)サイズ ns を決定
# 最小サイズ(min_n)からデータの半分(n/2)までの値を、対数スケールで等間隔に約20個作成
ns <- unique(floor(exp(seq(log(min_n), log(n/2), length.out = 20))))
# 各ウィンドウサイズ m に対して R/S の平均値を計算
rs_mean <- sapply(ns, function(m) {
# データをサイズ m で分割したときのブロック数を計算
n_blocks <- floor(n / m)
# 各ブロックごとに R/S を計算
rs <- sapply(1:n_blocks, function(i) {
# i番目のブロックのデータを抽出
block <- x[((i-1)*m + 1):(i*m)]
# 平均からの偏差の累積和を計算
dev <- cumsum(block - mean(block))
# 累積和の最大値と最小値の差(範囲: Range)を計算
R <- max(dev) - min(dev)
# ブロックデータの標準偏差(Standard Deviation)を計算
S <- sd(block)
# Sが0より大きければ R/S を返し、そうでなければ NA(欠損値)とする
if (S > 0) R / S else NA
})
# このウィンドウサイズ m における R/S の平均値を返す
mean(rs, na.rm = TRUE)
})
# NA ではない有効な R/S 平均値のみを抽出
valid <- !is.na(rs_mean)
# 両対数グラフ(log(m) vs log(R/S))上で単回帰分析を行い、
# 回帰直線の傾きをハースト指数として返す
coef(lm(log(rs_mean[valid]) ~ log(ns[valid])))[2]
}実行例
ランダムウォーク、パーシステント(持続的)な時系列およびアンチパーシステント(平均回帰的)な時系列のサンプルデータを作成し、関数が返す結果を比較します。
サンプルデータの作成
R/S解析のアルゴリズムは、関数内で「累積和(cumsum)」を取る仕様になっています。
そのため、入力するデータは「価格」や「位置」そのものではなく、「変化量(リターンや増分)」とするのが適切です。
library(ggplot2)
seed <- 20260420
set.seed(seed) # 結果の再現性のために乱数シードを固定
n_len <- 5000 # データ数(サンプルサイズ)
# ランダムウォーク(の増分=ホワイトノイズ)
# 過去の影響を全く受けない独立した正規乱数
ts_random <- rnorm(n_len)
# パーシステント(持続的)な時系列
# 過去の変動と同じ方向へ動きやすい(強い正の自己相関を持つ)
# ※ここではAR(1)モデルを使用して疑似的にトレンド傾向を作成
ts_persistent <- arima.sim(model = list(ar = 0.9), n = n_len)
# アンチパーシステント(平均回帰的)な時系列
# 過去の変動と逆の方向へ動きやすい(強い負の自己相関を持つ)
# ※ここではAR(1)モデルを使用して疑似的にギザギザな傾向を作成
ts_anti_persistent <- arima.sim(model = list(ar = -0.9), n = n_len)
# 視認性を良くするため、最初の500データポイントを抽出してデータフレームを作成
plot_len <- 500
# ggplotで扱いやすい「縦持ち(Long形式)」のデータフレームを作成
plot_df <- data.frame(
Time = rep(1:plot_len, 3),
Value = c(ts_random[1:plot_len],
ts_persistent[1:plot_len],
ts_anti_persistent[1:plot_len]),
Type = factor(rep(c("1. Random",
"2. Persistent",
"3. Anti-Persistent"),
each = plot_len))
)
# ggplot2による作図
g <- ggplot(plot_df, aes(x = Time, y = Value, color = Type)) +
geom_line(alpha = 0.8) +
# facet_grid を使って縦に3つのグラフを並べる(y軸のスケールはそれぞれ最適化)
facet_grid(Type ~ ., scales = "free_y") +
theme_minimal() +
labs(title = "3種類の時系列データ(増分)の比較",
subtitle = "各時系列の特性による波形の違い(最初の500ステップ)",
x = "Time",
y = "Value") +
theme(legend.position = "none", # ファセットで名前が出るので凡例は隠す
strip.text = element_text(size = 10, face = "bold"), # タイトルラベルを太字にして見やすく
strip.background = element_rect(fill = "#f0f0f0", color = NA))
# プロットの表示
print(g)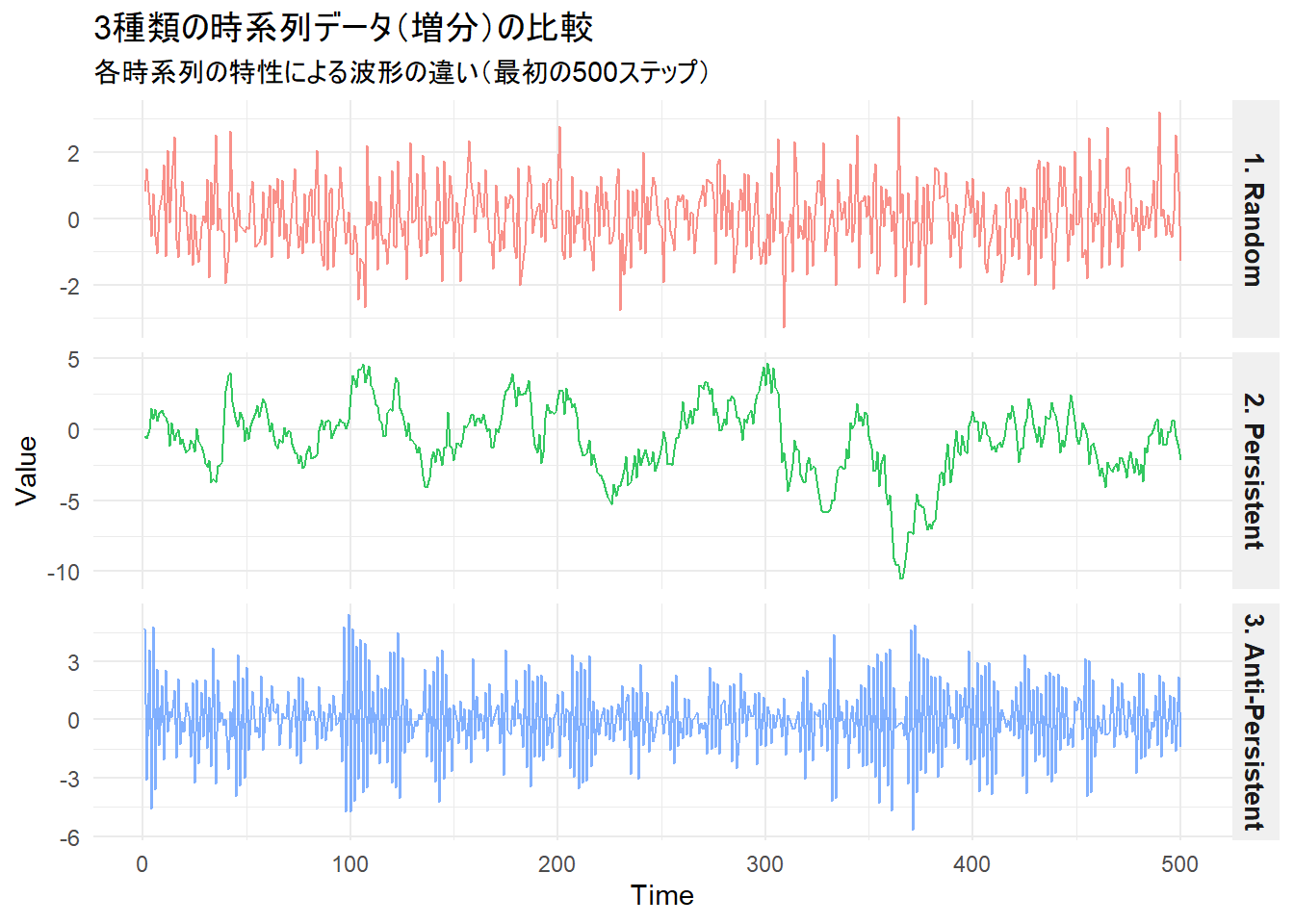
結果の比較
# hurst_rs によるハースと指数の算出
h_random <- hurst_rs(ts_random)
h_pers <- hurst_rs(ts_persistent)
h_anti <- hurst_rs(ts_anti_persistent)
# 結果の出力
cat("=== ハースト指数 (H) の計算結果 ===\n")
cat(sprintf("1. ランダム (期待値 ≒ 0.5) : %.4f\n", h_random))
cat(sprintf("2. パーシステント (期待値 > 0.5) : %.4f\n", h_pers))
cat(sprintf("3. アンチパーシステント (期待値 < 0.5) : %.4f\n", h_anti))=== ハースト指数 (H) の計算結果 ===
1. ランダム (期待値 ≒ 0.5) : 0.5929
2. パーシステント (期待値 > 0.5) : 0.7722
3. アンチパーシステント (期待値 < 0.5) : 0.3706ランダム(結果:0.5929)
- 基準となる
0.5に近い値となっています。 - これはコイントスのように「過去のデータが未来に一切影響を与えない」完全なランダム(ホワイトノイズ)であることを示しています。
- 理論上の完全な値は
0.5ですが、現実のデータ(有限のデータ数や、R/S解析という計算手法によるバイアス)では少し上振れ・下振れすることがあります。0.59という数値は、他の2つと比較して「中間である」ことを示しています。
パーシステント(結果:0.7722)
- 基準の
0.5を上回っています(\(0.5 < H \le 1\) の範囲)。 - 「持続性(長期記憶性)」が強いことを示しています。つまり、「直近でプラスの動き(上昇)が続いていれば、次もプラスになりやすい」というトレンドが継続しやすい性質を持っています。
アンチパーシステント(結果:0.3706)
- 基準の
0.5を下回っています(\(0 \le H < 0.5\) の範囲)。 - 「反転性(平均回帰性)」が強いことを示しています。これは、「直近でプラスの動き(上昇)をしたら、次はマイナスの動き(下降)になりやすい」という、元の位置に戻ろうとする性質です。 グラフで見た際の、ノコギリのような非常に細かくギザギザした波形の原因が、この
0.3706という低いハースト指数に表れています。
以上です。

