
Rでピアソンの経験則(Pearson’s skewness approximation)をシミュレーションします。
ピアソンの経験則とは
ピアソンの経験則とは、平均値と最頻値が既知かつ、分布がある程度単峰・対称に近いことを条件とした中央値の近似式です。
\[\text{中央値} \approx \text{平均} - \frac{1}{3}(\text{平均} - \text{最頻値})\]
シミュレーション
- n = 100,000 の Monte Carlo シミュレーションにより、5つの分布(正規分布、指数分布、ガンマ分布、ベータ分布および対数正規分布)それぞれの平均値と最頻値(mode)から中央値を予測し、実際の中央値との差を相対誤差(絶対誤差(予測中央値 - 実際の中央値) / 実際の中央値(%))により比較します。
分布の生成と相対誤差の比較
# ============================================================
# ピアソンの経験則シミュレーション
# 公式: 中央値 ≈ 平均 - (1/3)(平均 - 最頻値)
# n = 100,000 の Monte Carlo シミュレーション
# ============================================================
seed <- 20260703
set.seed(seed)
n_sim <- 100000
# ------------------------------------------------------------
# 分布の定義
# ------------------------------------------------------------
dists <- list(
list(
name = "正規分布",
gen = function() rnorm(n_sim, mean = 50, sd = 10),
mode = 50 # 正規分布: 最頻値 = 平均
),
list(
name = "指数分布",
gen = function() rexp(n_sim, rate = 0.1),
mode = 0 # 指数分布: 最頻値 = 0
),
list(
name = "ガンマ分布 (shape=3, rate=0.3)",
gen = function() rgamma(n_sim, shape = 3, rate = 0.3),
mode = (3 - 1) / 0.3 # ガンマ分布: (shape-1)/rate
),
list(
name = "ベータ分布 (a=5, b=2) × 100",
gen = function() rbeta(n_sim, shape1 = 5, shape2 = 2) * 100,
mode = (5 - 1) / (5 + 2 - 2) * 100 # ベータ分布: (a-1)/(a+b-2)
),
list(
name = "対数正規分布 (meanlog=3, sdlog=0.5)",
gen = function() rlnorm(n_sim, meanlog = 3, sdlog = 0.5),
mode = exp(3 - 0.5^2) # 対数正規分布: exp(mu - sigma^2)
)
)
# ------------------------------------------------------------
# シミュレーション実行
# ------------------------------------------------------------
cat("============================================================\n")
cat("ピアソンの経験則シミュレーション結果 (n =", n_sim, ")\n")
cat("============================================================\n\n")
results <- data.frame()
for (d in dists) {
x <- d$gen()
mn <- mean(x)
md <- median(x)
mo <- d$mode
pred <- mn - (1 / 3) * (mn - mo) # ピアソンの経験則
sk <- mean((x - mn)^3) / sd(x)^3 # 歪度(モーメント法)
err <- pred - md # 絶対誤差
rel <- err / md * 100 # 相対誤差 (%)
results <- rbind(results, data.frame(
分布 = d$name,
歪度 = round(sk, 3),
平均値 = round(mn, 3),
最頻値 = round(mo, 3),
実中央値 = round(md, 3),
予測中央値 = round(pred, 3),
絶対誤差 = round(err, 4),
相対誤差_pct = round(rel, 4)
))
}
print(results, row.names = FALSE)============================================================
ピアソンの経験則シミュレーション結果 (n = 1e+05 )
============================================================
分布 歪度 平均値 最頻値 実中央値 予測中央値 絶対誤差 相対誤差_pct
正規分布 -0.008 50.029 50.000 50.029 50.019 -0.0104 -0.0208
指数分布 1.972 10.015 0.000 6.936 6.677 -0.2590 -3.7348
ガンマ分布 (shape=3, rate=0.3) 1.151 9.991 6.667 8.910 8.883 -0.0274 -0.3075
ベータ分布 (a=5, b=2) × 100 -0.597 71.465 80.000 73.679 74.310 0.6307 0.8559
対数正規分布 (meanlog=3, sdlog=0.5) 1.686 22.687 15.643 20.064 20.339 0.2754 1.3726正規分布(歪度 ≈ −0.008)|相対誤差 −0.02%
- 正規分布は定義上、平均値・中央値・最頻値がすべて一致する完全対称な分布です。
- 歪度はサンプリング誤差により厳密にはゼロになりませんが、−0.008 という値はほぼゼロとみなせます。
- 予測中央値(50.019)と実際の中央値(50.029)の差はわずかで、経験則は機能しています。
- これは「経験則の理想条件」そのものです。
指数分布(歪度 ≈ 1.972)|相対誤差 −3.73%
- 5分布中で最も誤差が大きい結果となりました。
- 主な原因は最頻値が 0 という境界値に位置することです。
- 実際の中央値は 6.936 であるのに対し、予測値は 6.677 と下方に外れています。
- 歪度も約 2.0 と大きく、経験則の適用範囲(中程度の歪み)を超えています。
- 指数分布のように最頻値が定義域の端点に張り付く分布では、経験則の前提が成立しないことが数値で確認できます。
ガンマ分布・shape=3(歪度 ≈ 1.151)|相対誤差 −0.31%
- 指数分布と同じ右歪みでも、shape パラメータが 3 になることで最頻値が内部(6.667)に存在し、経験則がよく機能しています。
- 相対誤差はわずか −0.31% と良好です。
- 歪度が約 1.15 という「中程度の右歪み」の範囲に収まっていることが精度の高さにつながっています。
ベータ分布・a=5, b=2(歪度 ≈ −0.597)|相対誤差 +0.86%
- 唯一の左歪み分布です。
- 最頻値(80.0)が右端付近にあり、平均値(71.465)・中央値(73.679)・最頻値(80.0)の順番が右歪みとは逆になっています。
- 経験則はこの「逆順」にも対応しており、相対誤差 +0.86% と良好な精度を示しています。
- 絶対誤差の符号がプラス(予測が実際より大きい)になっている点も、左歪み特有の挙動として整合的です。
対数正規分布(歪度 ≈ 1.686)|相対誤差 +1.37%
- 歪度 1.686 という強めの右歪みながら、相対誤差は 1.37% と許容範囲内に収まりました。
- 最頻値(15.643)が分布内部に明確に存在することが、経験則の精度を保つ要因になっています。
- また絶対誤差の符号がプラス(予測値が実際より大きい)となっており、強い右歪みを持つ分布では予測が中央値をやや過大評価する傾向があることが読み取れます。
結果の整理
| 条件 | 該当分布 | 精度 |
|---|---|---|
| 歪度 ≈ 0(対称分布) | 正規分布 | ◎ 非常に良好 |
| 歪度が中程度・最頻値が内部 | ガンマ分布、ベータ分布、対数正規 | ○ 良好〜中程度 |
| 歪度が大・最頻値が境界値 | 指数分布 | △ 注意が必要 |
- 精度を左右する要因は歪度の大きさだけではなく、最頻値が定義域の内部に存在するか否かが重要なポイントです。
- 指数分布の誤差が突出して大きい理由はまさにここにあり、「単峰かつ最頻値が内部にある分布」という前提条件がピアソンの経験則の有効範囲を規定していることを、今回のシミュレーションで定量的に確認できました。
なお、「最頻値が内部にある分布」とは、定義域の端点(境界)に最頻値がないということです。
| 分布 | 定義域 | 最頻値の位置 |
|---|---|---|
| 正規分布 | \((-\infty, \infty)\) | 内部(端点なし) |
| ガンマ(shape>1) | \([0, \infty)\) | 内部(\(>0\)) |
| 対数正規 | \((0, \infty)\) | 内部(\(>0\)) |
| 指数分布 | \([0, \infty)\) | 境界(\(=0\)) |
結果の可視化
# ============================================================
# ピアソンの経験則シミュレーション:5分布の可視化
# ggplot2 による密度プロット
# ============================================================
library(ggplot2)
library(dplyr)
library(tidyr)
# ------------------------------------------------------------
# データ生成 & 統計量計算
# ------------------------------------------------------------
samples_list <- list()
vlines_list <- list()
for (d in dists) {
x <- d$gen()
mn <- mean(x)
md <- median(x)
mo <- d$mode
pred <- mn - (1 / 3) * (mn - mo)
sk <- mean((x - mn)^3) / sd(x)^3
rel <- (pred - md) / md * 100
label <- sprintf(
"歪度: %.3f\n相対誤差: %+.2f%%",
sk, rel
)
samples_list[[d$name]] <- data.frame(x = x, dist = d$name)
vlines_list[[d$name]] <- data.frame(
dist = d$name,
xintercept = c(mn, md, mo, pred),
stat = factor(
c("平均値", "実際の中央値", "最頻値", "ピアソン予測"),
levels = c("平均値", "最頻値", "実際の中央値", "ピアソン予測")
),
label = label
)
}
df_samples <- bind_rows(samples_list)
df_vlines <- bind_rows(vlines_list)
# facet の表示順を固定
dist_order <- sapply(dists, `[[`, "name")
df_samples$dist <- factor(df_samples$dist, levels = dist_order)
df_vlines$dist <- factor(df_vlines$dist, levels = dist_order)
# ラベル用(各パネル右上に歪度・相対誤差を表示)
df_labels <- df_vlines |>
group_by(dist) |>
slice(1) |>
ungroup() |>
select(dist, label)
# ------------------------------------------------------------
# 配色・線種・線幅の定義
# ------------------------------------------------------------
line_colors <- c(
"平均値" = "orange",
"最頻値" = "green",
"実際の中央値" = "blue",
"ピアソン予測" = "red"
)
line_types <- c(
"平均値" = "dashed",
"最頻値" = "dashed",
"実際の中央値" = "solid",
"ピアソン予測" = "dotted"
)
line_widths <- c(
"平均値" = 1.0,
"最頻値" = 1.0,
"実際の中央値" = 1.2,
"ピアソン予測" = 1.2
)
# ------------------------------------------------------------
# line_types・line_widths から凡例用ベクトルを動的生成
# override.aes の順序は factor levels に合わせる
# ------------------------------------------------------------
legend_levels <- levels(df_vlines$stat)
legend_linetypes <- unname(line_types[legend_levels])
legend_linewidths <- unname(line_widths[legend_levels])
# geom_vline を linewidth の値ごとにグループ化して描画
unique_widths <- unique(line_widths)
geom_vline_layers <- lapply(unique_widths, function(w) {
stats_w <- names(line_widths)[line_widths == w]
geom_vline(
data = df_vlines[df_vlines$stat %in% stats_w, ],
aes(xintercept = xintercept, color = stat, linetype = stat),
linewidth = w
)
})
# ------------------------------------------------------------
# プロット
# ------------------------------------------------------------
p <- ggplot(df_samples, aes(x = x)) +
# 密度曲線
geom_density(
fill = "#2a78d6",
alpha = 0.12,
color = "#2a78d6",
linewidth = 0.5
) +
# 縦線(linewidth ごとに分割したレイヤーを追加)
geom_vline_layers +
# 歪度・相対誤差のラベル(右上)
geom_text(
data = df_labels,
aes(label = label),
x = Inf, y = Inf,
hjust = 1.08, vjust = 1.5,
size = 3, color = "#52514e",
inherit.aes = FALSE,
lineheight = 1.3
) +
# スケール(override.aes を line_types・line_widths から動的参照)
scale_color_manual(
name = NULL,
values = line_colors,
guide = guide_legend(
override.aes = list(
linetype = legend_linetypes,
linewidth = legend_linewidths
)
)
) +
scale_linetype_manual(name = NULL, values = line_types, guide = "none") +
# ファセット(分布ごとに独立した x 軸)
facet_wrap(~dist, scales = "free", ncol = 2) +
# 軸ラベル
labs(
title = "ピアソンの経験則:5分布における中央値の予測",
subtitle = "密度曲線と各統計量の位置(n = 100,000)",
x = "値",
y = "密度",
caption = "ピアソン予測:中央値 ≈ 平均値 − (1/3)(平均値 − 最頻値)"
) +
# テーマ
theme_minimal(base_size = 12) +
theme(
plot.title = element_text(
size = 14, face = "bold",
margin = margin(b = 4)
),
plot.subtitle = element_text(
size = 11, color = "#52514e",
margin = margin(b = 12)
),
plot.caption = element_text(
size = 9, color = "#52514e",
hjust = 0
),
strip.text = element_text(
size = 10, face = "bold",
lineheight = 1.2
),
legend.position = "bottom",
legend.text = element_text(size = 10),
legend.key.width = unit(1.8, "cm"),
panel.grid.minor = element_blank(),
panel.grid.major = element_line(color = "#e8e7e1"),
axis.text = element_text(size = 9, color = "#52514e"),
axis.title = element_text(size = 10, color = "#52514e"),
plot.margin = margin(12, 16, 12, 16)
)
p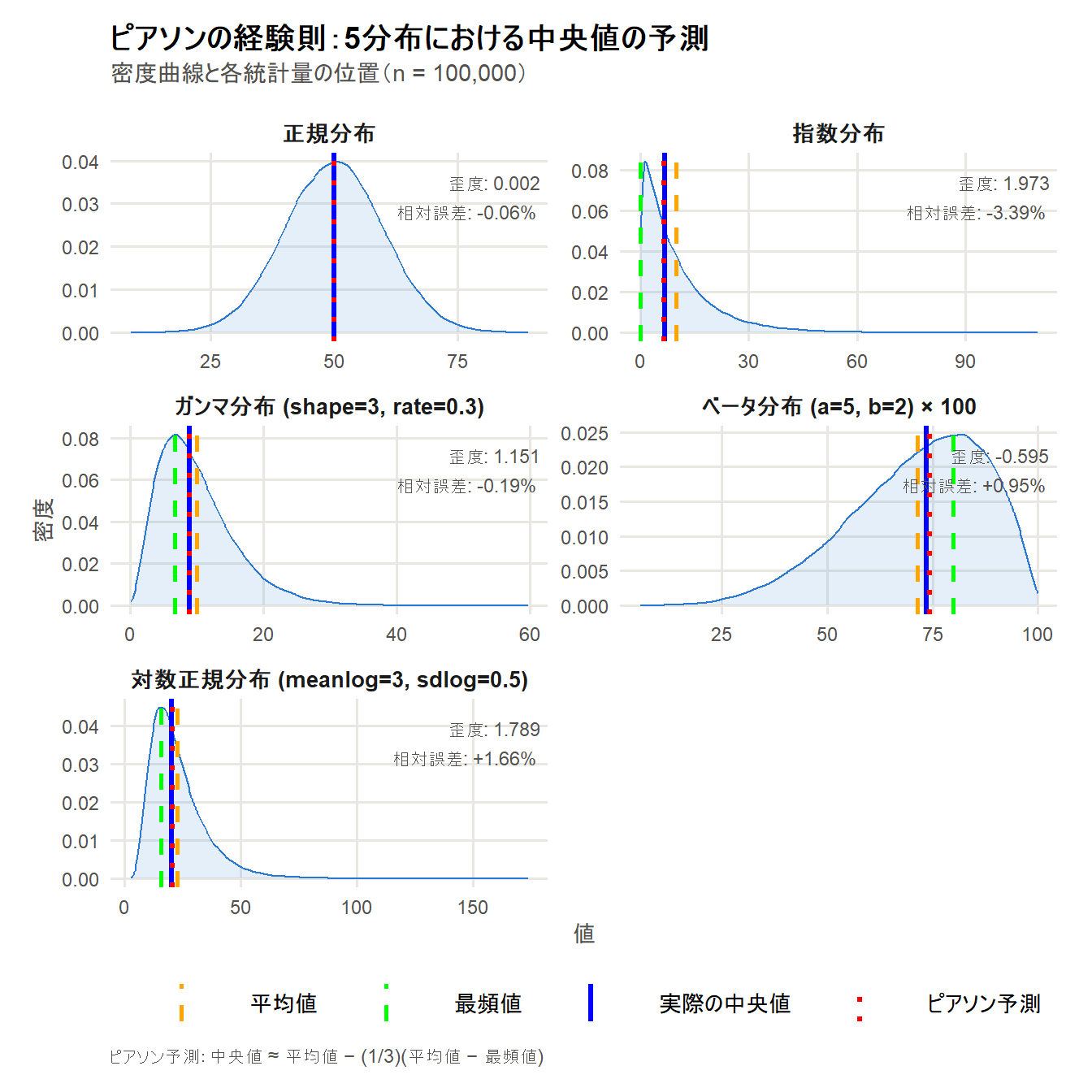
以上です。
