
Rで比推定をシミュレーションします。
比推定とは
比推定は、補助変数(auxiliary variable)との比を利用して、母集団の平均や総計をより精度よく推定する手法です。
基本的な考え方
母集団において、関心のある変数 \(y\) と、既知の補助変数 \(x\) が強い相関を持つとき、その比
\[R = \frac{\mu_y}{\mu_x} = \frac{\bar{Y}}{\bar{X}}\]
を標本から推定し、母集団の既知情報 \(\mu_x\)(または総計 \(X\))を活用して \(\mu_y\) を推定します。
比推定量
標本から得られた比の推定量:
\[\hat{R} = \frac{\bar{y}}{\bar{x}}\]
これを用いた比推定量(ratio estimator):
\[\hat{\mu}_y^R = \hat{R} \cdot \mu_x = \frac{\bar{y}}{\bar{x}} \cdot \mu_x\]
母総計の推定:
\[\hat{Y}^R = \hat{R} \cdot X = \frac{\bar{y}}{\bar{x}} \cdot X\]
分散と近似偏り
比推定量はわずかに偏り(bias)を持ちます。テイラー展開による一次近似では:
\[\text{Bias}(\hat{R}) \approx \frac{1}{\mu_x}\left( R \cdot V(\bar{x}) - \text{Cov}(\bar{y}, \bar{x}) \right)\]
分散の近似式(単純無作為抽出の場合):
\[V(\hat{\mu}_y^R) \approx \frac{1-f}{n} \cdot \frac{1}{N-1} \sum_{i=1}^N (y_i - R x_i)^2\]
ここで \(f = n/N\) は標本比率(有限母集団修正)。
単純推定との比較
| 特性 | 単純推定 \(\bar{y}\) | 比推定 \(\hat{\mu}_y^R\) |
|---|---|---|
| 不偏性 | 不偏 | 近似的に不偏 |
| 分散 | \(\frac{1-f}{n} S_y^2\) | \(\frac{1-f}{n}(S_y^2 + R^2 S_x^2 - 2R S_{xy})\) |
| 有効性 | 常に使える | \(\rho_{xy} > \dfrac{R \cdot C_x}{2C_y}\) のとき有利 |
\(C_x, C_y\) は変動係数、\(\rho_{xy}\) は相関係数。
実用的な目安: \(x\) と \(y\) の相関が \(\rho > \dfrac{R \cdot C_x}{2C_y}\) を超えれば比推定が有利になります。\(R \approx 1\) かつ \(C_x \approx C_y\) のような典型的な状況では \(\rho > 0.5\) 程度が目安ですが、\(R\) が 1 から大きく外れる場合は閾値も変化します。
具体例
農業調査:今年の収穫量 \(y\) を推定したいが、昨年の収穫量 \(x\) は農場ごとに既知。両者に強い相関があるため比推定が有効。
企業調査:売上 \(y\) の推定に、従業員数 \(x\)(既知)を補助変数として活用。
関連手法
- 積推定(Product estimator):\(y\) と \(x\) が負の相関を持つ場合に有効
- 回帰推定(Regression estimator):比推定を一般化したもの。\(\hat{\mu}_y^{reg} = \bar{y} + \hat{\beta}(\mu_x - \bar{x})\)。比推定は切片なし回帰の特殊ケース
- 層別比推定:層ごとに比推定を行い合成する
比推定は、国勢調査・農業センサス・経済統計など公的統計調査で広く使われる基本的な推定手法です。
比推定(Ratio Estimation)シミュレーション
- 目的:
- 母集団を人工的に生成し、比推定量の性質を確認する
- 単純平均推定と比推定の分散・偏りを比較する
- 相関係数と推定効率の関係を可視化する
パート1:母集団の生成
- 農場の収穫量を想定した人工データを作成します。補助変数 \(x\)(昨年収穫量)と目標変数 \(y\)(今年収穫量)を \(y = Rx + \varepsilon\) で生成し、真の比 \(R = 1.2\) を設定します。
library(ggplot2)
library(dplyr)
library(tidyr)
library(patchwork)
seed <- 20260627
set.seed(seed)
N <- 1000 # 母集団サイズ
n <- 50 # 標本サイズ
# 補助変数 x(昨年の収穫量、kg)
x_pop <- rgamma(N, shape = 5, rate = 0.05) # 平均100kg程度
# y = R*x + ε (真の比 R = 1.2、つまり今年は2割増し)
R_true <- 1.2
sigma_e <- 15 # 誤差の標準偏差
y_pop <- R_true * x_pop + rnorm(N, 0, sigma_e)
y_pop <- pmax(y_pop, 0) # 負値を除去
# 母集団パラメータ
mu_x <- mean(x_pop) # x の母平均(既知と仮定)
mu_y <- mean(y_pop) # y の母平均(推定対象)
R_pop <- mu_y / mu_x # 真の比
cat("===== 母集団パラメータ =====\n")
cat(sprintf("母平均 μ_x = %.4f\n", mu_x))
cat(sprintf("母平均 μ_y = %.4f\n", mu_y))
cat(sprintf("真の比 R = μ_y/μ_x = %.4f\n", R_pop))
cat(sprintf("x と y の相関係数 ρ = %.4f\n", cor(x_pop, y_pop)))
cat("\n")===== 母集団パラメータ =====
母平均 μ_x = 100.4277
母平均 μ_y = 120.1613
真の比 R = μ_y/μ_x = 1.1965
x と y の相関係数 ρ = 0.9636パート2:モンテカルロシミュレーション(B=5000回)
- 毎回 \(n=50\) の標本を抽出し、単純推定と比推定の両方を計算。偏り・分散・RMSEを比較し、相対効率を出力します。
set.seed(seed)
B <- 5000 # シミュレーション回数
results <- replicate(B,
{
# 単純無作為抽出
idx <- sample(N, n, replace = FALSE)
xs <- x_pop[idx]
ys <- y_pop[idx]
# 単純平均推定
est_simple <- mean(ys)
# 比推定
R_hat <- mean(ys) / mean(xs)
est_ratio <- R_hat * mu_x
c(simple = est_simple, ratio = est_ratio, R_hat = R_hat)
},
simplify = TRUE
)
df_sim <- as.data.frame(t(results))
# 集計
cat("===== シミュレーション結果(B =", B, "回)=====\n")
cat("\n【単純推定】\n")
cat(sprintf(" 平均(期待値) = %.4f\n", mean(df_sim$simple)))
cat(sprintf(" 偏り(Bias) = %.4f\n", mean(df_sim$simple) - mu_y))
cat(sprintf(" 分散 = %.4f\n", var(df_sim$simple)))
cat(sprintf(" RMSE = %.4f\n", sqrt(mean((df_sim$simple - mu_y)^2))))
cat("\n【比推定】\n")
cat(sprintf(" 平均(期待値) = %.4f\n", mean(df_sim$ratio)))
cat(sprintf(" 偏り(Bias) = %.4f\n", mean(df_sim$ratio) - mu_y))
cat(sprintf(" 分散 = %.4f\n", var(df_sim$ratio)))
cat(sprintf(" RMSE = %.4f\n", sqrt(mean((df_sim$ratio - mu_y)^2))))
eff <- var(df_sim$simple) / var(df_sim$ratio)
cat(sprintf("\n相対効率(単純分散/比推定分散)= %.4f\n", eff))
cat("(>1 なら比推定が効率的)\n\n")===== シミュレーション結果(B = 5000 回)=====
【単純推定】
平均(期待値) = 120.1439
偏り(Bias) = -0.0174
分散 = 64.3851
RMSE = 8.0233
【比推定】
平均(期待値) = 120.1587
偏り(Bias) = -0.0027
分散 = 4.7665
RMSE = 2.1830
相対効率(単純分散/比推定分散)= 13.5079
(>1 なら比推定が効率的)パート3:理論値との照合
- 比推定の分散の理論近似式 \(V(\hat{\mu}_y^R) \approx \frac{1-f}{n}(S_y^2 + R^2 S_x^2 - 2RS_{xy})\) とシミュレーション値を並べて確認します。
S2_y <- var(y_pop)
S2_x <- var(x_pop)
S_xy <- cov(x_pop, y_pop)
f <- n / N
V_simple_theory <- (1 - f) / n * S2_y
V_ratio_theory <- (1 - f) / n * (S2_y + R_pop^2 * S2_x - 2 * R_pop * S_xy)
cat("===== 理論値との比較 =====\n")
cat(sprintf(
"単純推定の理論分散 = %.4f(シミュレーション: %.4f)\n",
V_simple_theory, var(df_sim$simple)
))
cat(sprintf(
"比推定の理論分散 = %.4f(シミュレーション: %.4f)\n",
V_ratio_theory, var(df_sim$ratio)
))
cat("\n")===== 理論値との比較 =====
単純推定の理論分散 = 64.2468(シミュレーション: 64.3851)
比推定の理論分散 = 4.5871(シミュレーション: 4.7665)パート4:相関係数と効率性の理論曲線
- \(\rho\) を −0.99 〜 +0.99 で変化させて相対効率を計算し、比推定が有利になる閾値 \(\rho > R \cdot C_x / (2C_y)\) を可視化します。
rho_seq <- seq(-0.99, 0.99, by = 0.01)
Cy <- sqrt(S2_y) / mu_y # y の変動係数
Cx <- sqrt(S2_x) / mu_x # x の変動係数
# 理論上の相対効率:V(単純) / V(比推定)
# = S_y^2 / (S_y^2 + R^2*S_x^2 - 2*R*S_xy)
# = 1 / (1 + (R*Cx/Cy)^2 - 2*ρ*R*Cx/Cy)
# 比推定が有利になる条件(相対効率 > 1 となる ρ の閾値):
# ρ > R*Cx / (2*Cy)
threshold_rho <- R_pop * Cx / (2 * Cy)
eff_theory <- 1 / (1 + (R_pop * Cx / Cy)^2 - 2 * rho_seq * R_pop * Cx / Cy)
df_eff <- data.frame(rho = rho_seq, efficiency = eff_theory)
cat("===== 効率性の条件 =====\n")
cat(sprintf("変動係数 Cx = %.4f, Cy = %.4f\n", Cx, Cy))
cat(sprintf("比推定が有利になる相関の閾値 ρ > R*Cx/(2*Cy) = %.4f\n", threshold_rho))
cat(sprintf(
"今回の相関係数 ρ = %.4f → %s\n",
cor(x_pop, y_pop),
ifelse(cor(x_pop, y_pop) > threshold_rho, "比推定が有利 ✓", "単純推定が有利")
))===== 効率性の条件 =====
変動係数 Cx = 0.4643, Cy = 0.4839
比推定が有利になる相関の閾値 ρ > R*Cx/(2*Cy) = 0.5740
今回の相関係数 ρ = 0.9636 → 比推定が有利 ✓パート5:可視化
# --- 図1: 母集団の散布図 ---
df_pop <- data.frame(x = x_pop, y = y_pop)
p1 <- ggplot(df_pop[sample(N, 300), ], aes(x = x, y = y)) +
geom_point(alpha = 0.4, color = "#2c7bb6", size = 1.5) +
geom_abline(
slope = R_pop, intercept = 0,
color = "#d7191c", linewidth = 1, linetype = "dashed"
) +
labs(
title = "母集団:x と y の関係",
subtitle = sprintf("真の比 R = %.3f(赤点線:y = R·x)", R_pop),
x = "補助変数 x(昨年収穫量 kg)",
y = "目標変数 y(今年収穫量 kg)"
) +
theme_bw() +
theme(plot.title = element_text(size = 13, face = "bold"), plot.subtitle = element_text(size = 9))
# --- 図2: 推定量の分布比較(ヒストグラム)---
df_long <- df_sim |>
select(simple, ratio) |>
pivot_longer(everything(),
names_to = "method",
values_to = "estimate"
) |>
mutate(method = recode(method,
simple = "単純推定",
ratio = "比推定"
))
p2 <- ggplot(df_long, aes(x = estimate, fill = method)) +
geom_histogram(aes(y = after_stat(density)),
bins = 60, alpha = 0.6, position = "identity"
) +
geom_vline(
xintercept = mu_y, color = "black",
linewidth = 1.2, linetype = "solid"
) +
scale_fill_manual(values = c(
"単純推定" = "#fc8d59",
"比推定" = "#2c7bb6"
)) +
labs(
title = "推定量の標本分布",
subtitle = sprintf("黒線:真の母平均 μ_y = %.2f", mu_y),
x = "推定値", y = "密度", fill = "推定法"
) +
theme_bw() +
theme(
plot.title = element_text(size = 13, face = "bold"), plot.subtitle = element_text(size = 9),
legend.position = "top"
)
# --- 図3: 相対効率 vs 相関係数 ---
p3 <- ggplot(df_eff, aes(x = rho, y = efficiency)) +
geom_line(color = "#1a9641", linewidth = 1.2) +
geom_hline(
yintercept = 1, linetype = "dashed",
color = "gray40", linewidth = 0.8
) +
geom_vline(
xintercept = threshold_rho,
color = "#d7191c", linetype = "dotted", linewidth = 1
) +
geom_vline(
xintercept = cor(x_pop, y_pop),
color = "#2c7bb6", linetype = "solid", linewidth = 1
) +
annotate("text",
x = threshold_rho - 0.35, y = 2,
label = sprintf("閾値\nρ=%.2f", threshold_rho),
color = "#d7191c", size = 3.0, hjust = 0
) +
annotate("text",
x = cor(x_pop, y_pop) - 0.35,
y = 0.4,
label = sprintf("今回\nρ=%.2f", cor(x_pop, y_pop)),
color = "#2c7bb6", size = 3.0, hjust = 0
) +
coord_cartesian(ylim = c(0, 5)) +
labs(
title = "相関係数と比推定の相対効率",
subtitle = "相対効率 = Var(単純推定) / Var(比推定) >1 なら比推定が有利",
x = "相関係数 ρ(x, y)",
y = "相対効率"
) +
theme_bw() +
theme(plot.title = element_text(size = 13, face = "bold"), plot.subtitle = element_text(size = 9))
# --- 図4: 標本サイズと推定精度(RMSE)の比較 ---
n_seq <- seq(10, 600, by = 10)
rmse_df <- lapply(n_seq, function(ni) {
sims <- replicate(2000, {
idx <- sample(N, ni, replace = FALSE)
xs <- x_pop[idx]
ys <- y_pop[idx]
c(
simple = mean(ys),
ratio = mean(ys) / mean(xs) * mu_x
)
})
data.frame(
n = ni,
method = c("単純推定", "比推定"),
rmse = c(
sqrt(mean((sims["simple", ] - mu_y)^2)),
sqrt(mean((sims["ratio", ] - mu_y)^2))
)
)
}) |> bind_rows()
p4 <- ggplot(rmse_df, aes(x = n, y = rmse, color = method)) +
geom_line(linewidth = 1.1) +
geom_point(size = 1.5) +
scale_color_manual(values = c(
"単純推定" = "#fc8d59",
"比推定" = "#2c7bb6"
)) +
labs(
title = "標本サイズと推定精度(RMSE)",
subtitle = "標本サイズが小さいほど比推定の優位性が顕著",
x = "標本サイズ n",
y = "RMSE(二乗平均誤差の平方根)",
color = "推定法"
) +
theme_bw() +
theme(
plot.title = element_text(size = 13, face = "bold"), plot.subtitle = element_text(size = 9),
legend.position = "top"
)
# --- 統合出力 ---
combined <- (p1 + p2) / (p3 + p4) +
plot_annotation(
title = "比推定(Ratio Estimation)シミュレーション",
subtitle = sprintf(
"母集団サイズ N=%d 標本サイズ n=%d シミュレーション回数 B=%d",
N, n, B
),
theme = theme(
plot.title = element_text(size = 16, face = "bold"),
plot.subtitle = element_text(size = 11, color = "gray40")
)
)
combined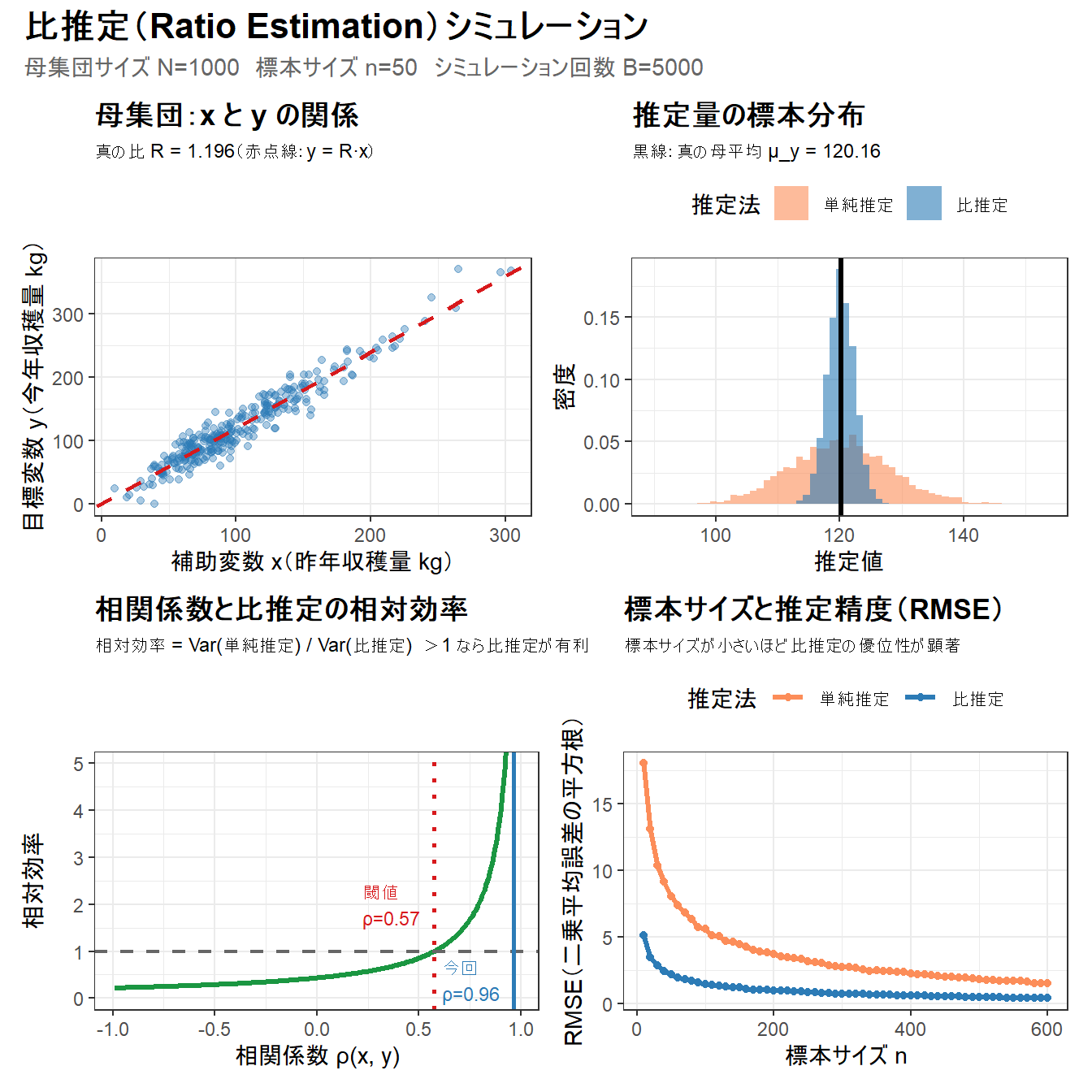
以上です。
