
Toda-Yamamoto法 とは
時系列分析におけるToda-Yamamoto法は、系列が非定常(単位根を持つ和分過程)であっても、あるいは共和分関係の有無にかかわらず、Granger因果性検定 を行うための手法です。
本手法のポイントは、データ系列の最大和分次数 \(d_{max}\) を決定し、最適なラグ長 \(k\) に \(d_{max}\) を足した \(p = k + d_{max}\) のラグ長でVARモデルを推定した上で、最初の \(k\) 個のラグ係数に対してのみWald検定を行うという点にあります。
追加した \(d_{max}\) のラグは検定対象に含めません。
以下は、この一連のプロセスを確認するためのシミュレーションコードです。
なお、有意水準は5%とします。
サンプルデータの生成
\(X\) をランダムウォーク(I(1)過程)とし、\(Y\) を \(X\) の過去の値(ラグ1とラグ2)に依存して決定されるI(1)過程として生成します。
これにより、真のデータ構造として「\(X\) は \(Y\) のGranger因果である」が「\(Y\) は \(X\) のGranger因果ではない」という関係が成立します。
# 必要なパッケージの読み込み
library(ggplot2)
library(tidyr)
library(dplyr)
library(vars)
library(car)
# -----------------------------------------------------
# 1. データ生成 (Data Generation Process: DGP)
# -----------------------------------------------------
seed <- 20260409
set.seed(seed)
N <- 250 # サンプルサイズ
# 誤差項の生成
e_x <- rnorm(N, mean = 0, sd = 1)
e_y <- rnorm(N, mean = 0, sd = 1)
X <- numeric(N)
Y <- numeric(N)
# 初期値
X[1:2] <- 0
Y[1:2] <- 0
# 【DGPの設定】
# Xはランダムウォーク (I(1)過程)
# Yは自身のラグとXのラグに依存する I(1)過程
# つまり「X -> Y」のGranger因果関係は存在するが、「Y -> X」のGranger因果関係は存在しない。
for (t in 3:N) {
X[t] <- X[t-1] + e_x[t]
Y[t] <- Y[t-1] + 0.6 * X[t-1] - 0.4 * X[t-2] + e_y[t]
}
# データフレームの作成
df <- data.frame(Time = 1:N, X = X, Y = Y)
# -----------------------------------------------------
# 2. データのプロット (ggplot2)
# -----------------------------------------------------
p <- df %>%
pivot_longer(cols = c(X, Y), names_to = "Variable", values_to = "Value") %>%
ggplot(aes(x = Time, y = Value, color = Variable)) +
geom_line(linewidth = 0.8) +
labs(
title = "シミュレーションデータ: I(1)系列 X および Y",
subtitle = "X から Y へのGranger因果関係を持たせて生成",
x = "時間 (Time)",
y = "値 (Value)"
) +
scale_color_manual(values = c("X" = "blue", "Y" = "red")) +
theme_minimal() +
theme(legend.position = "bottom")
print(p)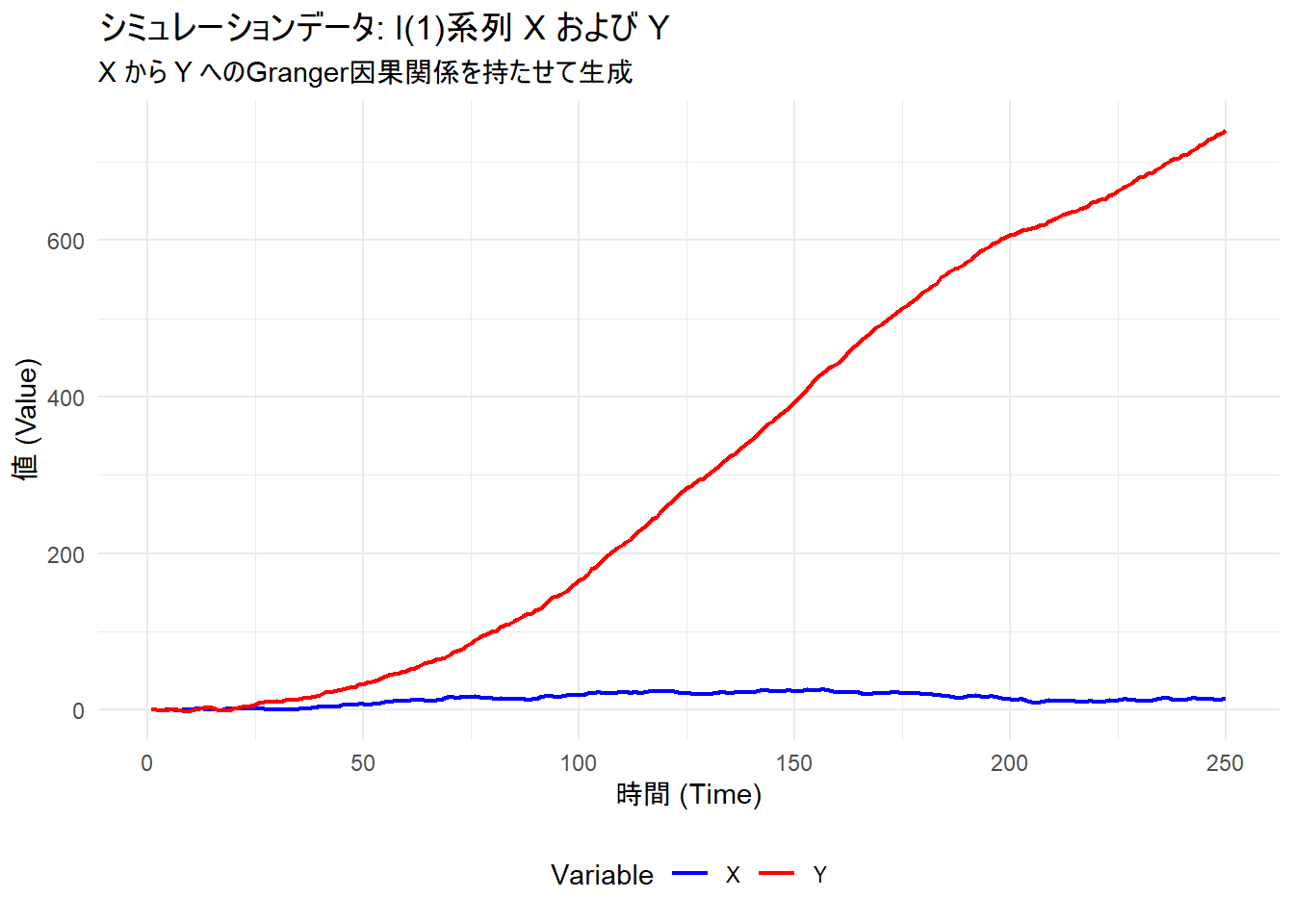
Toda-Yamamoto法によるGranger因果性検定
# -----------------------------------------------------
# 3. Toda-Yamamoto法の適用
# -----------------------------------------------------
data_ts <- data.frame(X = df$X, Y = df$Y)
# (Step 1) 最大和分次数 dmax の決定
# 今回はDGPから I(1) 過程であることが既知なので dmax = 1 とする。
# 実データではADF検定などで単位根の検定を行って決定します。
dmax <- 1
cat("=== Step 1: 最大和分次数 dmax の決定 ===\n")
cat("選択された最大和分次数 dmax =", dmax, "\n\n")
# (Step 2) レベルデータを用いてVARモデルの最適ラグ長 k を選択
lag_select <- VARselect(data_ts, lag.max = 8, type = "const")
k <- as.numeric(lag_select$selection["AIC(n)"])
cat("=== Step 2: 情報量基準(AIC)による最適ラグ長の選択 ===\n")
cat("選択された最適ラグ長 k =", k, "\n\n")
# (Step 3) ラグ長 p = k + dmax としたVARモデルの推定
p_lag <- k + dmax
cat("=== Step 3: VARモデルの推定 ===\n")
cat("推定するVARモデルのラグ長 p = k + dmax =", p_lag, "\n\n")
var_model <- VAR(data_ts, p = p_lag, type = "const")
# (Step 4) Granger因果性の検定 (MWALD検定)
# 最初の k 個のラグ係数が同時にゼロであるかを Wald検定(カイ二乗検定)で確認する。
# 追加した dmax のラグ(ここでは X.l3 や Y.l3 など)は制約に含めないことがToda-Yamamoto法のポイントです。
# 検定する帰無仮説の文字列を作成
hypothesis_X_to_Y <- paste0("X.l", 1:k, " = 0")
hypothesis_Y_to_X <- paste0("Y.l", 1:k, " = 0")
cat("=== Step 4: Toda-Yamamoto 法による Granger 因果性検定 ===\n\n")
cat("検定 1 : 帰無仮説: X は Y を Granger 因果しない (X -> Y)\n")
# 従属変数が Y のモデルに対して、Xのラグ係数が0かテスト
wald_X_to_Y <- linearHypothesis(var_model$varresult$Y, hypothesis_X_to_Y, test = "Chisq")
print(wald_X_to_Y)
cat("\n----------------------------------------------------------\n\n")
cat("検定 2 : 帰無仮説: Y は X を Granger 因果しない (Y -> X)\n")
# 従属変数が X のモデルに対して、Yのラグ係数が0かテスト
wald_Y_to_X <- linearHypothesis(var_model$varresult$X, hypothesis_Y_to_X, test = "Chisq")
print(wald_Y_to_X)=== Step 1: 最大和分次数 dmax の決定 ===
選択された最大和分次数 dmax = 1
=== Step 2: 情報量基準(AIC)による最適ラグ長の選択 ===
選択された最適ラグ長 k = 3
=== Step 3: VARモデルの推定 ===
推定するVARモデルのラグ長 p = k + dmax = 4
=== Step 4: Toda-Yamamoto 法による Granger 因果性検定 ===
検定 1 : 帰無仮説: X は Y を Granger 因果しない (X -> Y)
Linear hypothesis test:
X.l1 = 0
X.l2 = 0
X.l3 = 0
Model 1: restricted model
Model 2: y ~ -1 + (X.l1 + Y.l1 + X.l2 + Y.l2 + X.l3 + Y.l3 + X.l4 + Y.l4 +
const)
Res.Df RSS Df Sum of Sq Chisq Pr(>Chisq)
1 240 277.65
2 237 205.37 3 72.283 83.415 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
----------------------------------------------------------
検定 2 : 帰無仮説: Y は X を Granger 因果しない (Y -> X)
Linear hypothesis test:
Y.l1 = 0
Y.l2 = 0
Y.l3 = 0
Model 1: restricted model
Model 2: y ~ -1 + (X.l1 + Y.l1 + X.l2 + Y.l2 + X.l3 + Y.l3 + X.l4 + Y.l4 +
const)
Res.Df RSS Df Sum of Sq Chisq Pr(>Chisq)
1 240 230.85
2 237 226.63 3 4.2235 4.4167 0.2198モデルとラグ長の確認
両方の出力の Model 2 の式を見ると、X.l1 から X.l4、Y.l1 から Y.l4 までの変数が含まれています。
これは、VARモデルのラグ長 \(p\) が \(4\) で推定されたことを意味しています。
また、「Linear hypothesis test」の項目を見ると、検定対象となっているのはラグ1〜3(l1, l2, l3)のみです。
ここから、データから選択された最適ラグ長は \(k = 3\) であり、データがI(1)過程であるため最大和分次数 \(d_{max} = 1\) を足した \(p = 3 + 1 = 4\) のラグ長でモデルを推定していることが分かります。
追加した \(d_{max}\) 分のラグ(l4)は検定から除外するという、Toda-Yamamoto法の手法が機能しています。
検定1 : X から Y へのGranger因果性の結果 (wald_X_to_Y)
- 帰無仮説:
-
X.l1 = 0,X.l2 = 0,X.l3 = 0 - 「\(X\) の過去の値は、\(Y\) の現在の値に影響を与えない(\(X\)は\(Y\)をGranger因果しない)」
-
- 結果の数値:
-
Chisq= 83.415,Pr(>Chisq)< 2.2e-16 ***
-
p値(Pr(>Chisq))が \(2.2 \times 10^{-16}\) 未満と設定した有意水準である 5% (\(0.05\))を下回っています。
したがって、帰無仮説は棄却され、「\(X\) は \(Y\) に対して Granger 因果性を持つ(\(X\)の過去の動きを変数に含めたほうが\(Y\)の動きの予測精度が上がる)」と判定されます。
つまり、サンプルデータ生成時の設定通りの結果が得られています。
検定2 : Y から X への因果性の結果 (wald_Y_to_X)
- 帰無仮説:
-
Y.l1 = 0,Y.l2 = 0,Y.l3 = 0 - 「\(Y\) の過去の値は、\(X\) の現在の値に影響を与えない(\(Y\)は\(X\)をGranger因果しない)」
-
- 結果の数値:
-
Chisq= 4.4167,Pr(>Chisq)0.2198
-
p値が \(0.2198\)(約 22%)となっており、設定した有意水準である 5% (\(0.05\)) よりも大きい値です。
したがって、帰無仮説を棄却することはできず、「\(Y\) は \(X\) に対して Granger 因果性を持たない(\(Y\)の過去の動きを変数に含めても\(X\)の動きの予測精度は変化しない)」と判定されます。
つまり、こちらもサンプルデータ生成時の設定通りの結果が得られています。
通常のGranger因果性検定との比較
Toda-Yamamoto法との違いを確認するため、同じデータ・同じWald検定の関数(linearHypothesis)を用いて、モデルのラグ長を \(k\) のまま(\(d_{max}\) を足さずに)推定・検定する構成にします。
# k は AIC によって選択された最適ラグ長(前回は k=3)
# -----------------------------------------------------
# 通常のGranger因果性検定 (dmax を足さない)
# -----------------------------------------------------
cat("=== 通常のGranger因果性検定 (ラグ長 p = k) ===\n")
cat("推定するVARモデルのラグ長 p = k =", k, "\n\n")
# 最適ラグ長 k のみでVARモデルを推定
var_model_normal <- VAR(data_ts, p = k, type = "const")
# 検定する帰無仮説 (すべてのラグ係数が0であるかを検定)
hypothesis_X_to_Y_normal <- paste0("X.l", 1:k, " = 0")
hypothesis_Y_to_X_normal <- paste0("Y.l", 1:k, " = 0")
cat("検定 1 : 帰無仮説: X は Y を Granger 因果しない (X -> Y)\n")
wald_X_to_Y_normal <- linearHypothesis(var_model_normal$varresult$Y, hypothesis_X_to_Y_normal, test = "Chisq")
print(wald_X_to_Y_normal)
cat("\n----------------------------------------------------------\n\n")
cat("検定 2 : 帰無仮説: Y は X を Granger 因果しない (Y -> X)\n")
wald_Y_to_X_normal <- linearHypothesis(var_model_normal$varresult$X, hypothesis_Y_to_X_normal, test = "Chisq")
print(wald_Y_to_X_normal)=== 通常のGranger因果性検定 (ラグ長 p = k) ===
推定するVARモデルのラグ長 p = k = 3
検定 1 : 帰無仮説: X は Y を Granger 因果しない (X -> Y)
Linear hypothesis test:
X.l1 = 0
X.l2 = 0
X.l3 = 0
Model 1: restricted model
Model 2: y ~ -1 + (X.l1 + Y.l1 + X.l2 + Y.l2 + X.l3 + Y.l3 + const)
Res.Df RSS Df Sum of Sq Chisq Pr(>Chisq)
1 243 334.11
2 240 206.38 3 127.74 148.55 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
----------------------------------------------------------
検定 2 : 帰無仮説: Y は X を Granger 因果しない (Y -> X)
Linear hypothesis test:
Y.l1 = 0
Y.l2 = 0
Y.l3 = 0
Model 1: restricted model
Model 2: y ~ -1 + (X.l1 + Y.l1 + X.l2 + Y.l2 + X.l3 + Y.l3 + const)
Res.Df RSS Df Sum of Sq Chisq Pr(>Chisq)
1 243 240.19
2 240 230.28 3 9.9112 10.33 0.01596 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1モデルのラグ長の確認
両方の出力の Model 2 の式を見ると、変数は l1 から l3 までとなっています。
Toda-Yamamoto法では \(d_{max}\) を足して l4 まで含めていましたが、今回は情報量基準で選ばれた \(k=3\) のラグ長だけでVARモデルを推定し、すべてのラグ係数を検定対象としています。
検定1 : X から Y へのGranger因果性の結果 (wald_X_to_Y_normal)
- 帰無仮説:
-
X.l1 = 0,X.l2 = 0,X.l3 = 0(X は Y を Granger 因果しない)
-
- 結果:
-
Pr(>Chisq)< 2.2e-16 ***
-
こちらについては p値 がほぼ 0 であり、帰無仮説が棄却され、シミュレーションの真の設定(X は Y のGranger因果である)と合致しているため、ここまでは問題ないように見えます。
検定2 : Y から X へのGranger因果性の結果 (wald_Y_to_X_normal)
- 帰無仮説:
-
Y.l1 = 0,Y.l2 = 0,Y.l3 = 0(Y は X を Granger 因果しない)
-
- 結果:
-
Pr(>Chisq)= 0.01596 *
-
p値が \(0.01596\)(約 1.6%)となっており、設定した有意水準である 5% (\(0.05\)) を下回っています。
つまり、「\(Y\) は \(X\) に対して Granger 因果性を持つ」と判定されてしまいました。
しかし、シミュレーションの設定では、\(X\) はランダムウォークとして生成されており、\(Y\) の過去の動きには一切影響を受けていません。
真のデータ構造において「Y から X へのGranger因果関係は存在しない」のです。
関数 lmtest::grangertest を利用した通常のGranger因果性検定(F検定)
library(lmtest)
# 検定 1
cat('検定 1\n')
print(grangertest(Y ~ X, order = k, data = data_ts)) # X -> Y
# 検定 2
cat('\n検定 2\n')
print(grangertest(X ~ Y, order = k, data = data_ts)) # Y -> X検定 1
Granger causality test
Model 1: Y ~ Lags(Y, 1:3) + Lags(X, 1:3)
Model 2: Y ~ Lags(Y, 1:3)
Res.Df Df F Pr(>F)
1 240
2 243 -3 49.516 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
検定 2
Granger causality test
Model 1: X ~ Lags(X, 1:3) + Lags(Y, 1:3)
Model 2: X ~ Lags(X, 1:3)
Res.Df Df F Pr(>F)
1 240
2 243 -3 3.4432 0.01746 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1F検定によるモデル比較
出力の Model 1 と Model 2 の式を確認します。
- Model 1(制約なしモデル):
- 予測対象の変数の過去の値に加えて、もう一方の変数の過去の値(ラグ1〜3)も含めたモデル。
- Model 2(制約ありモデル):
- 自身の過去の値(ラグ1〜3)のみで予測するモデル。
grangertest は、この「Model 1」と「Model 2」の予測精度を比較し、「相手の過去の値をモデルに加えたことで、予測精度が統計的に有意に向上したか」を F検定 で判定しています。
検定1 : X から Y への因果性 (X -> Y)
- 帰無仮説:
- X のラグを含めても Y の予測は改善しない(X は Y を Granger 因果しない)
- 結果:
-
Pr(>F)< 2.2e-16 ***
-
p値がほぼ 0 であり、帰無仮説は棄却され、「Xの過去の値を含めることでYの予測精度が向上する」という結果であり、これはシミュレーションの設定(真の関係性)通りです。
検定2 : Y から X への因果性 (Y -> X)
- 帰無仮説:
- Y のラグを含めても X の予測は改善しない(Y は X を Granger 因果しない)
- 結果:
-
Pr(>F)= 0.01746 *
-
p値が \(0.01746\)(約 1.7%)となっており、設定した有意水準5% (\(0.05\)) を下回っています。
本来、X はランダムウォークであり Y の過去の値には全く影響を受けていないにもかかわらず、「Y の過去の値を変数に含めることで X の予測精度が上がる」という誤った結論を導いてしまっています。
以上です。

