
Rで積推定をシミュレーションします。
本ポストはこちらの続きです。

積推定とは
積推定は、目標変数 \(y\) と補助変数 \(x\) が負の相関を持つ場合に、比推定の代わりに用いる推定手法です。
基本的な考え方
比推定が \(y/x\) の比を利用するのに対し、積推定は \(y \cdot x\) の積に着目します。\(y\) と \(x\) が負の相関を持つとき、\(\bar{y} \cdot \bar{x}\) は \(\mu_y \cdot \mu_x\) を安定して推定できるという性質を利用します。
積推定量
\[\hat{\mu}_y^P = \bar{y} \cdot \frac{\bar{x}}{\mu_x}\]
つまり、標本平均 \(\bar{y}\) を補助変数の比 \(\bar{x}/\mu_x\) でスケールアップします。\(\bar{x} > \mu_x\) なら推定値を大きく、\(\bar{x} < \mu_x\) なら小さく補正します。
比推定と対比すると明確です:
| 推定量 | 補正の方向 | |
|---|---|---|
| 比推定 | \(\bar{y} \cdot \dfrac{\mu_x}{\bar{x}}\) | \(\bar{x}\) が大きければ推定値を小さく |
| 積推定 | \(\bar{y} \cdot \dfrac{\bar{x}}{\mu_x}\) | \(\bar{x}\) が大きければ推定値を大きく |
\(y\) と \(x\) が負の相関なら、\(\bar{x}\) が大きいとき \(\bar{y}\) は小さくなりがちなので、積推定の補正が直感と合致します。
分散の近似式
テイラー展開による一次近似:
\[V(\hat{\mu}_y^P) \approx \frac{1-f}{n}\left(S_y^2 + S_x^2 \cdot \frac{\mu_y^2}{\mu_x^2} + 2\frac{\mu_y}{\mu_x} S_{xy}\right)\]
\(C_x, C_y\)(変動係数)と \(\rho_{xy}\)(相関係数)で書き直すと:
\[V(\hat{\mu}_y^P) \approx \frac{1-f}{n} S_y^2 \left(1 + C_x^2/C_y^2 + 2\rho_{xy} \frac{C_x}{C_y}\right)\]
単純推定・比推定との比較
| 特性 | 単純推定 | 比推定 | 積推定 |
|---|---|---|---|
| 推定量 | \(\bar{y}\) | \(\bar{y} \cdot \dfrac{\mu_x}{\bar{x}}\) | \(\bar{y} \cdot \dfrac{\bar{x}}{\mu_x}\) |
| 不偏性 | 不偏 | 近似的に不偏 | 近似的に不偏 |
| 有効な条件 | 常に使える | \(\rho > \dfrac{R C_x}{2C_y}\) | \(\rho < -\dfrac{C_x}{2C_y} \cdot \dfrac{\mu_y}{\mu_x}\) |
積推定が単純推定より有利になる条件は、積推定の分散が単純推定の分散より小さいことです。すなわち:
\[V(\hat{\mu}_y^P) < V(\bar{y})\]
単純無作為抽出(非復元)における \(\bar{y}\) の分散は:
\[V(\bar{y}) = \frac{1-f}{n} S_y^2\]
ここで:
| 記号 | 意味 |
|---|---|
| \(f = n/N\) | 標本比率(sampling fraction) |
| \(1-f\) | 有限母集団修正係数(finite population correction) |
| \(n\) | 標本サイズ |
| \(S_y^2 = \dfrac{1}{N-1}\displaystyle\sum_{i=1}^N (y_i - \mu_y)^2\) | 母集団の不偏分散 |
ですので、両辺に共通する \(\dfrac{1-f}{n}\) を消去して分散の核の部分だけ書くと:
\[S_y^2 + \frac{\mu_y^2}{\mu_x^2}S_x^2 + \frac{2\mu_y}{\mu_x}S_{xy} < S_y^2\]
左辺から右辺を引いた差が負になる条件を求めます:
\[\frac{\mu_y^2}{\mu_x^2}S_x^2 + \frac{2\mu_y}{\mu_x}S_{xy} < 0\]
\(\dfrac{\mu_y}{\mu_x} > 0\) で割ると:
\[\frac{\mu_y}{\mu_x}S_x^2 + 2S_{xy} < 0\]
\(S_{xy} = \rho \cdot S_x \cdot S_y\) を代入:
\[\frac{\mu_y}{\mu_x}S_x^2 + 2\rho S_x S_y < 0\]
\(S_x > 0\) で割ると:
\[\frac{\mu_y}{\mu_x}S_x + 2\rho S_y < 0\]
両辺を \(2S_y\) で割り、\(C_x = S_x/\mu_x\)、\(C_y = S_y/\mu_y\) を使って整理すると:
\[\rho < -\frac{\mu_y}{\mu_x} \cdot \frac{S_x}{2S_y} = -\frac{\mu_y}{\mu_x} \cdot \frac{C_x}{2C_y} \cdot \frac{\mu_x}{\mu_y} \cdot \frac{\mu_y}{\mu_x}\]
\[\rho < -\frac{R \cdot C_x}{2C_y} = -\frac{\kappa}{2}\]
すなわち、十分に強い負の相関が必要です。
具体例
気象・農業:気温 \(x\)(夏の高温)が高いほど害虫被害 \(y\) が少ない(負の相関)→ 積推定が有効。
経済:金利 \(x\) が上がると設備投資 \(y\) が減る(負の相関)→ 積推定の適用が考えられる。
比推定・積推定の統一的理解
両者は回帰推定(Regression estimator)の特殊ケースとして統一できます。
\[\hat{\mu}_y^{reg} = \bar{y} + \hat{\beta}(\mu_x - \bar{x})\]
- \(\hat{\beta} = \bar{y}/\bar{x}\)(切片なし回帰)→ 比推定
- \(\hat{\beta} = -\bar{y}/\mu_x\)(積推定に対応する補正係数)→ 積推定
実務では、\(\rho\) の符号と大きさを確認したうえで比推定・積推定・回帰推定のいずれを使うか選択します。正の相関が強ければ比推定、負の相関が強ければ積推定、それ以外は回帰推定が一般的な指針です。
積推定(Product Estimation)シミュレーション
- 目的:
- 母集団を人工的に生成し、積推定量の性質を確認する
- 単純推定・比推定・積推定の分散・偏りを比較する
- 相関係数と推定効率の関係を可視化する
パート1:母集団の生成
- 設定:夏の気温 x(既知)と害虫被害量 y(未知)
- x と y は負の相関を持つ(高温ほど害虫が少ない)
library(ggplot2)
library(dplyr)
library(tidyr)
library(patchwork)
seed <- 20260701
set.seed(seed)
N <- 1000 # 母集団サイズ
n <- 50 # 標本サイズ
# 補助変数 x(気温偏差、標準化済み、正値)
x_pop <- rgamma(N, shape = 10, rate = 1) # 平均10程度
# y と x を負の相関で生成
# 共通因子 z を使って ρ を制御する
rho_target <- -0.85
z_common <- scale(x_pop)[, 1]
z_indep <- rnorm(N)
y_std <- rho_target * z_common + sqrt(1 - rho_target^2) * z_indep
# y を正値・適切なスケールに変換
mu_y_target <- 12
sd_y_target <- 3
y_pop <- mu_y_target + sd_y_target * y_std
y_pop <- pmax(y_pop, 0.1) # 負値を除去
# 母集団パラメータ
mu_x <- mean(x_pop)
mu_y <- mean(y_pop)
rho <- cor(x_pop, y_pop)
S2_y <- var(y_pop)
S2_x <- var(x_pop)
S_xy <- cov(x_pop, y_pop)
Cy <- sqrt(S2_y) / mu_y
Cx <- sqrt(S2_x) / mu_x
cat("===== 母集団パラメータ =====\n")
cat(sprintf("母平均 μ_x = %.4f\n", mu_x))
cat(sprintf("母平均 μ_y = %.4f\n", mu_y))
cat(sprintf("x と y の相関係数 ρ = %.4f\n", rho))
cat(sprintf("変動係数 Cx = %.4f, Cy = %.4f\n", Cx, Cy))===== 母集団パラメータ =====
母平均 μ_x = 9.9017
母平均 μ_y = 12.0207
x と y の相関係数 ρ = -0.8569
変動係数 Cx = 0.3076, Cy = 0.2468パート2:モンテカルロシミュレーション
B <- 5000 # シミュレーション回数
results <- replicate(B,
{
idx <- sample(N, n, replace = FALSE)
xs <- x_pop[idx]
ys <- y_pop[idx]
# 単純推定
est_simple <- mean(ys)
# 比推定
est_ratio <- mean(ys) / mean(xs) * mu_x
# 積推定
est_product <- mean(ys) * mean(xs) / mu_x
c(simple = est_simple, ratio = est_ratio, product = est_product)
},
simplify = TRUE
)
df_sim <- as.data.frame(t(results))
# 集計
cat("===== シミュレーション結果(B =", B, "回)=====\n")
for (m in c("simple", "ratio", "product")) {
label <- c(simple = "単純推定", ratio = "比推定", product = "積推定")[m]
cat(sprintf("\n【%s】\n", label))
cat(sprintf(" 平均(期待値) = %.4f\n", mean(df_sim[[m]])))
cat(sprintf(" 偏り(Bias) = %.4f\n", mean(df_sim[[m]]) - mu_y))
cat(sprintf(" 分散 = %.6f\n", var(df_sim[[m]])))
cat(sprintf(" RMSE = %.4f\n", sqrt(mean((df_sim[[m]] - mu_y)^2))))
}
eff_ratio <- var(df_sim$simple) / var(df_sim$ratio)
eff_product <- var(df_sim$simple) / var(df_sim$product)
cat(sprintf("\n相対効率(単純分散/比推定分散) = %.4f\n", eff_ratio))
cat(sprintf("相対効率(単純分散/積推定分散) = %.4f\n", eff_product))===== シミュレーション結果(B = 5000 回)=====
【単純推定】
平均(期待値) = 12.0233
偏り(Bias) = 0.0027
分散 = 0.170757
RMSE = 0.4132
【比推定】
平均(期待値) = 12.0646
偏り(Bias) = 0.0439
分散 = 0.809787
RMSE = 0.9009
【積推定】
平均(期待値) = 12.0043
偏り(Bias) = -0.0163
分散 = 0.071255
RMSE = 0.2674
相対効率(単純分散/比推定分散) = 0.2109
相対効率(単純分散/積推定分散) = 2.3964- 比推定の相対効率 = 0.2109
- 単純推定の分散が比推定の分散の約 0.21 倍、つまり比推定の分散は単純推定の約 4.7 倍大きいことを意味します。
- 今回の母集団は \(\rho \approx -0.85\) という強い負の相関を持つため、比推定の補正方向が逆効果になっています。
- \(\bar{x}\) が大きいとき \(\bar{y}\) は小さくなりやすいのに、比推定は \(\mu_x / \bar{x}\) でさらに小さく補正してしまうためです。
- 相対効率が 1 を大きく下回っており、この状況で比推定を使うことは推奨されません。
- 積推定の相対効率 = 2.3964
- 単純推定の分散が積推定の分散の約 2.40 倍、つまり積推定の分散は単純推定の約 0.42 倍であることを意味します。
- 相対効率が 1 を上回っており、積推定が単純推定より効率的です。
- \(\bar{x}\) が大きいとき \(\bar{y}\) は小さくなりやすいという負の相関の性質を、\(\bar{x}/\mu_x\) による補正がうまく捉えています。
- 同じ標本サイズ \(n=50\) でも、積推定を使うことで単純推定の約 2.4 倍の情報量に相当する精度が得られています。
- まとめ
- 強い負の相関(\(\rho \approx -0.85\))を持つ今回のデータでは、補助変数の活用法として積推定が正しい選択であることが数値で明確に確認できます。
パート3:理論値との比較
f <- n / N
V_simple_theory <- (1 - f) / n * S2_y
V_ratio_theory <- (1 - f) / n * (S2_y + (mu_y / mu_x)^2 * S2_x - 2 * (mu_y / mu_x) * S_xy)
V_product_theory <- (1 - f) / n * (S2_y + (mu_y / mu_x)^2 * S2_x + 2 * (mu_y / mu_x) * S_xy)
cat("===== 理論値との比較 =====\n")
cat(sprintf(
"単純推定の理論分散 = %.6f(シミュレーション: %.6f)\n",
V_simple_theory, var(df_sim$simple)
))
cat(sprintf(
"比推定の理論分散 = %.6f(シミュレーション: %.6f)\n",
V_ratio_theory, var(df_sim$ratio)
))
cat(sprintf(
"積推定の理論分散 = %.6f(シミュレーション: %.6f)\n",
V_product_theory, var(df_sim$product)
))===== 理論値との比較 =====
単純推定の理論分散 = 0.167182(シミュレーション: 0.170757)
比推定の理論分散 = 0.784056(シミュレーション: 0.809787)
積推定の理論分散 = 0.069780(シミュレーション: 0.071255)パート4:相関係数と効率性の関係
rho_seq <- seq(-0.99, 0.99, by = 0.01)
# 単純推定の分散を1に正規化した相対効率
# 比推定:1 / (1 + (R*Cx/Cy)^2 - 2*ρ*R*Cx/Cy) ただし R = mu_y/mu_x
# 積推定:1 / (1 + (R*Cx/Cy)^2 + 2*ρ*R*Cx/Cy)
R_val <- mu_y / mu_x
kappa <- R_val * Cx / Cy # 共通の係数
eff_ratio_theory <- 1 / (1 + kappa^2 - 2 * rho_seq * kappa)
eff_product_theory <- 1 / (1 + kappa^2 + 2 * rho_seq * kappa)
# 閾値
threshold_ratio <- kappa / 2 # 比推定が有利: ρ > kappa/2
threshold_product <- -kappa / 2 # 積推定が有利: ρ < -kappa/2
df_eff <- data.frame(
rho = rep(rho_seq, 2),
efficiency = c(eff_ratio_theory, eff_product_theory),
method = rep(c("比推定", "積推定"), each = length(rho_seq))
)
# 表示範囲を制限
df_eff$efficiency <- pmin(pmax(df_eff$efficiency, 0), 6)
cat("===== 効率性の条件 =====\n")
cat(sprintf("R*Cx/Cy (κ) = %.4f\n", kappa))
cat(sprintf("比推定が有利になる閾値:ρ > κ/2 = %.4f\n", threshold_ratio))
cat(sprintf("積推定が有利になる閾値:ρ < -κ/2 = %.4f\n", threshold_product))
cat(sprintf("今回の相関係数 ρ = %.4f\n", rho))
cat(sprintf(
"→ 比推定:%s\n",
ifelse(rho > threshold_ratio, "有利 ✓", "不利 ✗")
))
cat(sprintf(
"→ 積推定:%s\n",
ifelse(rho < threshold_product, "有利 ✓", "不利 ✗")
))===== 効率性の条件 =====
R*Cx/Cy (κ) = 1.5132
比推定が有利になる閾値:ρ > κ/2 = 0.7566
積推定が有利になる閾値:ρ < -κ/2 = -0.7566
今回の相関係数 ρ = -0.8569
→ 比推定:不利 ✗
→ 積推定:有利 ✓- \(\kappa = R \cdot C_x / C_y = 1.5132\)
- 閾値の計算に使う共通係数です。
- \(R = \mu_y/\mu_x\)(目標変数と補助変数の平均の比)、\(C_x\)(補助変数の変動係数)、\(C_y\)(目標変数の変動係数)の積で決まります。
- \(\kappa > 1\) であることは、補助変数 \(x\) の相対的なばらつきが \(y\) より大きいことを反映しています。
- 比推定の閾値 \(\rho > \kappa/2 = 0.7566\)
- 比推定が単純推定より有利になるには、\(\rho > 0.7566\) という強い正の相関が必要です。
- \(\kappa = 1.51\) と大きいため、閾値も 0.76 と高くなっています。
- \(\kappa\) が大きいほど比推定の「癖」が強く、正の相関が弱い状況では逆効果になりやすいことを意味します。
- 積推定の閾値 \(\rho < -\kappa/2 = -0.7566\)
- 積推定が単純推定より有利になるには、\(\rho < -0.7566\) という強い負の相関が必要です。
- 比推定の閾値と絶対値が等しく符号が逆になるのは、積推定が比推定の補正方向を反転させた対称的な構造を持つためです。
- 今回の相関係数 \(\rho = -0.8569\)
- 設定した負の相関が実際に実現しています。
- この値を両閾値と照合すると、\(\rho = -0.8569\) は積推定の閾値 \(-0.7566\) を下回っており(より強い負の相関)、積推定が有利であることが理論的に確認できます。
- 逆に比推定は閾値を大きく外れており、前の結果で相対効率が 0.21 と極めて低かった理由が、この閾値との乖離からも裏付けられます。
パート5:可視化
# --- 図1: 母集団の散布図 ---
df_pop <- data.frame(x = x_pop, y = y_pop)
p1 <- ggplot(df_pop[sample(N, 300), ], aes(x = x, y = y)) +
geom_point(alpha = 0.4, color = "#756bb1", size = 1.5) +
geom_smooth(
method = "lm", se = FALSE,
color = "#d7191c", linewidth = 1, linetype = "dashed"
) +
labs(
title = "母集団:x と y の関係",
subtitle = sprintf("相関係数 ρ = %.3f(負の相関)", rho),
x = "補助変数 x(気温偏差)",
y = "目標変数 y(害虫被害量)"
) +
theme_bw() +
theme(plot.title = element_text(size = 13, face = "bold"), plot.subtitle = element_text(size = 10))
# --- 図2: 推定量の分布比較(ヒストグラム)---
df_long <- df_sim |>
pivot_longer(everything(),
names_to = "method",
values_to = "estimate"
) |>
mutate(method = recode(method,
simple = "単純推定",
ratio = "比推定",
product = "積推定"
))
p2 <- ggplot(df_long, aes(x = estimate, fill = method)) +
geom_histogram(aes(y = after_stat(density)),
bins = 60, alpha = 0.55, position = "identity"
) +
geom_vline(
xintercept = mu_y, color = "black",
linewidth = 1.2, linetype = "solid"
) +
scale_fill_manual(values = c(
"単純推定" = "#fc8d59",
"比推定" = "#2c7bb6",
"積推定" = "#1a9641"
)) +
labs(
title = "推定量の標本分布",
subtitle = sprintf("黒線:真の母平均 μ_y = %.2f", mu_y),
x = "推定値", y = "密度", fill = "推定法"
) +
theme_bw() +
theme(
plot.title = element_text(size = 13, face = "bold"), plot.subtitle = element_text(size = 10),
legend.position = "top"
)
# --- 図3: 相対効率 vs 相関係数 ---
p3 <- ggplot(df_eff, aes(x = rho, y = efficiency, color = method)) +
geom_line(linewidth = 1.2) +
geom_hline(
yintercept = 1, linetype = "dashed",
color = "gray40", linewidth = 0.8
) +
geom_vline(
xintercept = threshold_ratio,
color = "#2c7bb6", linetype = "dotted", linewidth = 1
) +
geom_vline(
xintercept = threshold_product,
color = "#1a9641", linetype = "dotted", linewidth = 1
) +
geom_vline(
xintercept = rho,
color = "gray20", linetype = "solid", linewidth = 0.9
) +
annotate("text",
x = threshold_ratio - 0.03, y = 4.5,
label = sprintf("比推定\n閾値 ρ=%.2f", threshold_ratio),
color = "#2c7bb6", size = 3.2, hjust = 1
) +
annotate("text",
x = threshold_product + 0.03, y = 4.5,
label = sprintf("積推定\n閾値 ρ=%.2f", threshold_product),
color = "#1a9641", size = 3.2, hjust = 0
) +
annotate("text",
x = rho + 0.03, y = 2.5,
label = sprintf("今回\nρ=%.2f", rho),
color = "gray20", size = 3.2, hjust = 0
) +
scale_color_manual(values = c(
"比推定" = "#2c7bb6",
"積推定" = "#1a9641"
)) +
coord_cartesian(ylim = c(0, 6)) +
labs(
title = "相関係数と相対効率(理論曲線)",
subtitle = "相対効率 = Var(単純推定) / Var(各推定法) >1 なら\n単純推定より有利",
x = "相関係数 ρ(x, y)",
y = "相対効率",
color = "推定法"
) +
theme_bw() +
theme(
plot.title = element_text(size = 13, face = "bold"), plot.subtitle = element_text(size = 10),
legend.position = "top"
)
# --- 図4: 標本サイズと RMSE ---
n_seq <- seq(10, 200, by = 10)
rmse_df <- lapply(n_seq, function(ni) {
sims <- replicate(2000, {
idx <- sample(N, ni, replace = FALSE)
xs <- x_pop[idx]
ys <- y_pop[idx]
c(
simple = mean(ys),
ratio = mean(ys) / mean(xs) * mu_x,
product = mean(ys) * mean(xs) / mu_x
)
})
data.frame(
n = ni,
method = c("単純推定", "比推定", "積推定"),
rmse = c(
sqrt(mean((sims["simple", ] - mu_y)^2)),
sqrt(mean((sims["ratio", ] - mu_y)^2)),
sqrt(mean((sims["product", ] - mu_y)^2))
)
)
}) |> bind_rows()
p4 <- ggplot(rmse_df, aes(x = n, y = rmse, color = method)) +
geom_line(linewidth = 1.1) +
geom_point(size = 1.5) +
scale_color_manual(values = c(
"単純推定" = "#fc8d59",
"比推定" = "#2c7bb6",
"積推定" = "#1a9641"
)) +
labs(
title = "標本サイズと推定精度(RMSE)",
subtitle = "負の相関が強いため積推定が最も精度が高い",
x = "標本サイズ n",
y = "RMSE",
color = "推定法"
) +
theme_bw() +
theme(
plot.title = element_text(size = 13, face = "bold"), plot.subtitle = element_text(size = 10),
legend.position = "top"
)
# --- 統合出力 ---
combined <- (p1 + p2) / (p3 + p4) +
plot_annotation(
title = "積推定(Product Estimation)シミュレーション",
subtitle = sprintf(
"母集団サイズ N=%d 標本サイズ n=%d シミュレーション回数 B=%d ρ=%.2f",
N, n, B, rho
),
theme = theme(
plot.title = element_text(size = 16, face = "bold"),
plot.subtitle = element_text(size = 11, color = "gray40")
)
)
combined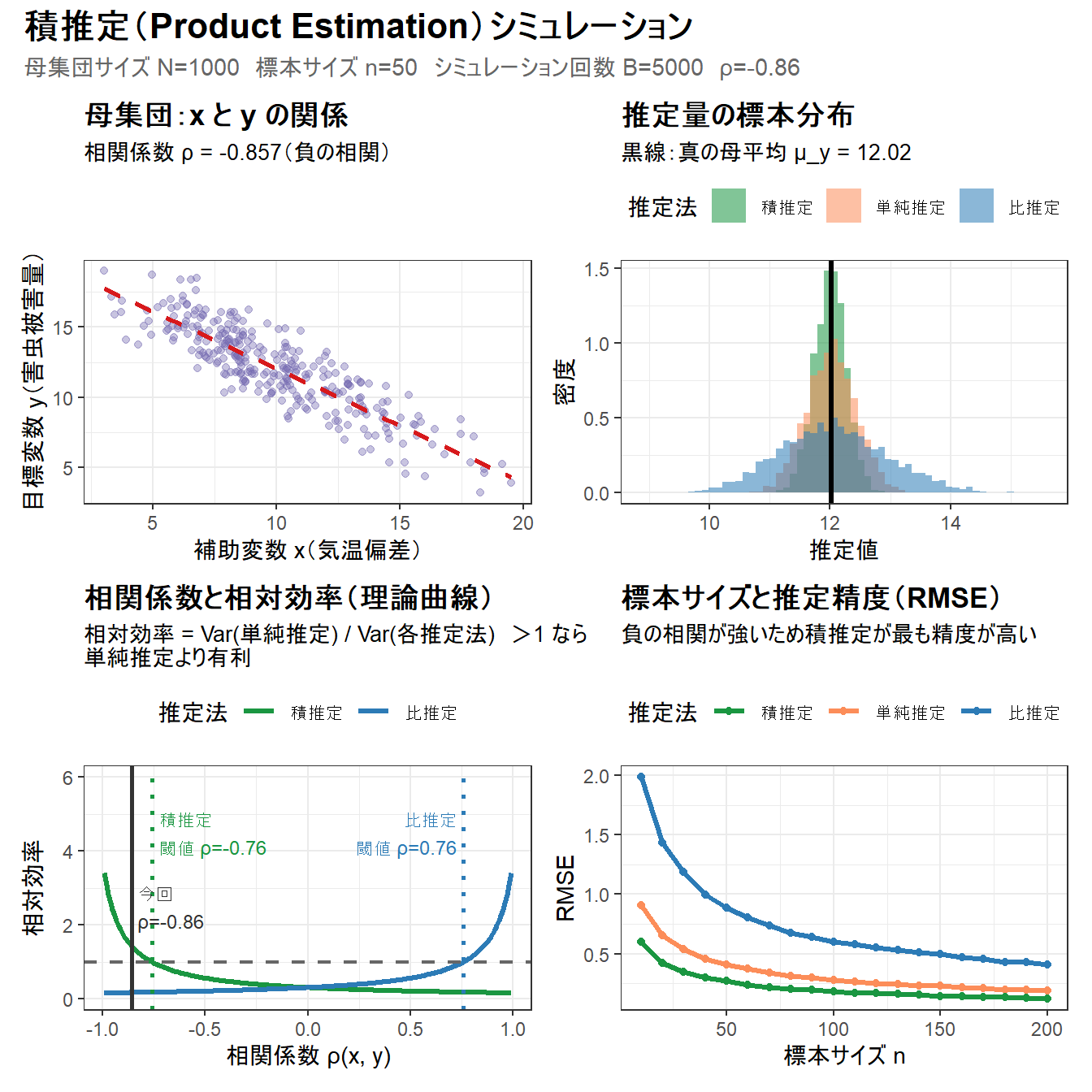
以上です。
