
Rの関数から yth_filter {neverhpfilter} を確認します。
関数 yth_filter とは
yth_filter は、「Hamiltonフィルタ」を実行し、時系列データから「トレンド成分」と「循環(サイクル)成分」を分離するための関数です。
具体的には、対象変数の \(h\) 期先の値を、現在の値および過去 \(p-1\) 期分の値を用いて回帰します。
本アプローチでは、得られた「予測値」をトレンド成分、「予測誤差(残差)」を循環成分として定義します。
関数 yth_filter の引数
library(neverhpfilter)
args(yth_filter)function (x, h = 8, p = 4, output = c("x", "trend", "cycle",
"random"), ...)
NULL-
x- 分析対象となる時系列データ。
-
xtsクラスのオブジェクトである必要があります。
-
h- 予測ホライズン(何期先のデータを予測するかを指定するパラメータ)。
- デフォルト:
8。四半期データに対する \(h = 8\)(2年先)分がデフォルトとして設定されています。
-
p- 回帰モデルに含めるラグの数(過去何期分を使用するかを指定するパラメータ)。
- デフォルト:
4。四半期データに対する \(p = 4\)(1年分)がデフォルトとして設定されています。本関数の仕様上、周期性を捕捉するため、p = 1を指定するとエラーが発生して計算が停止します。
-
output- 戻り値のオブジェクトに含める成分を指定する文字ベクトル。
- 選択肢:
"x"(元のデータ)、"trend"(トレンド成分)、"cycle"(循環成分)、"random"(ランダム成分:\(y_{t+h} - y_t\))。 - デフォルト: 全ての成分を出力します。特定の成分だけを抽出したい場合に指定を変更します。
-
...- 内部で呼び出される回帰関数
yth_glm(およびその先のglm)へ渡される追加の引数です。
- 内部で呼び出される回帰関数
シミュレーションコード
以下に、yth_filter 関数の機能を確認するためのサンプルデータを用いたシミュレーションコードを示します。
サンプルデータには、パッケージneverhpfilterに付属する GDPC1 を利用します。
なお、 GDPC1の仕様は以下の通りです。
- 米国国内総生産
- 実質季節調整済系列
- 2017暦年連鎖価格(10億ドル)
# 1. サンプルデータの読み込み
data("GDPC1")
cat("--- サンプルデータのクラス ---\n")
class(GDPC1)
cat("\n\n--- サンプルデータの一部を確認 ---\n")
print(GDPC1)--- サンプルデータのクラス ---
[1] "xts" "zoo"
--- サンプルデータの一部を確認 ---
GDPC1
1947-01-01 2182.681
1947-04-01 2176.892
1947-07-01 2172.432
1947-10-01 2206.452
1948-01-01 2239.682
1948-04-01 2276.690
1948-07-01 2289.770
1948-10-01 2292.364
1949-01-01 2260.807
1949-04-01 2253.128
...
2023-01-01 22403.435
2023-04-01 22539.418
2023-07-01 22780.933
2023-10-01 22960.600
2024-01-01 23053.545
2024-04-01 23223.906
2024-07-01 23400.294
2024-10-01 23542.349
2025-01-01 23512.717
2025-04-01 23685.287# 2. Hamiltonフィルタの適用
hamilton_filtered <- yth_filter(GDPC1, h = 8, p = 4)
cat("--- Hamiltonフィルタの結果の一部を確認 ---\n")
print(hamilton_filtered)--- Hamiltonフィルタの結果の一部を確認 ---
GDPC1 GDPC1.trend GDPC1.cycle GDPC1.random
1947-01-01 2182.681 NA NA NA
1947-04-01 2176.892 NA NA NA
1947-07-01 2172.432 NA NA NA
1947-10-01 2206.452 NA NA NA
1948-01-01 2239.682 NA NA NA
1948-04-01 2276.690 NA NA NA
1948-07-01 2289.770 NA NA NA
1948-10-01 2292.364 NA NA NA
1949-01-01 2260.807 NA NA 78.126
1949-04-01 2253.128 NA NA 76.236
...
2023-01-01 22403.435 21820.26 583.1701 1345.056
2023-04-01 22539.418 22273.09 266.3298 1150.413
2023-07-01 22780.933 22491.30 289.6297 1209.512
2023-10-01 22960.600 22854.84 105.7633 1000.212
2024-01-01 23053.545 22906.13 147.4141 1149.695
2024-04-01 23223.906 22945.76 278.1487 1304.684
2024-07-01 23400.294 23097.46 302.8325 1333.510
2024-10-01 23542.349 23250.78 291.5648 1292.890
2025-01-01 23512.717 23400.15 112.5672 1109.282
2025-04-01 23685.287 23547.13 138.1532 1145.869# パッケージの読み込み
library(dplyr)
library(ggplot2)
# 3. 可視化用データフレームの構築
df_hamilton_filtered <- data.frame(
Date = index(hamilton_filtered),
coredata(hamilton_filtered)
) %>% tidyr::gather(, , colnames(.)[-1])
df_hamilton_filtered$key <- df_hamilton_filtered$key %>% factor(levels = unique(.))
# 4. 可視化プロットの作成
p <- ggplot(df_hamilton_filtered, mapping = aes(x = Date, y = value)) +
geom_line() +
facet_wrap(. ~ key, scales = "free_y") +
theme_minimal() +
theme(axis.title = element_blank()) +
labs(title = "関数 yth_filter の結果")
print(p)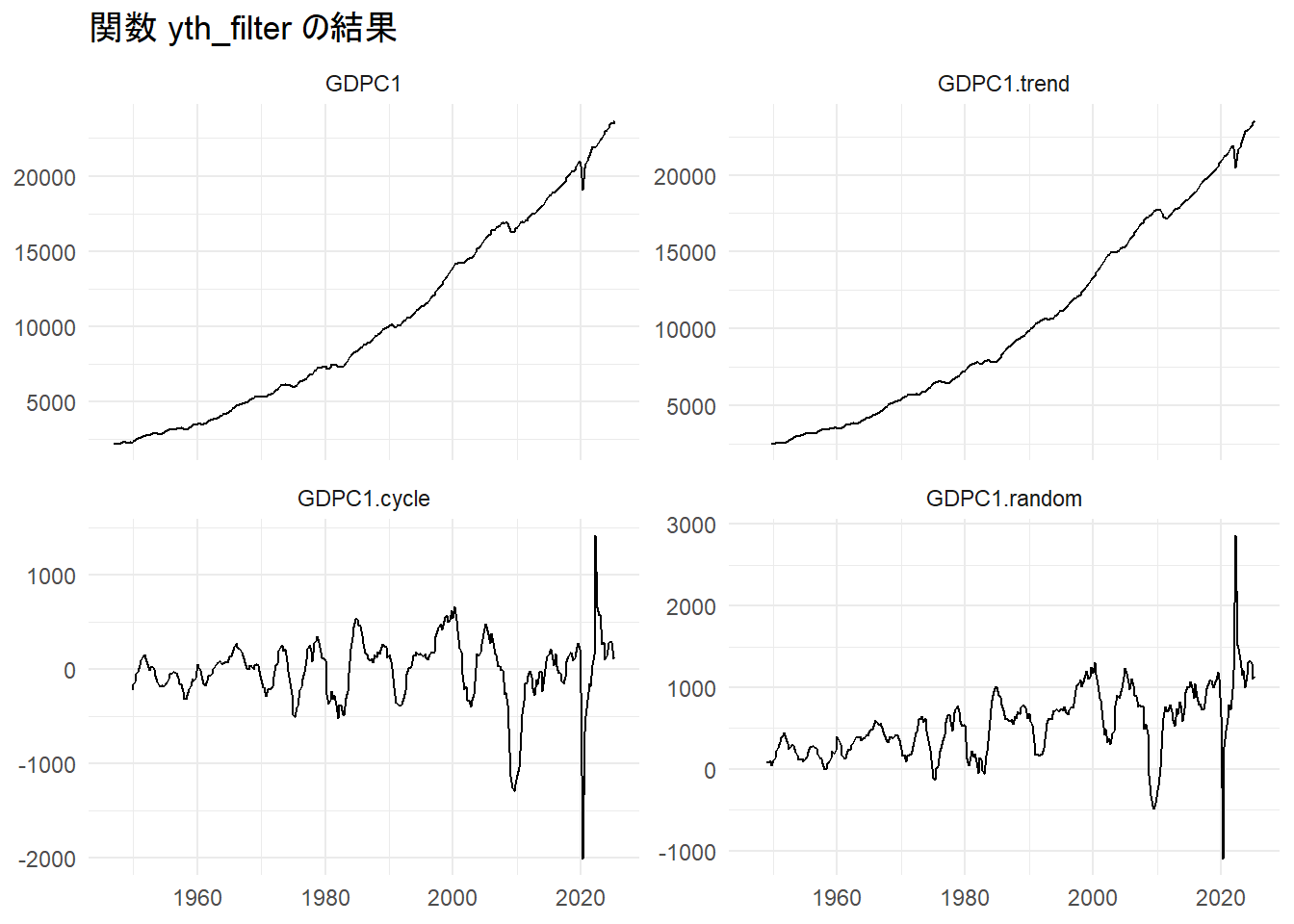
Figure 1 の通り、トレンド成分、サイクル成分およびランダム成分が返されます。
ランダム成分とは
yth_filter 関数から出力される random という成分は、一般的な時系列分解(decompose 関数など)で呼ばれる「ランダム成分(=モデルで説明できないホワイトノイズ・残差)」とは全く意味が異なります。
ソースコードを確認しますと、random は以下の計算式で定義されています。
random <- x - lag(x, k = h, na.pad = TRUE)本コードが示している通り、random の値は「現在の値から、\(h\) 期前(デフォルトでは \(h=8\)、つまり四半期データの場合は2年前)の値を単に引き算したもの」に過ぎません。
例えば、GDP四半期データで \(h=8\) とした場合、「今期のGDPから、ちょうど2年前のGDPを引いた単純な増減幅」が random として出力されます。ここには、回帰分析や平滑化といった統計処理は一切含まれていません。
スクラッチコード
ハミルトンフィルターは、時点 \(t\) のデータ \(y_t\) を、「\(h\) 期前の時点からさらに \(p\) 期分遡った過去のデータ」 を用いて回帰(OLS: 最小二乗法)することでトレンドを予測します。
\[ y_t = \beta_0 + \beta_1 y_{t-h} + \beta_2 y_{t-h-1} + \dots + \beta_p y_{t-h-p+1} + v_t \]
- トレンド成分: 本回帰式による予測値 \(\hat{y}_t\)
- サイクル成分: 本回帰式の予測誤差(残差) \(\hat{v}_t = y_t - \hat{y}_t\)
# 1. スクラッチ関数の定義
hamilton_filter_scratch <- function(x, h = 8, p = 4) {
# 入力データを数値ベクトルに変換
x_num <- as.numeric(x)
n <- length(x_num)
# ① 説明変数行列 (X) の構築
# 過去 p 期分(t-h, t-h-1, ..., t-h-p+1)のラグ変数を作成します
X <- matrix(NA, nrow = n, ncol = p)
for (i in 1:p) {
lag_val <- h + i - 1
if (lag_val < n) {
# データを lag_val 期だけ右(未来方向)にずらして格納
X[(lag_val + 1):n, i] <- x_num[1:(n - lag_val)]
}
}
# 定数項 (切片) を説明変数の1列目に追加
X_full <- cbind(1, X)
# ② OLS (最小二乗法) による回帰係数の推定
# 欠損値 (NA) を含まない有効な期間のみを抽出して計算します
valid_idx <- complete.cases(X_full) & !is.na(x_num)
Y_valid <- x_num[valid_idx]
X_valid <- X_full[valid_idx, , drop = FALSE]
# 正規方程式: beta = (X'X)^(-1) X'Y
beta_hat <- solve(t(X_valid) %*% X_valid) %*% t(X_valid) %*% Y_valid
# ③ トレンド成分とサイクル成分の計算
# 推定された係数を用いて、全期間(欠損を含む)の予測値を算出します
trend_component <- as.numeric(X_full %*% beta_hat)
# サイクル成分 = 実測値 - 予測値 (残差)
cycle_component <- x_num - trend_component
return(list(
trend = trend_component,
cycle = cycle_component,
beta = as.numeric(beta_hat)
))
}
# 2. フィルタの実行と結果の比較
# 手法A: neverhpfilter::yth_filter
res_pkg <- yth_filter(GDPC1, h = 8, p = 4)
pkg_trend <- as.numeric(res_pkg$GDPC1.trend)
pkg_cycle <- as.numeric(res_pkg$GDPC1.cycle)
# 手法B: スクラッチ実装
res_scratch <- hamilton_filter_scratch(GDPC1, h = 8, p = 4)
scr_trend <- res_scratch$trend
scr_cycle <- res_scratch$cycle
cat("--- 関数yth_filterの結果とスクラッチ関数の結果は一致しているか ---\n")
cat(paste0("トレンド成分: ", all.equal(pkg_trend, scr_trend)))
cat(paste0("\nサイクル成分: ", all.equal(pkg_cycle, scr_cycle)))--- 関数yth_filterの結果とスクラッチ関数の結果は一致しているか ---
トレンド成分: TRUE
サイクル成分: TRUE以上です。

